 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDH-RAG: A Dynamic Historical Context-Powered Retrieval-Augmented Generation Method for Multi-Turn Dialogue
Feb 19, 2025Retrieval-Augmented Generation (RAG) systems have shown substantial benefits in applications such as question answering and multi-turn dialogue \citep{lewis2020retrieval}. However, traditional RAG methods, while leveraging static knowledge bases, often overlook the potential of dynamic historical information in ongoing conversations. To bridge this gap, we introduce DH-RAG, a Dynamic Historical Context-Powered Retrieval-Augmented Generation Method for Multi-Turn Dialogue. DH-RAG is inspired by human cognitive processes that utilize both long-term memory and immediate historical context in conversational responses \citep{stafford1987conversational}. DH-RAG is structured around two principal components: a History-Learning based Query Reconstruction Module, designed to generate effective queries by synthesizing current and prior interactions, and a Dynamic History Information Updating Module, which continually refreshes historical context throughout the dialogue. The center of DH-RAG is a Dynamic Historical Information database, which is further refined by three strategies within the Query Reconstruction Module: Historical Query Clustering, Hierarchical Matching, and Chain of Thought Tracking. Experimental evaluations show that DH-RAG significantly surpasses conventional models on several benchmarks, enhancing response relevance, coherence, and dialogue quality.
mFabric: An Efficient and Scalable Fabric for Mixture-of-Experts Training
Jan 07, 2025



Mixture-of-Expert (MoE) models outperform conventional models by selectively activating different subnets, named \emph{experts}, on a per-token basis. This gated computation generates dynamic communications that cannot be determined beforehand, challenging the existing GPU interconnects that remain \emph{static} during the distributed training process. In this paper, we advocate for a first-of-its-kind system, called mFabric, that unlocks topology reconfiguration \emph{during} distributed MoE training. Towards this vision, we first perform a production measurement study and show that the MoE dynamic communication pattern has \emph{strong locality}, alleviating the requirement of global reconfiguration. Based on this, we design and implement a \emph{regionally reconfigurable high-bandwidth domain} on top of existing electrical interconnects using optical circuit switching (OCS), achieving scalability while maintaining rapid adaptability. We have built a fully functional mFabric prototype with commodity hardware and a customized collective communication runtime that trains state-of-the-art MoE models with \emph{in-training} topology reconfiguration across 32 A100 GPUs. Large-scale packet-level simulations show that mFabric delivers comparable performance as the non-blocking fat-tree fabric while boosting the training cost efficiency (e.g., performance per dollar) of four representative MoE models by 1.2$\times$--1.5$\times$ and 1.9$\times$--2.3$\times$ at 100 Gbps and 400 Gbps link bandwidths, respectively.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Exploiting Student Parallelism for Low-latency GPU Inference of BERT-like Models in Online Services
Aug 22, 2024


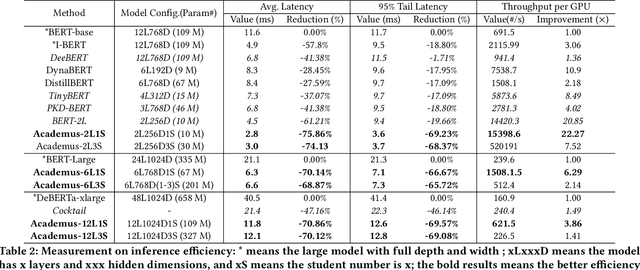
Due to high accuracy, BERT-like models have been widely adopted by discriminative text mining and web searching. However, large BERT-like models suffer from inefficient online inference, as they face the following two problems on GPUs. First, they rely on the large model depth to achieve high accuracy, which linearly increases the sequential computation on GPUs. Second, stochastic and dynamic online workloads cause extra costs. In this paper, we present Academus for low-latency online inference of BERT-like models. At the core of Academus is the novel student parallelism, which adopts boosting ensemble and stacking distillation to distill the original deep model into an equivalent group of parallel and shallow student models. This enables Academus to achieve the lower model depth (e.g., two layers) than baselines and consequently the lowest inference latency without affecting the accuracy.For occasional workload bursts, it can temporarily decrease the number of students with minimal accuracy loss to improve throughput. Additionally, it employs specialized system designs for student parallelism to better handle stochastic online workloads. We conduct comprehensive experiments to verify the effectiveness. The results show that Academus outperforms the baselines by 4.1X~1.6X in latency without compromising accuracy, and achieves up to 22.27X higher throughput for workload bursts.
PackVFL: Efficient HE Packing for Vertical Federated Learning
May 01, 2024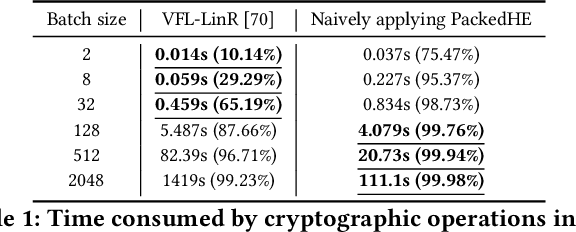
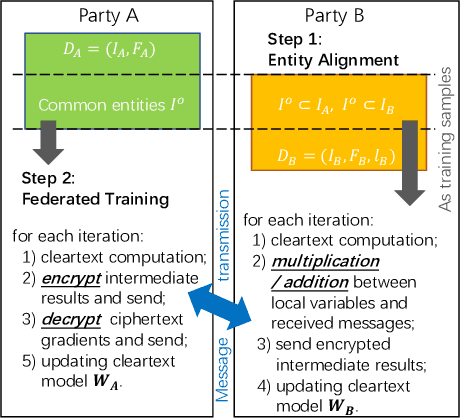
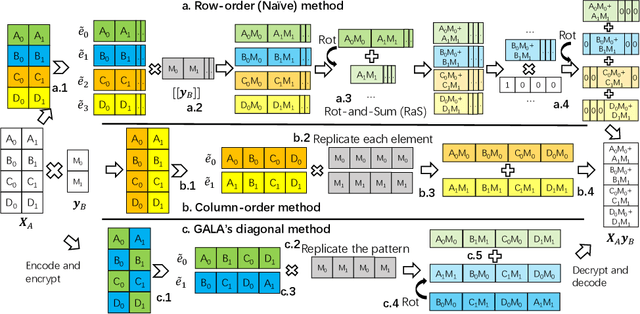

As an essential tool of secure distributed machine learning, vertical federated learning (VFL) based on homomorphic encryption (HE) suffers from severe efficiency problems due to data inflation and time-consuming operations. To this core, we propose PackVFL, an efficient VFL framework based on packed HE (PackedHE), to accelerate the existing HE-based VFL algorithms. PackVFL packs multiple cleartexts into one ciphertext and supports single-instruction-multiple-data (SIMD)-style parallelism. We focus on designing a high-performant matrix multiplication (MatMult) method since it takes up most of the ciphertext computation time in HE-based VFL. Besides, devising the MatMult method is also challenging for PackedHE because a slight difference in the packing way could predominantly affect its computation and communication costs. Without domain-specific design, directly applying SOTA MatMult methods is hard to achieve optimal. Therefore, we make a three-fold design: 1) we systematically explore the current design space of MatMult and quantify the complexity of existing approaches to provide guidance; 2) we propose a hybrid MatMult method according to the unique characteristics of VFL; 3) we adaptively apply our hybrid method in representative VFL algorithms, leveraging distinctive algorithmic properties to further improve efficiency. As the batch size, feature dimension and model size of VFL scale up to large sizes, PackVFL consistently delivers enhanced performance. Empirically, PackVFL propels existing VFL algorithms to new heights, achieving up to a 51.52X end-to-end speedup. This represents a substantial 34.51X greater speedup compared to the direct application of SOTA MatMult methods.
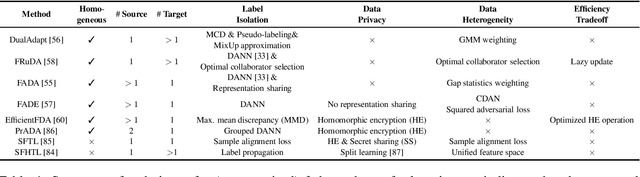
A Survey on Vertical Federated Learning: From a Layered Perspective
Apr 04, 2023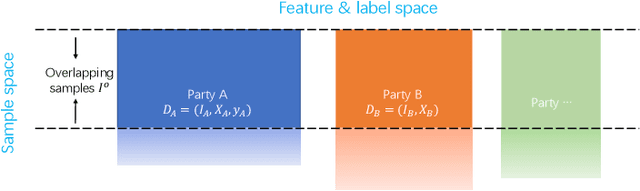

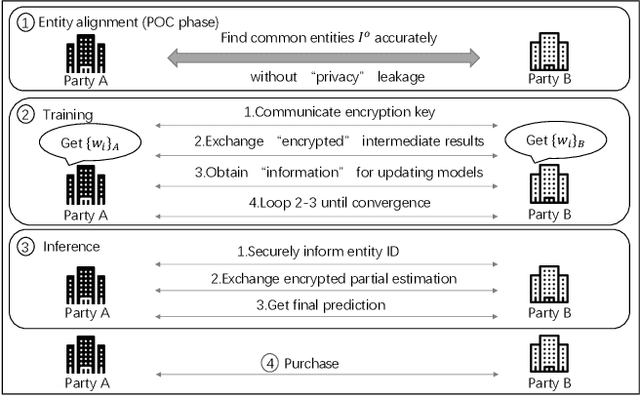
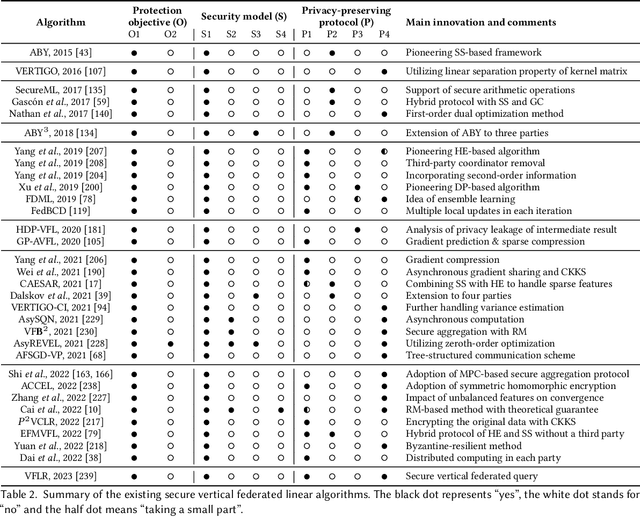
Vertical federated learning (VFL) is a promising category of federated learning for the scenario where data is vertically partitioned and distributed among parties. VFL enriches the description of samples using features from different parties to improve model capacity. Compared with horizontal federated learning, in most cases, VFL is applied in the commercial cooperation scenario of companies. Therefore, VFL contains tremendous business values. In the past few years, VFL has attracted more and more attention in both academia and industry. In this paper, we systematically investigate the current work of VFL from a layered perspective. From the hardware layer to the vertical federated system layer, researchers contribute to various aspects of VFL. Moreover, the application of VFL has covered a wide range of areas, e.g., finance, healthcare, etc. At each layer, we categorize the existing work and explore the challenges for the convenience of further research and development of VFL. Especially, we design a novel MOSP tree taxonomy to analyze the core component of VFL, i.e., secure vertical federated machine learning algorithm. Our taxonomy considers four dimensions, i.e., machine learning model (M), protection object (O), security model (S), and privacy-preserving protocol (P), and provides a comprehensive investigation.
Federated Learning without Full Labels: A Survey
Mar 25, 2023
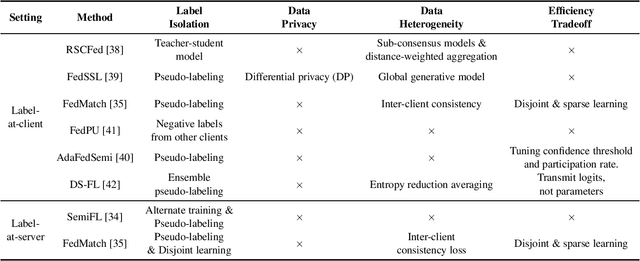

Data privacy has become an increasingly important concern in real-world big data applications such as machine learning. To address the problem, federated learning (FL) has been a promising solution to building effective machine learning models from decentralized and private data. Existing federated learning algorithms mainly tackle the supervised learning problem, where data are assumed to be fully labeled. However, in practice, fully labeled data is often hard to obtain, as the participants may not have sufficient domain expertise, or they lack the motivation and tools to label data. Therefore, the problem of federated learning without full labels is important in real-world FL applications. In this paper, we discuss how the problem can be solved with machine learning techniques that leverage unlabeled data. We present a survey of methods that combine FL with semi-supervised learning, self-supervised learning, and transfer learning methods. We also summarize the datasets used to evaluate FL methods without full labels. Finally, we highlight future directions in the context of FL without full labels.
Secure Forward Aggregation for Vertical Federated Neural Networks
Jun 28, 2022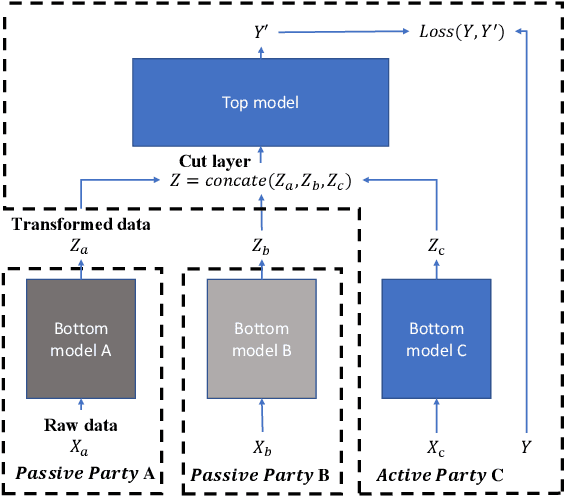


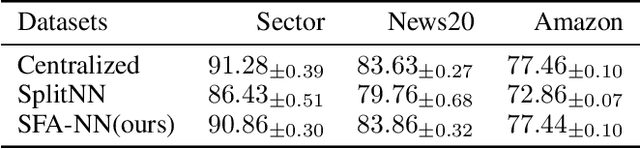
Vertical federated learning (VFL) is attracting much attention because it enables cross-silo data cooperation in a privacy-preserving manner. While most research works in VFL focus on linear and tree models, deep models (e.g., neural networks) are not well studied in VFL. In this paper, we focus on SplitNN, a well-known neural network framework in VFL, and identify a trade-off between data security and model performance in SplitNN. Briefly, SplitNN trains the model by exchanging gradients and transformed data. On the one hand, SplitNN suffers from the loss of model performance since multiply parties jointly train the model using transformed data instead of raw data, and a large amount of low-level feature information is discarded. On the other hand, a naive solution of increasing the model performance through aggregating at lower layers in SplitNN (i.e., the data is less transformed and more low-level feature is preserved) makes raw data vulnerable to inference attacks. To mitigate the above trade-off, we propose a new neural network protocol in VFL called Security Forward Aggregation (SFA). It changes the way of aggregating the transformed data and adopts removable masks to protect the raw data. Experiment results show that networks with SFA achieve both data security and high model performance.
CityNet: A Multi-city Multi-modal Dataset for Smart City Applications
Jun 30, 2021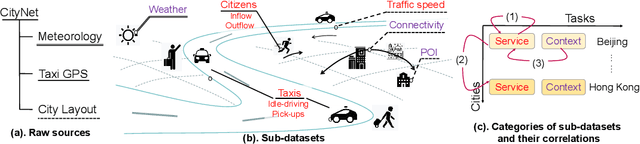
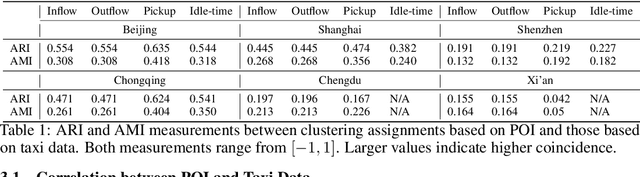
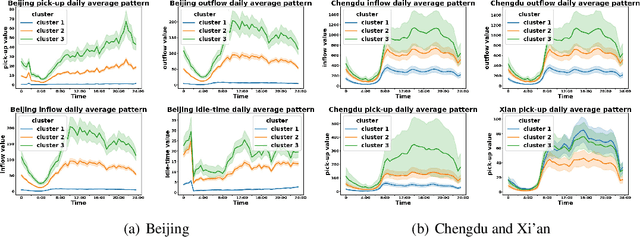
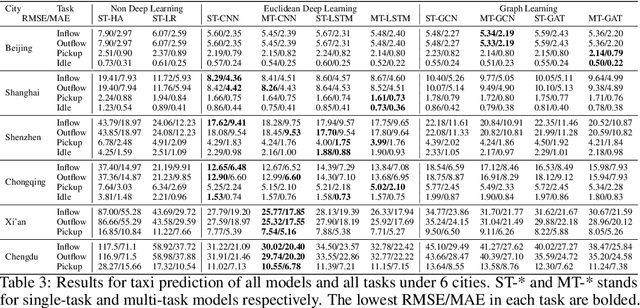
Data-driven approaches have been applied to many problems in urban computing. However, in the research community, such approaches are commonly studied under data from limited sources, and are thus unable to characterize the complexity of urban data coming from multiple entities and the correlations among them. Consequently, an inclusive and multifaceted dataset is necessary to facilitate more extensive studies on urban computing. In this paper, we present CityNet, a multi-modal urban dataset containing data from 7 cities, each of which coming from 3 data sources. We first present the generation process of CityNet as well as its basic properties. In addition, to facilitate the use of CityNet, we carry out extensive machine learning experiments, including spatio-temporal predictions, transfer learning, and reinforcement learning. The experimental results not only provide benchmarks for a wide range of tasks and methods, but also uncover internal correlations among cities and tasks within CityNet that, with adequate leverage, can improve performances on various tasks. With the benchmarking results and the correlations uncovered, we believe that CityNet can contribute to the field of urban computing by supporting research on many advanced topics.
Theoretically Improving Graph Neural Networks via Anonymous Walk Graph Kernels
Apr 07, 2021Graph neural networks (GNNs) have achieved tremendous success in graph mining. However, the inability of GNNs to model substructures in graphs remains a significant drawback. Specifically, message-passing GNNs (MPGNNs), as the prevailing type of GNNs, have been theoretically shown unable to distinguish, detect or count many graph substructures. While efforts have been paid to complement the inability, existing works either rely on pre-defined substructure sets, thus being less flexible, or are lacking in theoretical insights. In this paper, we propose GSKN, a GNN model with a theoretically stronger ability to distinguish graph structures. Specifically, we design GSKN based on anonymous walks (AWs), flexible substructure units, and derive it upon feature mappings of graph kernels (GKs). We theoretically show that GSKN provably extends the 1-WL test, and hence the maximally powerful MPGNNs from both graph-level and node-level viewpoints. Correspondingly, various experiments are leveraged to evaluate GSKN, where GSKN outperforms a wide range of baselines, endorsing the analysis.