 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Noise-Aware Training of Layout-Aware Language Models
Mar 30, 2024



A visually rich document (VRD) utilizes visual features along with linguistic cues to disseminate information. Training a custom extractor that identifies named entities from a document requires a large number of instances of the target document type annotated at textual and visual modalities. This is an expensive bottleneck in enterprise scenarios, where we want to train custom extractors for thousands of different document types in a scalable way. Pre-training an extractor model on unlabeled instances of the target document type, followed by a fine-tuning step on human-labeled instances does not work in these scenarios, as it surpasses the maximum allowable training time allocated for the extractor. We address this scenario by proposing a Noise-Aware Training method or NAT in this paper. Instead of acquiring expensive human-labeled documents, NAT utilizes weakly labeled documents to train an extractor in a scalable way. To avoid degradation in the model's quality due to noisy, weakly labeled samples, NAT estimates the confidence of each training sample and incorporates it as uncertainty measure during training. We train multiple state-of-the-art extractor models using NAT. Experiments on a number of publicly available and in-house datasets show that NAT-trained models are not only robust in performance -- it outperforms a transfer-learning baseline by up to 6% in terms of macro-F1 score, but it is also more label-efficient -- it reduces the amount of human-effort required to obtain comparable performance by up to 73%.
Cross-Modal Entity Matching for Visually Rich Documents
Mar 01, 2023Visually rich documents (VRD) are physical/digital documents that utilize visual cues to augment their semantics. The information contained in these documents are often incomplete. Existing works that enable automated querying on VRDs do not take this aspect into account. Consequently, they support a limited set of queries. In this paper, we describe Juno -- a multimodal framework that identifies a set of tuples from a relational database to augment an incomplete VRD with supplementary information. Our main contribution in this is an end-to-end-trainable neural network with bi-directional attention that executes this cross-modal entity matching task without any prior knowledge about the document type or the underlying database-schema. Exhaustive experiments on two heteroegeneous datasets show that Juno outperforms state-of-the-art baselines by more than 6% in F1-score, while reducing the amount of human-effort in its workflow by more than 80%. To the best of our knowledge, ours is the first work that investigates the incompleteness of VRDs and proposes a robust framework to address it in a seamless way.
Label-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Aug 27, 2022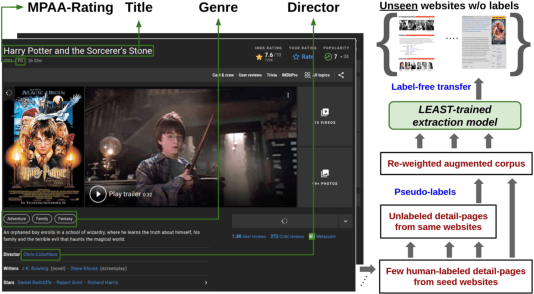

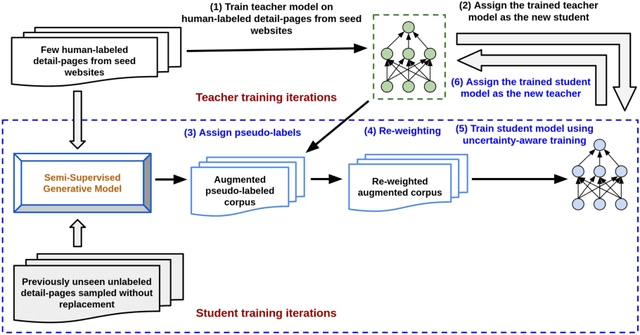
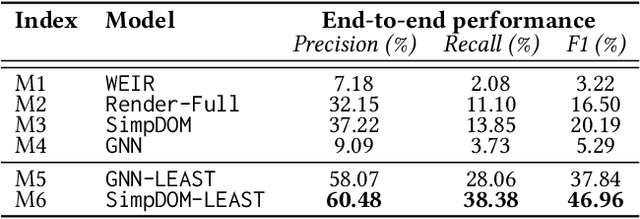
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.
A Skip-connected Multi-column Network for Isolated Handwritten Bangla Character and Digit recognition
Apr 27, 2020
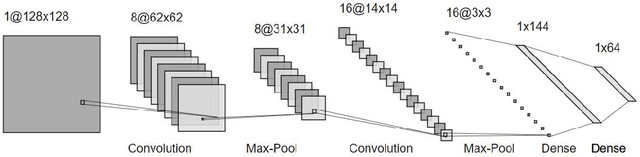

Finding local invariant patterns in handwrit-ten characters and/or digits for optical character recognition is a difficult task. Variations in writing styles from one person to another make this task challenging. We have proposed a non-explicit feature extraction method using a multi-scale multi-column skip convolutional neural network in this work. Local and global features extracted from different layers of the proposed architecture are combined to derive the final feature descriptor encoding a character or digit image. Our method is evaluated on four publicly available datasets of isolated handwritten Bangla characters and digits. Exhaustive comparative analysis against contemporary methods establishes the efficacy of our proposed approach.
Transfer Learning for Abstractive Summarization at Controllable Budgets
Feb 18, 2020
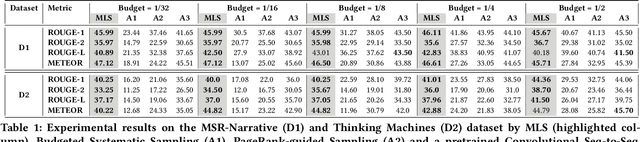
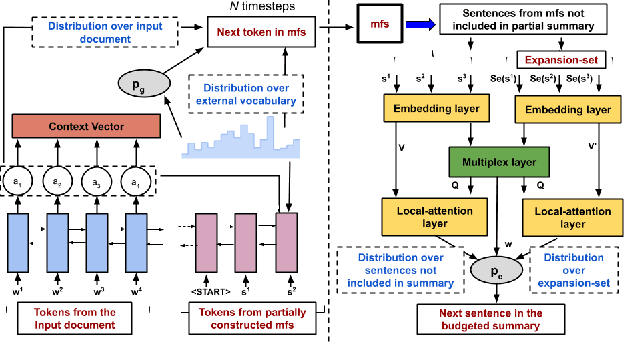
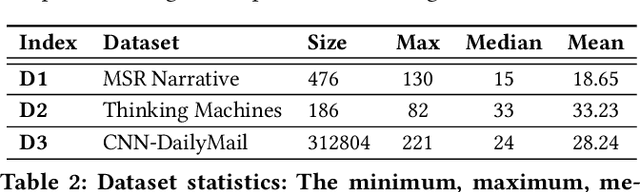
Summarizing a document within an allocated budget while maintaining its major concepts is a challenging task. If the budget can take any arbitrary value and not known beforehand, it becomes even more difficult. Most of the existing methods for abstractive summarization, including state-of-the-art neural networks are data intensive. If the number of available training samples becomes limited, they fail to construct high-quality summaries. We propose MLS, an end-to-end framework to generate abstractive summaries with limited training data at arbitrary compression budgets. MLS employs a pair of supervised sequence-to-sequence networks. The first network called the \textit{MFS-Net} constructs a minimal feasible summary by identifying the key concepts of the input document. The second network called the Pointer-Magnifier then generates the final summary from the minimal feasible summary by leveraging an interpretable multi-headed attention model. Experiments on two cross-domain datasets show that MLS outperforms baseline methods over a range of success metrics including ROUGE and METEOR. We observed an improvement of approximately 4% in both metrics over the state-of-art convolutional network at lower budgets. Results from a human evaluation study also establish the effectiveness of MLS in generating complete coherent summaries at arbitrary compression budgets.
A Genetic Algorithm based Kernel-size Selection Approach for a Multi-column Convolutional Neural Network
Dec 28, 2019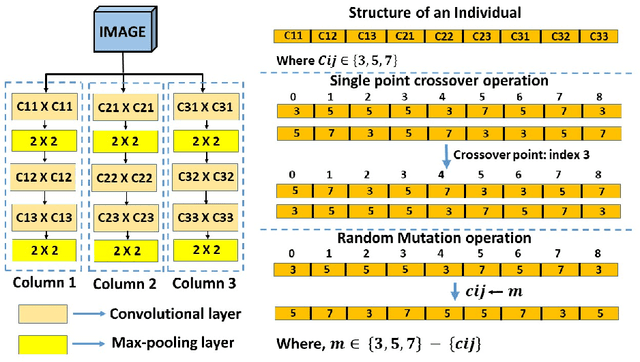
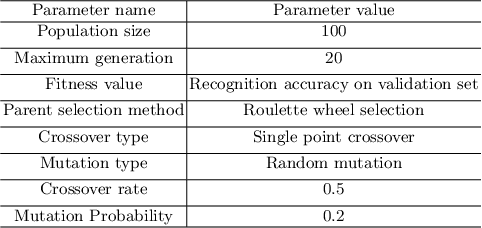
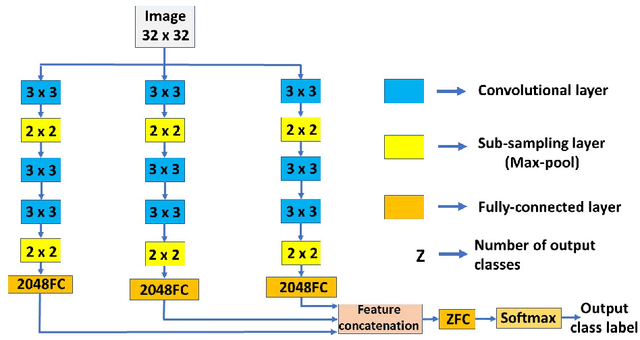
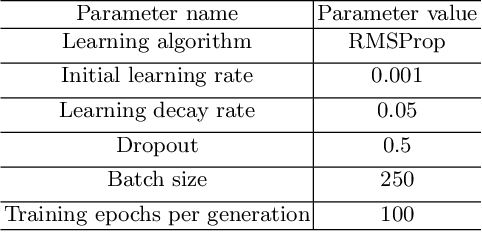
Deep neural network-based architectures give promising results in various domains including \textit{pattern recognition}. Finding the optimal combination of the hyper-parameters of such a large-sized architecture is tedious and requires a large number of laboratory experiments. But, identifying the optimal combination of a hyper-parameter or appropriate kernel size for a given architecture of deep learning is always a challenging and tedious task. Here, we introduced a genetic algorithm-based technique to reduce the efforts of finding the optimal combination of a hyper-parameter (kernel size) of a convolutional neural network-based architecture. The method is evaluated on three popular datasets of different handwritten Bangla characters and digits.
Using dynamic routing to extract intermediate features for developing scalable capsule networks
Jul 13, 2019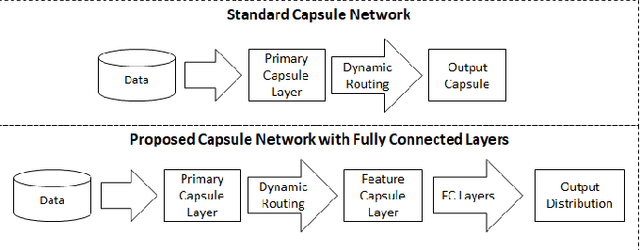
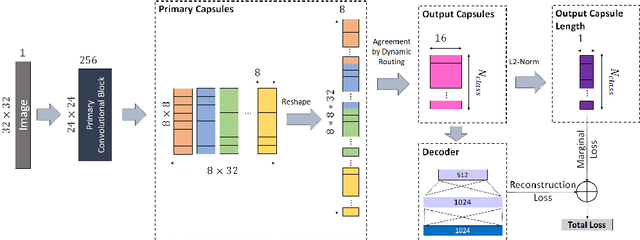
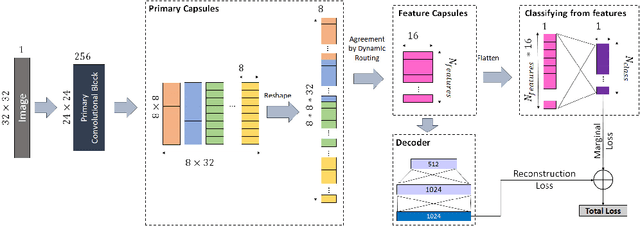
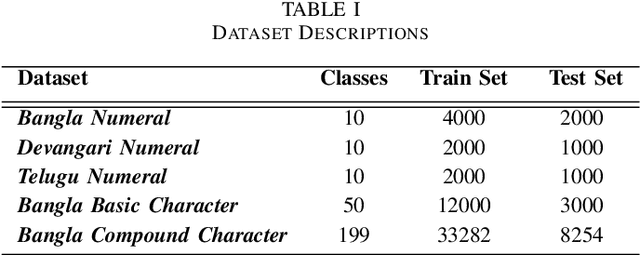
Capsule networks have gained a lot of popularity in short time due to its unique approach to model equivariant class specific properties as capsules from images. However the dynamic routing algorithm comes with a steep computational complexity. In the proposed approach we aim to create scalable versions of the capsule networks that are much faster and provide better accuracy in problems with higher number of classes. By using dynamic routing to extract intermediate features instead of generating output class specific capsules, a large increase in the computational speed has been observed. Moreover, by extracting equivariant feature capsules instead of class specific capsules, the generalization capability of the network has also increased as a result of which there is a boost in accuracy.
Handwritten Indic Character Recognition using Capsule Networks
Jan 01, 2019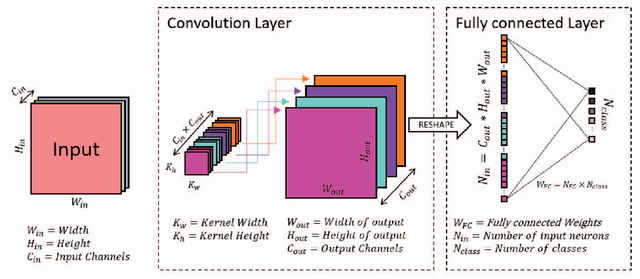
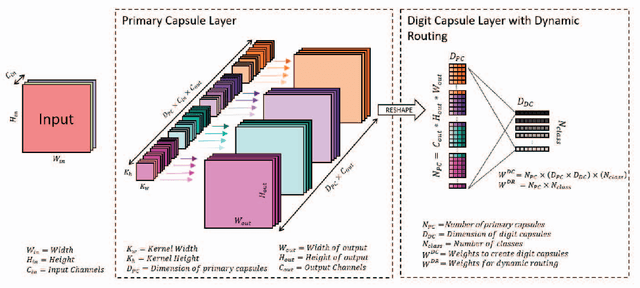
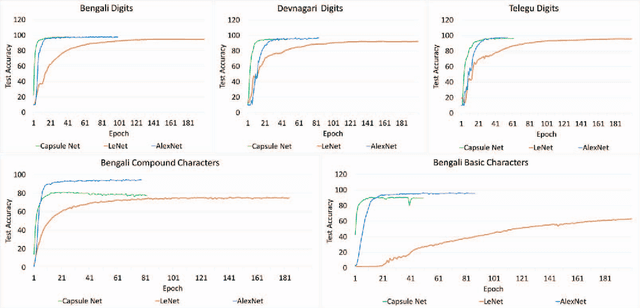

Convolutional neural networks(CNNs) has become one of the primary algorithms for various computer vision tasks. Handwritten character recognition is a typical example of such task that has also attracted attention. CNN architectures such as LeNet and AlexNet have become very prominent over the last two decades however the spatial invariance of the different kernels has been a prominent issue till now. With the introduction of capsule networks, kernels can work together in consensus with one another with the help of dynamic routing, that combines individual opinions of multiple groups of kernels called capsules to employ equivariance among kernels. In the current work, we have implemented capsule network on handwritten Indic digits and character datasets to show its superiority over networks like LeNet. Furthermore, it has also been shown that they can boost the performance of other networks like LeNet and AlexNet.