 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Based Hand Geometry Recognition Using Dempster-Shafer Theory
Oct 13, 2024



This paper presents a new technique for person recognition based on the fusion of hand geometric features of both the hands without any pose restrictions. All the features are extracted from normalized left and right hand images. Fusion is applied at feature level and also at decision level. Two probability based algorithms are proposed for classification. The first algorithm computes the maximum probability for nearest three neighbors. The second algorithm determines the maximum probability of the number of matched features with respect to a thresholding on distances. Based on these two highest probabilities initial decisions are made. The final decision is considered according to the highest probability as calculated by the Dempster-Shafer theory of evidence. Depending on the various combinations of the initial decisions, three schemes are experimented with 201 subjects for identification and verification. The correct identification rate found to be 99.5%, and the False Acceptance Rate (FAR) of 0.625% has been found during verification.
Regularizing CNNs using Confusion Penalty Based Label Smoothing for Histopathology Images
Mar 16, 2024



Deep Learning, particularly Convolutional Neural Networks (CNN), has been successful in computer vision tasks and medical image analysis. However, modern CNNs can be overconfident, making them difficult to deploy in real-world scenarios. Researchers propose regularizing techniques, such as Label Smoothing (LS), which introduces soft labels for training data, making the classifier more regularized. LS captures disagreements or lack of confidence in the training phase, making the classifier more regularized. Although LS is quite simple and effective, traditional LS techniques utilize a weighted average between target distribution and a uniform distribution across the classes, which limits the objective of LS as well as the performance. This paper introduces a novel LS technique based on the confusion penalty, which treats model confusion for each class with more importance than others. We have performed extensive experiments with well-known CNN architectures with this technique on publicly available Colorectal Histology datasets and got satisfactory results. Also, we have compared our findings with the State-of-the-art and shown our method's efficacy with Reliability diagrams and t-distributed Stochastic Neighbor Embedding (t-SNE) plots of feature space.
COVID-CT-H-UNet: a novel COVID-19 CT segmentation network based on attention mechanism and Bi-category Hybrid loss
Mar 16, 2024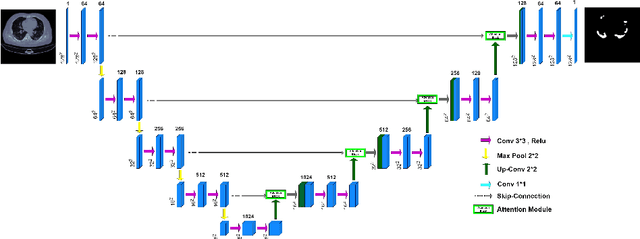

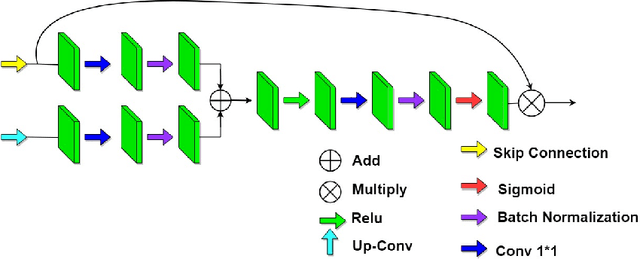

Since 2019, the global COVID-19 outbreak has emerged as a crucial focus in healthcare research. Although RT-PCR stands as the primary method for COVID-19 detection, its extended detection time poses a significant challenge. Consequently, supplementing RT-PCR with the pathological study of COVID-19 through CT imaging has become imperative. The current segmentation approach based on TVLoss enhances the connectivity of afflicted areas. Nevertheless, it tends to misclassify normal pixels between certain adjacent diseased regions as diseased pixels. The typical Binary cross entropy(BCE) based U-shaped network only concentrates on the entire CT images without emphasizing on the affected regions, which results in hazy borders and low contrast in the projected output. In addition, the fraction of infected pixels in CT images is much less, which makes it a challenge for segmentation models to make accurate predictions. In this paper, we propose COVID-CT-H-UNet, a COVID-19 CT segmentation network to solve these problems. To recognize the unaffected pixels between neighbouring diseased regions, extra visual layer information is captured by combining the attention module on the skip connections with the proposed composite function Bi-category Hybrid Loss. The issue of hazy boundaries and poor contrast brought on by the BCE Loss in conventional techniques is resolved by utilizing the composite function Bi-category Hybrid Loss that concentrates on the pixels in the diseased area. The experiment shows when compared to the previous COVID-19 segmentation networks, the proposed COVID-CT-H-UNet's segmentation impact has greatly improved, and it may be used to identify and study clinical COVID-19.
Hand Biometrics in Digital Forensics
Feb 17, 2024Digital forensic is now an unavoidable part for securing the digital world from identity theft. Higher order of crimes, dealing with a massive database is really very challenging problem for any intelligent system. Biometric is a better solution to win over the problems encountered by digital forensics. Many biometric characteristics are playing their significant roles in forensics over the decades. The potential benefits and scope of hand based modes in forensics have been investigated with an illustration of hand geometry verifi-cation method. It can be applied when effective biometric evidences are properly unavailable; gloves are damaged, and dirt or any kind of liquid can minimize the accessibility and reliability of the fingerprint or palmprint. Due to the crisis of pure uniqueness of hand features for a very large database, it may be relevant for verification only. Some unimodal and multimodal hand based biometrics (e.g. hand geometry, palmprint and hand vein) with several feature extractions, database and verification methods have been discussed with 2D, 3D and infrared images.
Finger Biometric Recognition With Feature Selection
Dec 19, 2023Biometrics is indispensable in this modern digital era for secure automated human authentication in various fields of machine learning and pattern recognition. Hand geometry is a promising physiological biometric trait with ample deployed application areas for identity verification. Due to the intricate anatomic foundation of the thumb and substantial inter-finger posture variation, satisfactory performances cannot be achieved while the thumb is included in the contact-free environment. To overcome the hindrances associated with the thumb, four finger-based (excluding the thumb) biometric approaches have been devised. In this chapter, a four-finger based biometric method has been presented. Again, selection of salient features is essential to reduce the feature dimensionality by eliminating the insignificant features. Weights are assigned according to the discriminative efficiency of the features to emphasize on the essential features. Two different strategies namely, the global and local feature selection methods are adopted based on the adaptive forward-selection and backward-elimination (FoBa) algorithm. The identification performances are evaluated using the weighted k-nearest neighbor (wk-NN) and random forest (RF) classifiers. The experiments are conducted using the selected feature subsets over the 300 subjects of the Bosphorus hand database. The best identification accuracy of 98.67%, and equal error rate (EER) of 4.6% have been achieved using the subset of 25 features which are selected by the rank-based local FoBa algorithm.
Deep Neural Networks Fused with Textures for Image Classification
Aug 03, 2023Fine-grained image classification (FGIC) is a challenging task in computer vision for due to small visual differences among inter-subcategories, but, large intra-class variations. Deep learning methods have achieved remarkable success in solving FGIC. In this paper, we propose a fusion approach to address FGIC by combining global texture with local patch-based information. The first pipeline extracts deep features from various fixed-size non-overlapping patches and encodes features by sequential modelling using the long short-term memory (LSTM). Another path computes image-level textures at multiple scales using the local binary patterns (LBP). The advantages of both streams are integrated to represent an efficient feature vector for image classification. The method is tested on eight datasets representing the human faces, skin lesions, food dishes, marine lives, etc. using four standard backbone CNNs. Our method has attained better classification accuracy over existing methods with notable margins.
* 14 pages, 6 figures, 4 tables, conference
Fine-Grained Sports, Yoga, and Dance Postures Recognition: A Benchmark Analysis
Aug 01, 2023



Human body-pose estimation is a complex problem in computer vision. Recent research interests have been widened specifically on the Sports, Yoga, and Dance (SYD) postures for maintaining health conditions. The SYD pose categories are regarded as a fine-grained image classification task due to the complex movement of body parts. Deep Convolutional Neural Networks (CNNs) have attained significantly improved performance in solving various human body-pose estimation problems. Though decent progress has been achieved in yoga postures recognition using deep learning techniques, fine-grained sports, and dance recognition necessitates ample research attention. However, no benchmark public image dataset with sufficient inter-class and intra-class variations is available yet to address sports and dance postures classification. To solve this limitation, we have proposed two image datasets, one for 102 sport categories and another for 12 dance styles. Two public datasets, Yoga-82 which contains 82 classes and Yoga-107 represents 107 classes are collected for yoga postures. These four SYD datasets are experimented with the proposed deep model, SYD-Net, which integrates a patch-based attention (PbA) mechanism on top of standard backbone CNNs. The PbA module leverages the self-attention mechanism that learns contextual information from a set of uniform and multi-scale patches and emphasizes discriminative features to understand the semantic correlation among patches. Moreover, random erasing data augmentation is applied to improve performance. The proposed SYD-Net has achieved state-of-the-art accuracy on Yoga-82 using five base CNNs. SYD-Net's accuracy on other datasets is remarkable, implying its efficiency. Our Sports-102 and Dance-12 datasets are publicly available at https://sites.google.com/view/syd-net/home.
* 12 pages, 12 figures, 10 tables
Variational Augmentation for Enhancing Historical Document Image Binarization
Nov 12, 2022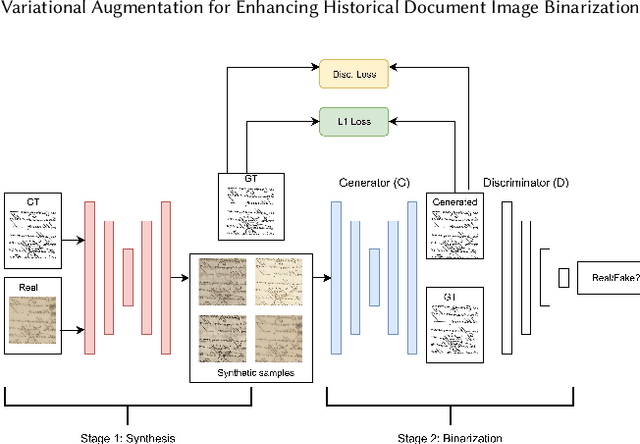
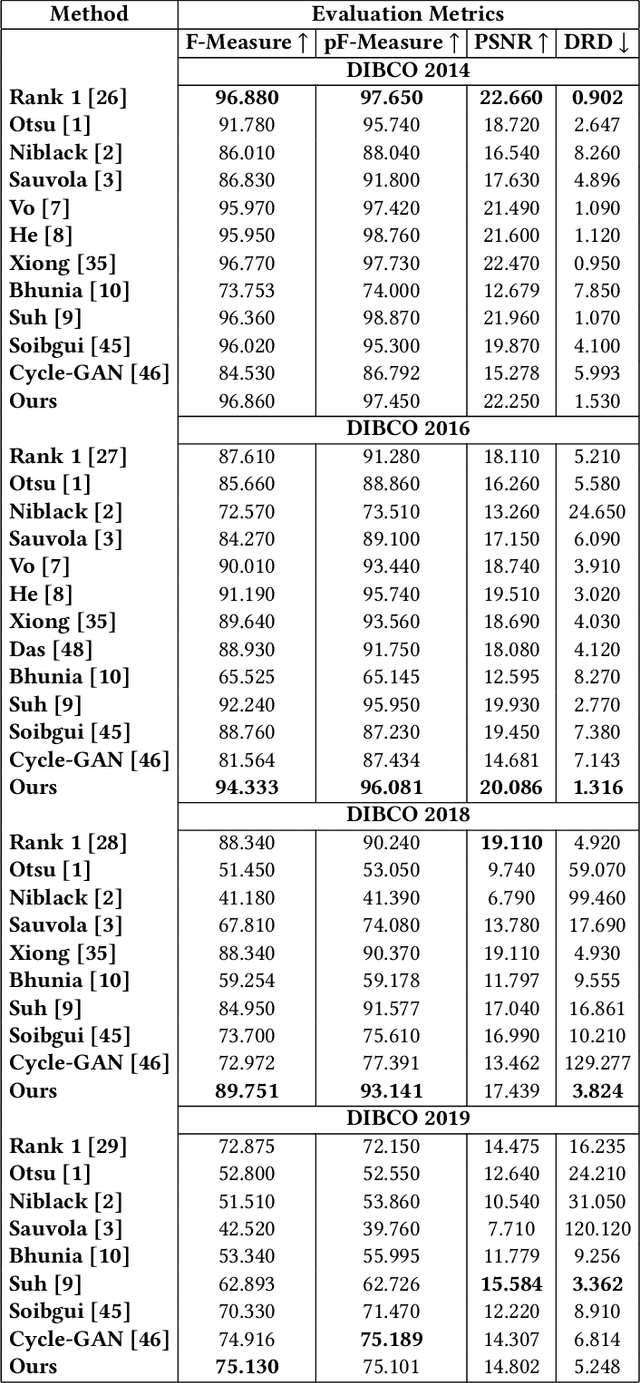
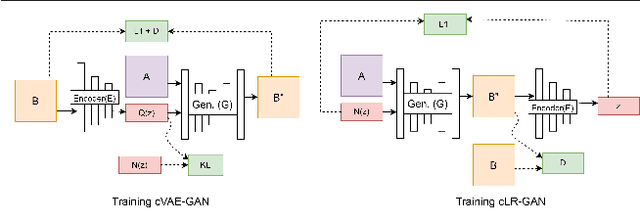
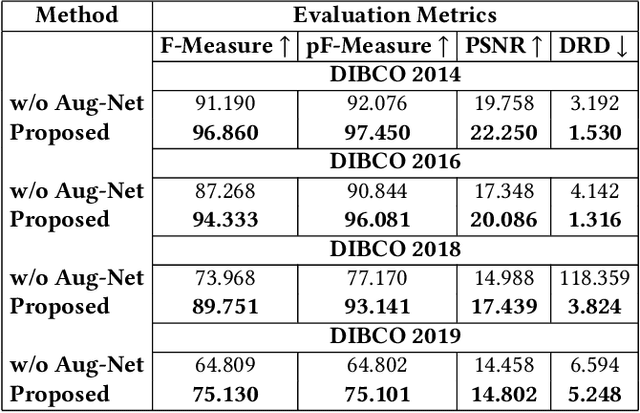
Historical Document Image Binarization is a well-known segmentation problem in image processing. Despite ubiquity, traditional thresholding algorithms achieved limited success on severely degraded document images. With the advent of deep learning, several segmentation models were proposed that made significant progress in the field but were limited by the unavailability of large training datasets. To mitigate this problem, we have proposed a novel two-stage framework -- the first of which comprises a generator that generates degraded samples using variational inference and the second being a CNN-based binarization network that trains on the generated data. We evaluated our framework on a range of DIBCO datasets, where it achieved competitive results against previous state-of-the-art methods.
Spoofing Detection on Hand Images Using Quality Assessment
Oct 22, 2021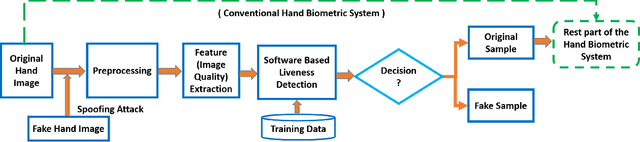
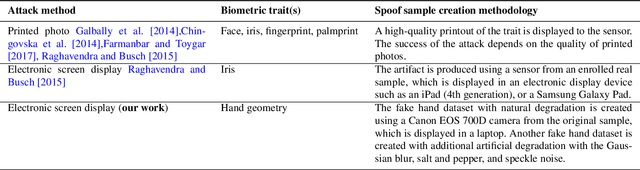
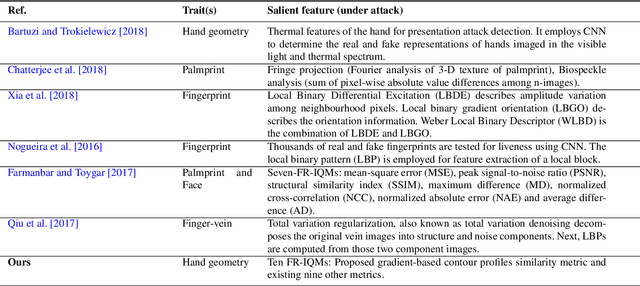

Recent research on biometrics focuses on achieving a high success rate of authentication and addressing the concern of various spoofing attacks. Although hand geometry recognition provides adequate security over unauthorized access, it is susceptible to presentation attack. This paper presents an anti-spoofing method toward hand biometrics. A presentation attack detection approach is addressed by assessing the visual quality of genuine and fake hand images. A threshold-based gradient magnitude similarity quality metric is proposed to discriminate between the real and spoofed hand samples. The visual hand images of 255 subjects from the Bogazici University hand database are considered as original samples. Correspondingly, from each genuine sample, we acquire a forged image using a Canon EOS 700D camera. Such fake hand images with natural degradation are considered for electronic screen display based spoofing attack detection. Furthermore, we create another fake hand dataset with artificial degradation by introducing additional Gaussian blur, salt and pepper, and speckle noises to original images. Ten quality metrics are measured from each sample for classification between original and fake hand image. The classification experiments are performed using the k-nearest neighbors, random forest, and support vector machine classifiers, as well as deep convolutional neural networks. The proposed gradient similarity-based quality metric achieves 1.5% average classification er ror using the k-nearest neighbors and random forest classifiers. An average classification error of 2.5% is obtained using the baseline evaluation with the MobileNetV2 deep network for discriminating original and different types of fake hand samples.
GuideBP: Guiding Backpropagation Through Weaker Pathways of Parallel Logits
Apr 23, 2021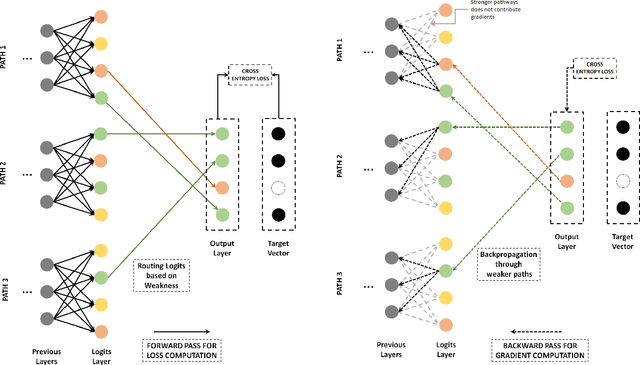
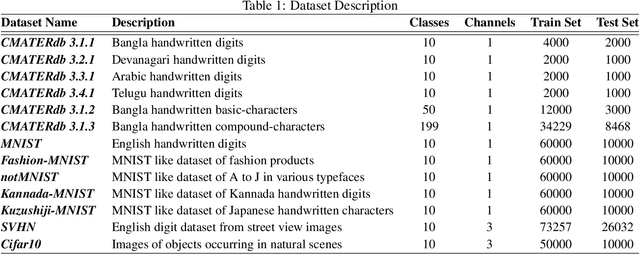

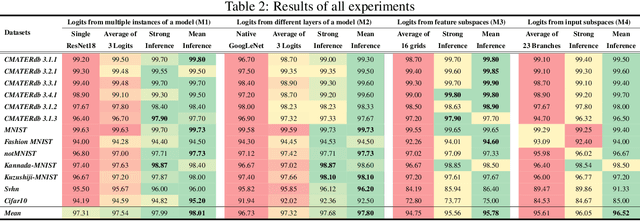
Convolutional neural networks often generate multiple logits and use simple techniques like addition or averaging for loss computation. But this allows gradients to be distributed equally among all paths. The proposed approach guides the gradients of backpropagation along weakest concept representations. A weakness scores defines the class specific performance of individual pathways which is then used to create a logit that would guide gradients along the weakest pathways. The proposed approach has been shown to perform better than traditional column merging techniques and can be used in several application scenarios. Not only can the proposed model be used as an efficient technique for training multiple instances of a model parallely, but also CNNs with multiple output branches have been shown to perform better with the proposed upgrade. Various experiments establish the flexibility of the learning technique which is simple yet effective in various multi-objective scenarios both empirically and statistically.