 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Augmentation for Enhancing Historical Document Image Binarization
Nov 12, 2022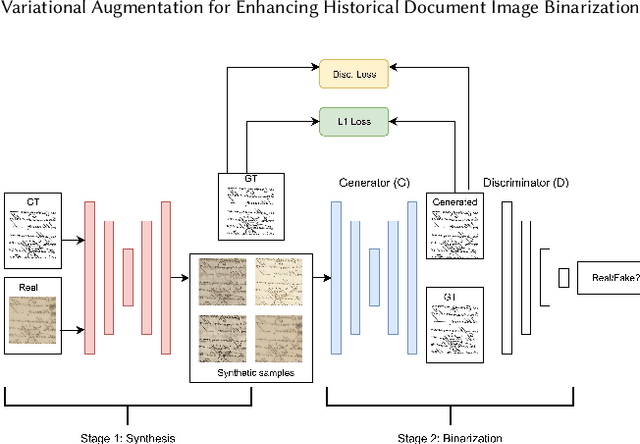
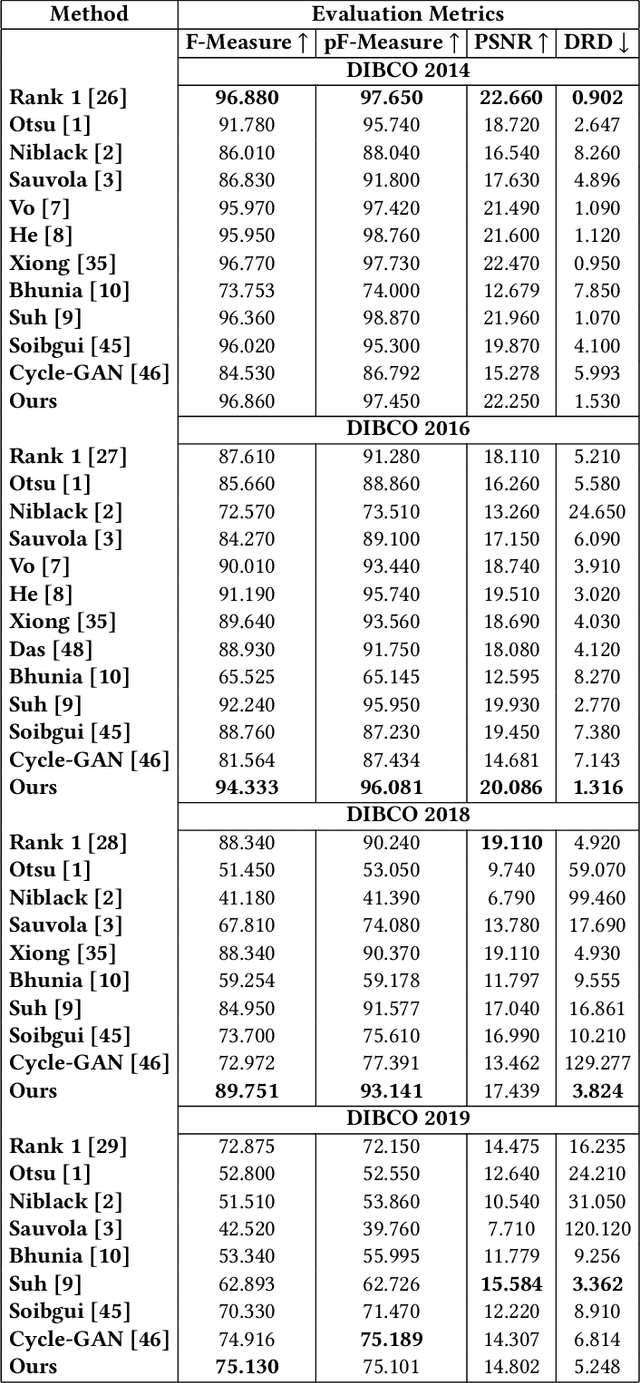
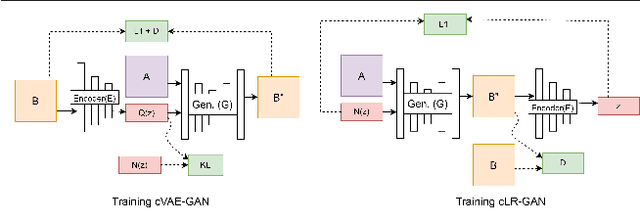
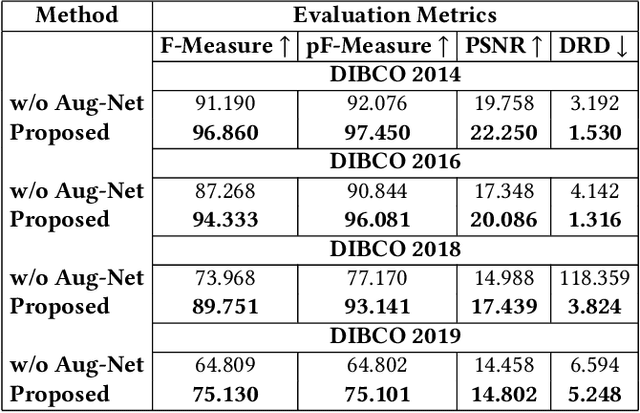
Historical Document Image Binarization is a well-known segmentation problem in image processing. Despite ubiquity, traditional thresholding algorithms achieved limited success on severely degraded document images. With the advent of deep learning, several segmentation models were proposed that made significant progress in the field but were limited by the unavailability of large training datasets. To mitigate this problem, we have proposed a novel two-stage framework -- the first of which comprises a generator that generates degraded samples using variational inference and the second being a CNN-based binarization network that trains on the generated data. We evaluated our framework on a range of DIBCO datasets, where it achieved competitive results against previous state-of-the-art methods.