 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideBP: Guiding Backpropagation Through Weaker Pathways of Parallel Logits
Apr 23, 2021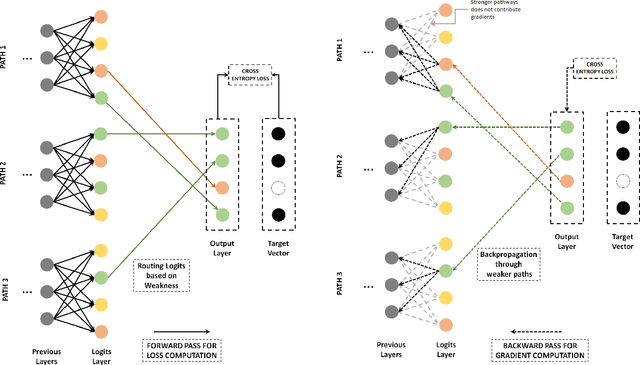
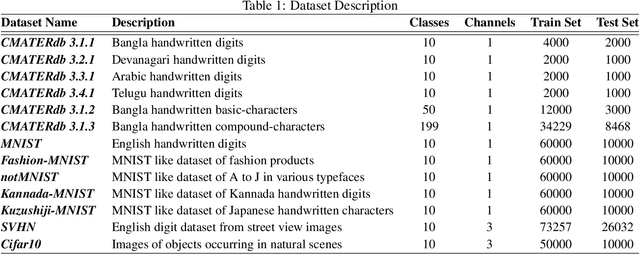

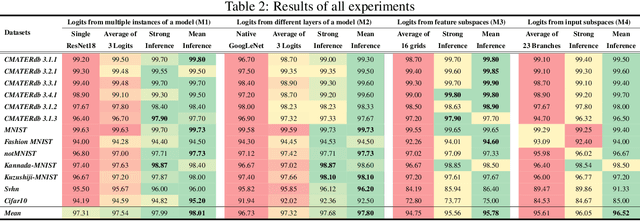
Convolutional neural networks often generate multiple logits and use simple techniques like addition or averaging for loss computation. But this allows gradients to be distributed equally among all paths. The proposed approach guides the gradients of backpropagation along weakest concept representations. A weakness scores defines the class specific performance of individual pathways which is then used to create a logit that would guide gradients along the weakest pathways. The proposed approach has been shown to perform better than traditional column merging techniques and can be used in several application scenarios. Not only can the proposed model be used as an efficient technique for training multiple instances of a model parallely, but also CNNs with multiple output branches have been shown to perform better with the proposed upgrade. Various experiments establish the flexibility of the learning technique which is simple yet effective in various multi-objective scenarios both empirically and statistically.
SynCGAN: Using learnable class specific priors to generate synthetic data for improving classifier performance on cytological images
Mar 12, 2020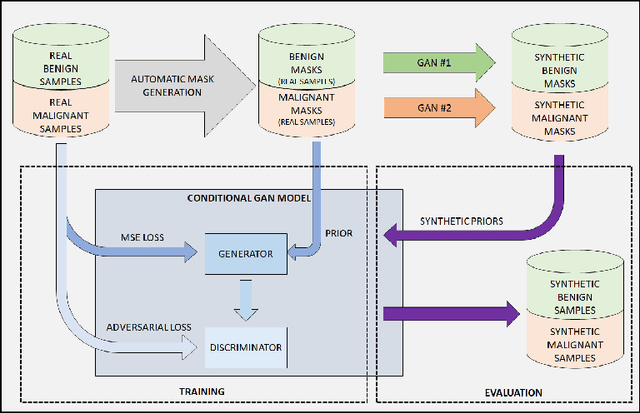

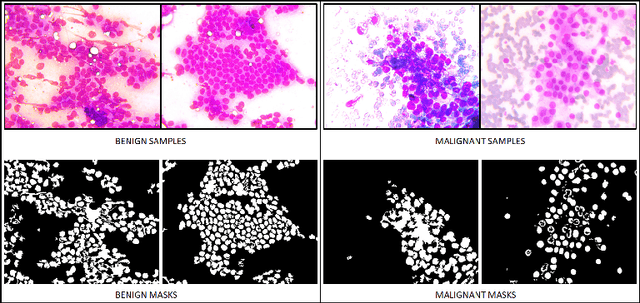

One of the most challenging aspects of medical image analysis is the lack of a high quantity of annotated data. This makes it difficult for deep learning algorithms to perform well due to a lack of variations in the input space. While generative adversarial networks have shown promise in the field of synthetic data generation, but without a carefully designed prior the generation procedure can not be performed well. In the proposed approach we have demonstrated the use of automatically generated segmentation masks as learnable class-specific priors to guide a conditional GAN for the generation of patho-realistic samples for cytology image. We have observed that augmentation of data using the proposed pipeline called "SynCGAN" improves the performance of state of the art classifiers such as ResNet-152, DenseNet-161, Inception-V3 significantly.
Understanding Deep Learning Techniques for Image Segmentation
Jul 13, 2019

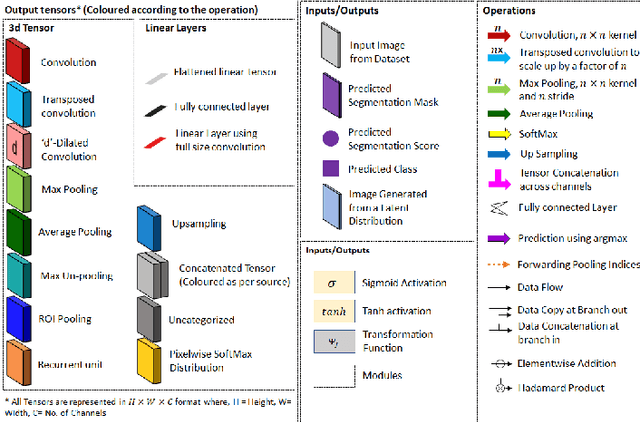

The machine learning community has been overwhelmed by a plethora of deep learning based approaches. Many challenging computer vision tasks such as detection, localization, recognition and segmentation of objects in unconstrained environment are being efficiently addressed by various types of deep neural networks like convolutional neural networks, recurrent networks, adversarial networks, autoencoders and so on. While there have been plenty of analytical studies regarding the object detection or recognition domain, many new deep learning techniques have surfaced with respect to image segmentation techniques. This paper approaches these various deep learning techniques of image segmentation from an analytical perspective. The main goal of this work is to provide an intuitive understanding of the major techniques that has made significant contribution to the image segmentation domain. Starting from some of the traditional image segmentation approaches, the paper progresses describing the effect deep learning had on the image segmentation domain. Thereafter, most of the major segmentation algorithms have been logically categorized with paragraphs dedicated to their unique contribution. With an ample amount of intuitive explanations, the reader is expected to have an improved ability to visualize the internal dynamics of these processes.
Using dynamic routing to extract intermediate features for developing scalable capsule networks
Jul 13, 2019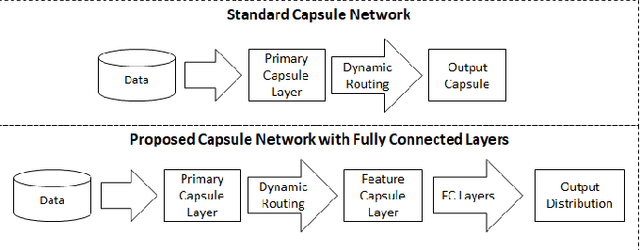
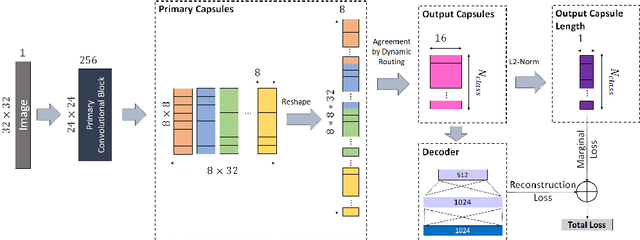
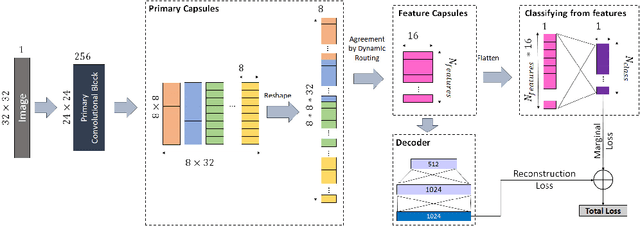
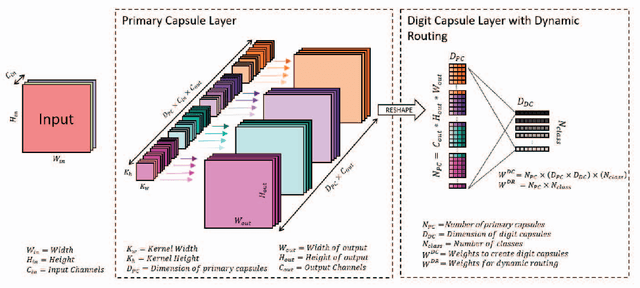
Capsule networks have gained a lot of popularity in short time due to its unique approach to model equivariant class specific properties as capsules from images. However the dynamic routing algorithm comes with a steep computational complexity. In the proposed approach we aim to create scalable versions of the capsule networks that are much faster and provide better accuracy in problems with higher number of classes. By using dynamic routing to extract intermediate features instead of generating output class specific capsules, a large increase in the computational speed has been observed. Moreover, by extracting equivariant feature capsules instead of class specific capsules, the generalization capability of the network has also increased as a result of which there is a boost in accuracy.
Handwritten Indic Character Recognition using Capsule Networks
Jan 01, 2019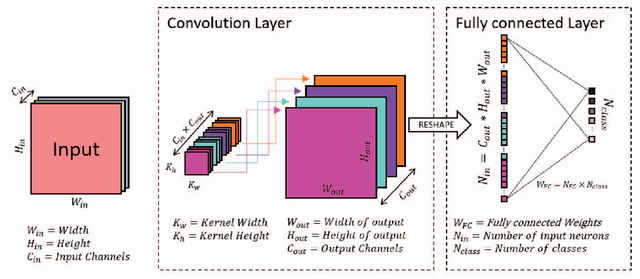
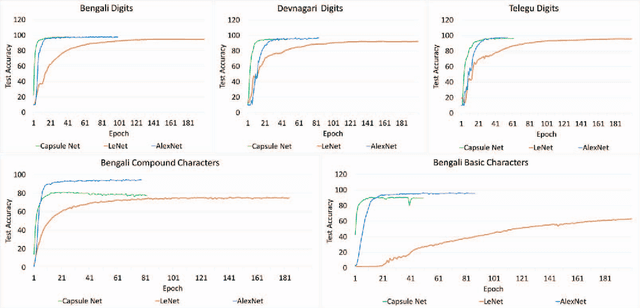

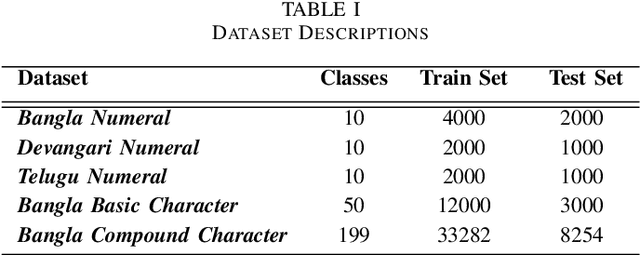
Convolutional neural networks(CNNs) has become one of the primary algorithms for various computer vision tasks. Handwritten character recognition is a typical example of such task that has also attracted attention. CNN architectures such as LeNet and AlexNet have become very prominent over the last two decades however the spatial invariance of the different kernels has been a prominent issue till now. With the introduction of capsule networks, kernels can work together in consensus with one another with the help of dynamic routing, that combines individual opinions of multiple groups of kernels called capsules to employ equivariance among kernels. In the current work, we have implemented capsule network on handwritten Indic digits and character datasets to show its superiority over networks like LeNet. Furthermore, it has also been shown that they can boost the performance of other networks like LeNet and AlexNet.
Combining Multi-level Contexts of Superpixel using Convolutional Neural Networks to perform Natural Scene Labeling
Mar 14, 2018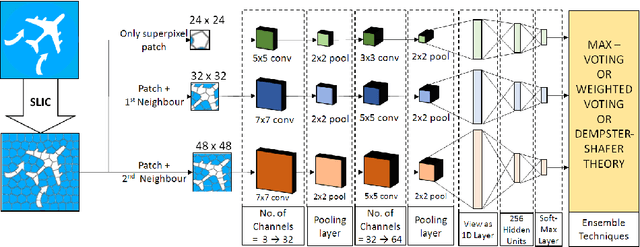
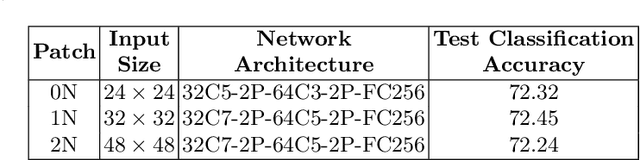

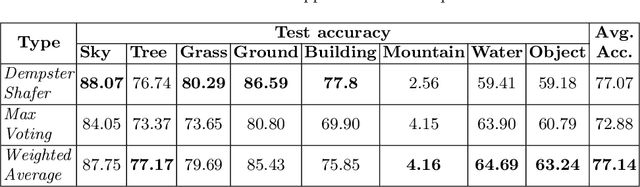
Modern deep learning algorithms have triggered various image segmentation approaches. However most of them deal with pixel based segmentation. However, superpixels provide a certain degree of contextual information while reducing computation cost. In our approach, we have performed superpixel level semantic segmentation considering 3 various levels as neighbours for semantic contexts. Furthermore, we have enlisted a number of ensemble approaches like max-voting and weighted-average. We have also used the Dempster-Shafer theory of uncertainty to analyze confusion among various classes. Our method has proved to be superior to a number of different modern approaches on the same dataset.
Deep learning for word-level handwritten Indic script identification
Jan 05, 2018

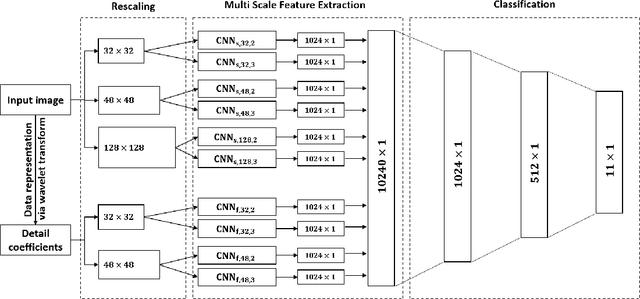
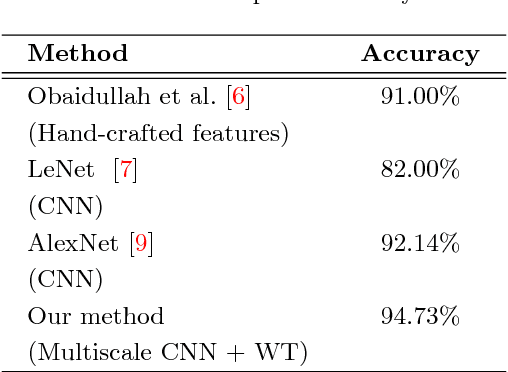
We propose a novel method that uses convolutional neural networks (CNNs) for feature extraction. Not just limited to conventional spatial domain representation, we use multilevel 2D discrete Haar wavelet transform, where image representations are scaled to a variety of different sizes. These are then used to train different CNNs to select features. To be precise, we use 10 different CNNs that select a set of 10240 features, i.e. 1024/CNN. With this, 11 different handwritten scripts are identified, where 1K words per script are used. In our test, we have achieved the maximum script identification rate of 94.73% using multi-layer perceptron (MLP). Our results outperform the state-of-the-art techniques.