 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Class-Conditional Distribution Alignment for Partial Domain Adaptation
Oct 19, 2023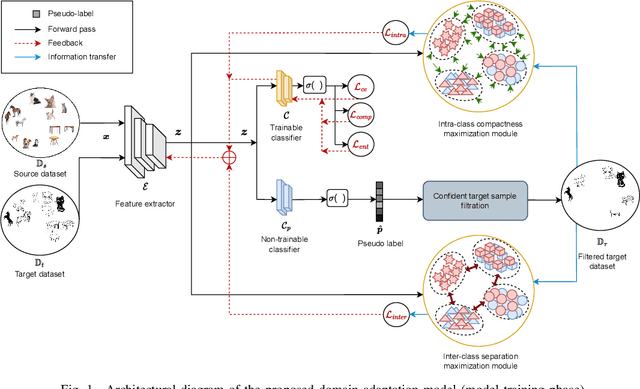


Unwanted samples from private source categories in the learning objective of a partial domain adaptation setup can lead to negative transfer and reduce classification performance. Existing methods, such as re-weighting or aggregating target predictions, are vulnerable to this issue, especially during initial training stages, and do not adequately address class-level feature alignment. Our proposed approach seeks to overcome these limitations by delving deeper than just the first-order moments to derive distinct and compact categorical distributions. We employ objectives that optimize the intra and inter-class distributions in a domain-invariant fashion and design a robust pseudo-labeling for efficient target supervision. Our approach incorporates a complement entropy objective module to reduce classification uncertainty and flatten incorrect category predictions. The experimental findings and ablation analysis of the proposed modules demonstrate the superior performance of our proposed model compared to benchmarks.
A Robust Negative Learning Approach to Partial Domain Adaptation Using Source Prototypes
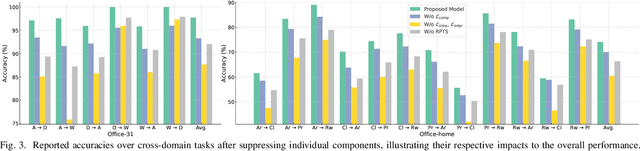
Sep 08, 2023This work proposes a robust Partial Domain Adaptation (PDA) framework that mitigates the negative transfer problem by incorporating a robust target-supervision strategy. It leverages ensemble learning and includes diverse, complementary label feedback, alleviating the effect of incorrect feedback and promoting pseudo-label refinement. Rather than relying exclusively on first-order moments for distribution alignment, our approach offers explicit objectives to optimize intra-class compactness and inter-class separation with the inferred source prototypes and highly-confident target samples in a domain-invariant fashion. Notably, we ensure source data privacy by eliminating the need to access the source data during the adaptation phase through a priori inference of source prototypes. We conducted a series of comprehensive experiments, including an ablation analysis, covering a range of partial domain adaptation tasks. Comprehensive evaluations on benchmark datasets corroborate our framework's enhanced robustness and generalization, demonstrating its superiority over existing state-of-the-art PDA approaches.
Domain-Invariant Feature Alignment Using Variational Inference For Partial Domain Adaptation
Dec 03, 2022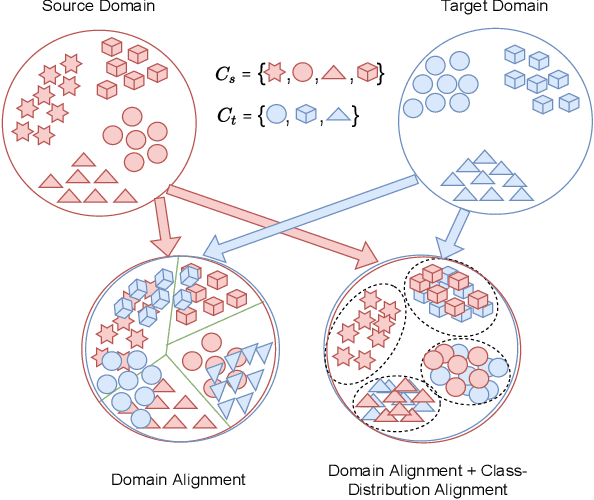
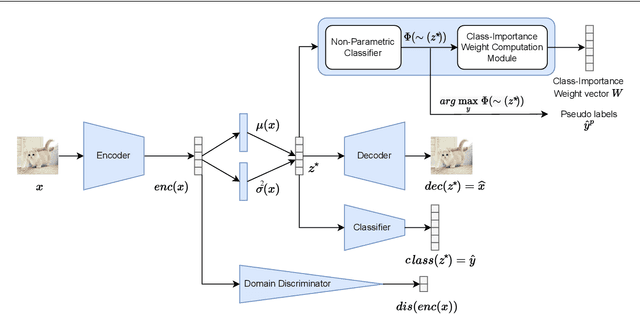
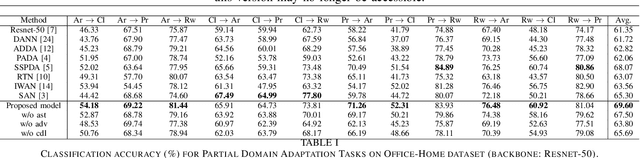
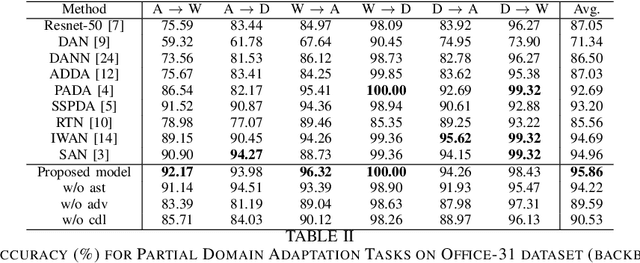
The standard closed-set domain adaptation approaches seek to mitigate distribution discrepancies between two domains under the constraint of both sharing identical label sets. However, in realistic scenarios, finding an optimal source domain with identical label space is a challenging task. Partial domain adaptation alleviates this problem of procuring a labeled dataset with identical label space assumptions and addresses a more practical scenario where the source label set subsumes the target label set. This, however, presents a few additional obstacles during adaptation. Samples with categories private to the source domain thwart relevant knowledge transfer and degrade model performance. In this work, we try to address these issues by coupling variational information and adversarial learning with a pseudo-labeling technique to enforce class distribution alignment and minimize the transfer of superfluous information from the source samples. The experimental findings in numerous cross-domain classification tasks demonstrate that the proposed technique delivers superior and comparable accuracy to existing methods.
Coupling Adversarial Learning with Selective Voting Strategy for Distribution Alignment in Partial Domain Adaptation
Jul 17, 2022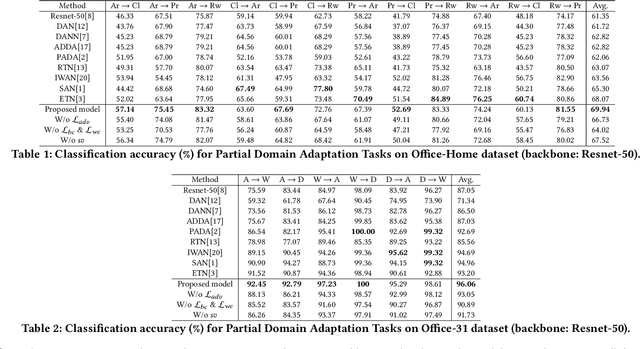
In contrast to a standard closed-set domain adaptation task, partial domain adaptation setup caters to a realistic scenario by relaxing the identical label set assumption. The fact of source label set subsuming the target label set, however, introduces few additional obstacles as training on private source category samples thwart relevant knowledge transfer and mislead the classification process. To mitigate these issues, we devise a mechanism for strategic selection of highly-confident target samples essential for the estimation of class-importance weights. Furthermore, we capture class-discriminative and domain-invariant features by coupling the process of achieving compact and distinct class distributions with an adversarial objective. Experimental findings over numerous cross-domain classification tasks demonstrate the potential of the proposed technique to deliver superior and comparable accuracy over existing methods.
Partial Domain Adaptation Using Selective Representation Learning For Class-Weight Computation
Jan 06, 2021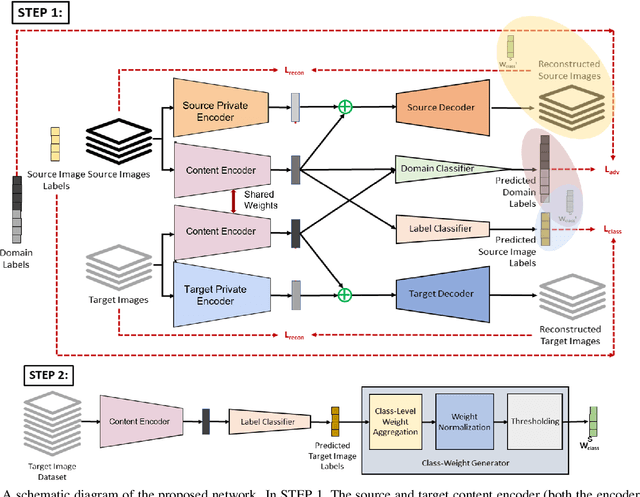
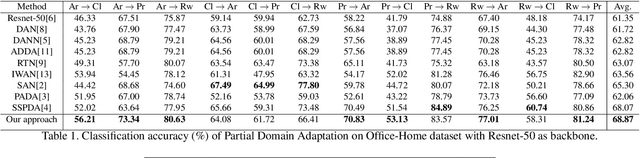
The generalization power of deep-learning models is dependent on rich-labelled data. This supervision using large-scaled annotated information is restrictive in most real-world scenarios where data collection and their annotation involve huge cost. Various domain adaptation techniques exist in literature that bridge this distribution discrepancy. However, a majority of these models require the label sets of both the domains to be identical. To tackle a more practical and challenging scenario, we formulate the problem statement from a partial domain adaptation perspective, where the source label set is a super set of the target label set. Driven by the motivation that image styles are private to each domain, in this work, we develop a method that identifies outlier classes exclusively from image content information and train a label classifier exclusively on class-content from source images. Additionally, elimination of negative transfer of samples from classes private to the source domain is achieved by transforming the soft class-level weights into two clusters, 0 (outlier source classes) and 1 (shared classes) by maximizing the between-cluster variance between them.
Predicting Future Opioid Incidences Today
Jun 20, 2019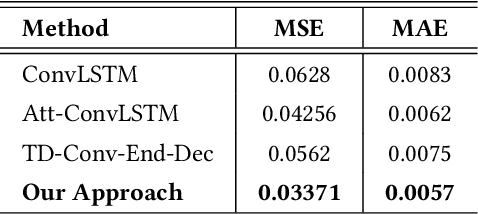
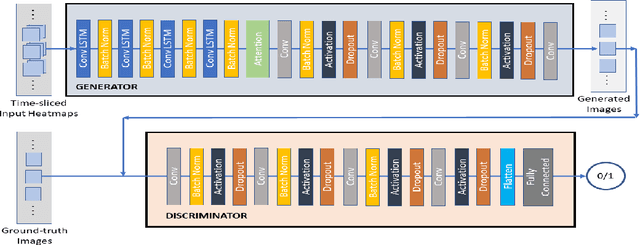
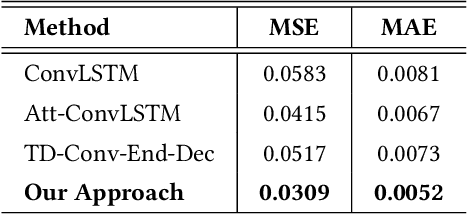

According to the Center of Disease Control (CDC), the Opioid epidemic has claimed more than 72,000 lives in the US in 2017 alone. In spite of various efforts at the local, state and federal level, the impact of the epidemic is becoming progressively worse, as evidenced by the fact that the number of Opioid related deaths increased by 12.5\% between 2016 and 2017. Predictive analytics can play an important role in combating the epidemic by providing decision making tools to stakeholders at multiple levels - from health care professionals to policy makers to first responders. Generating Opioid incidence heat maps from past data, aid these stakeholders to visualize the profound impact of the Opioid epidemic. Such post-fact creation of the heat map provides only retrospective information, and as a result, may not be as useful for preventive action in the current or future time-frames. In this paper, we present a novel deep neural architecture, which learns subtle spatio-temporal variations in Opioid incidences data and accurately predicts future heat maps. We evaluated the efficacy of our model on two open source datasets- (i) The Cincinnati Heroin Overdose dataset, and (ii) Connecticut Drug Related Death Dataset.
Combining Multi-level Contexts of Superpixel using Convolutional Neural Networks to perform Natural Scene Labeling
Mar 14, 2018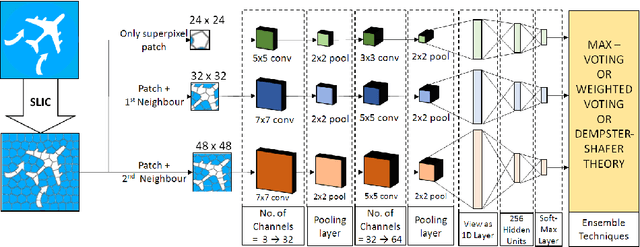
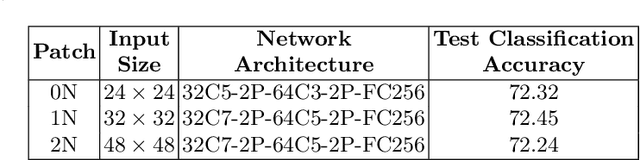

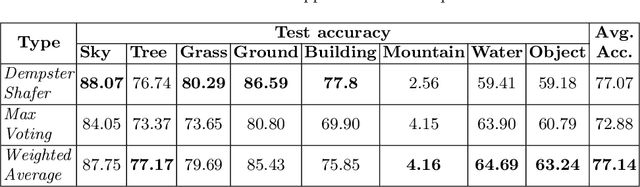
Modern deep learning algorithms have triggered various image segmentation approaches. However most of them deal with pixel based segmentation. However, superpixels provide a certain degree of contextual information while reducing computation cost. In our approach, we have performed superpixel level semantic segmentation considering 3 various levels as neighbours for semantic contexts. Furthermore, we have enlisted a number of ensemble approaches like max-voting and weighted-average. We have also used the Dempster-Shafer theory of uncertainty to analyze confusion among various classes. Our method has proved to be superior to a number of different modern approaches on the same dataset.