 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Negative Learning Approach to Partial Domain Adaptation Using Source Prototypes
Sep 08, 2023This work proposes a robust Partial Domain Adaptation (PDA) framework that mitigates the negative transfer problem by incorporating a robust target-supervision strategy. It leverages ensemble learning and includes diverse, complementary label feedback, alleviating the effect of incorrect feedback and promoting pseudo-label refinement. Rather than relying exclusively on first-order moments for distribution alignment, our approach offers explicit objectives to optimize intra-class compactness and inter-class separation with the inferred source prototypes and highly-confident target samples in a domain-invariant fashion. Notably, we ensure source data privacy by eliminating the need to access the source data during the adaptation phase through a priori inference of source prototypes. We conducted a series of comprehensive experiments, including an ablation analysis, covering a range of partial domain adaptation tasks. Comprehensive evaluations on benchmark datasets corroborate our framework's enhanced robustness and generalization, demonstrating its superiority over existing state-of-the-art PDA approaches.
Domain-Invariant Feature Alignment Using Variational Inference For Partial Domain Adaptation
Dec 03, 2022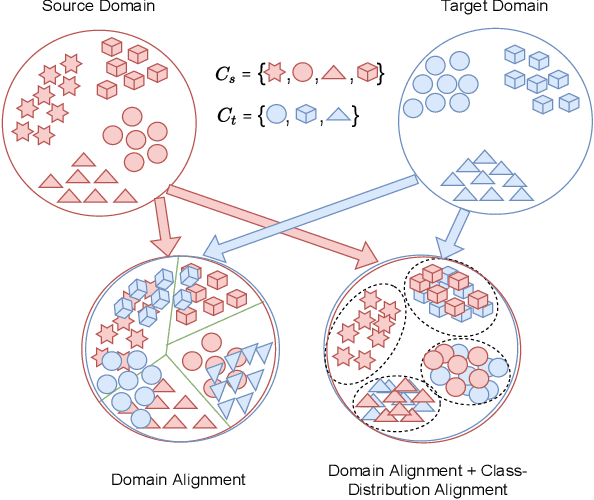
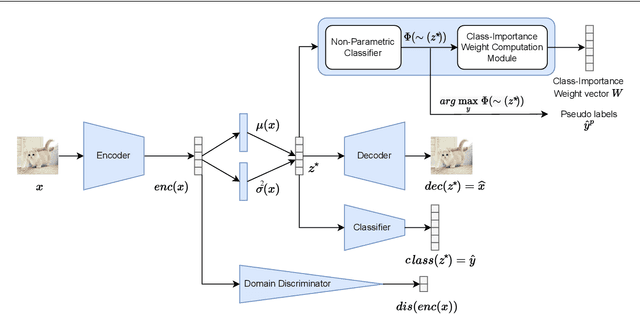
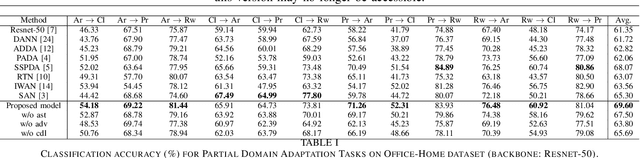
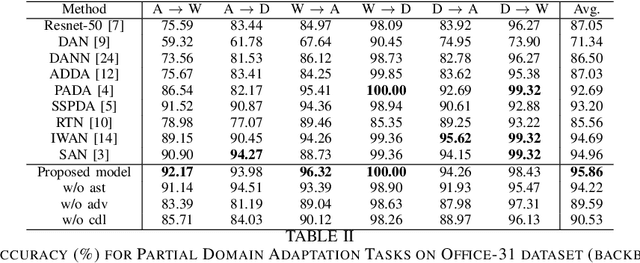
The standard closed-set domain adaptation approaches seek to mitigate distribution discrepancies between two domains under the constraint of both sharing identical label sets. However, in realistic scenarios, finding an optimal source domain with identical label space is a challenging task. Partial domain adaptation alleviates this problem of procuring a labeled dataset with identical label space assumptions and addresses a more practical scenario where the source label set subsumes the target label set. This, however, presents a few additional obstacles during adaptation. Samples with categories private to the source domain thwart relevant knowledge transfer and degrade model performance. In this work, we try to address these issues by coupling variational information and adversarial learning with a pseudo-labeling technique to enforce class distribution alignment and minimize the transfer of superfluous information from the source samples. The experimental findings in numerous cross-domain classification tasks demonstrate that the proposed technique delivers superior and comparable accuracy to existing methods.