 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHIMERA-Bench: A Benchmark Dataset for Epitope-Specific Antibody Design
Mar 13, 2026Computational antibody design has seen rapid methodological progress, with dozens of deep generative methods proposed in the past three years, yet the field lacks a standardized benchmark for fair comparison and model development. These methods are evaluated on different SAbDab snapshots, non-overlapping test sets, and incompatible metrics, and the literature fragments the design problem into numerous sub-tasks with no common definition. We introduce \textsc{Chimera-Bench} (\textbf{C}DR \textbf{M}odeling with \textbf{E}pitope-guided \textbf{R}edesign), a unified benchmark built around a single canonical task: \emph{epitope-conditioned CDR sequence-structure co-design}. \textsc{Chimera-Bench} provides (1) a curated, deduplicated dataset of \textbf{2,922} antibody-antigen complexes with epitope and paratope annotations; (2) three biologically motivated splits testing generalization to unseen epitopes, unseen antigen folds, and prospective temporal targets; and (3) a comprehensive evaluation protocol with five metric groups including novel epitope-specificity measures. We benchmark representative methods spanning different generative paradigms and report results across all splits. \textsc{Chimera-Bench} is the largest dataset of its kind for the antibody design problem, allowing the community to develop and test novel methods and evaluate their generalizability. The source code and data are available at: https://github.com/mansoor181/chimera-bench.git
Dataset Augmentation by Mixing Visual Concepts
Dec 19, 2024



This paper proposes a dataset augmentation method by fine-tuning pre-trained diffusion models. Generating images using a pre-trained diffusion model with textual conditioning often results in domain discrepancy between real data and generated images. We propose a fine-tuning approach where we adapt the diffusion model by conditioning it with real images and novel text embeddings. We introduce a unique procedure called Mixing Visual Concepts (MVC) where we create novel text embeddings from image captions. The MVC enables us to generate multiple images which are diverse and yet similar to the real data enabling us to perform effective dataset augmentation. We perform comprehensive qualitative and quantitative evaluations with the proposed dataset augmentation approach showcasing both coarse-grained and finegrained changes in generated images. Our approach outperforms state-of-the-art augmentation techniques on benchmark classification tasks.
Domain Adaptation Using Pseudo Labels
Feb 09, 2024In the absence of labeled target data, unsupervised domain adaptation approaches seek to align the marginal distributions of the source and target domains in order to train a classifier for the target. Unsupervised domain alignment procedures are category-agnostic and end up misaligning the categories. We address this problem by deploying a pretrained network to determine accurate labels for the target domain using a multi-stage pseudo-label refinement procedure. The filters are based on the confidence, distance (conformity), and consistency of the pseudo labels. Our results on multiple datasets demonstrate the effectiveness of our simple procedure in comparison with complex state-of-the-art techniques.
Domain-Invariant Feature Alignment Using Variational Inference For Partial Domain Adaptation
Dec 03, 2022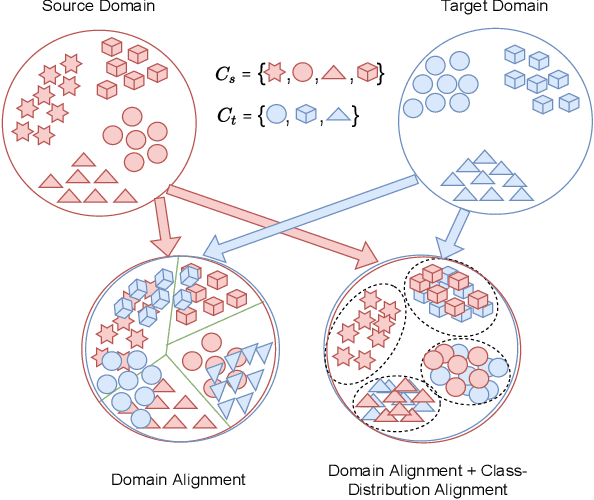
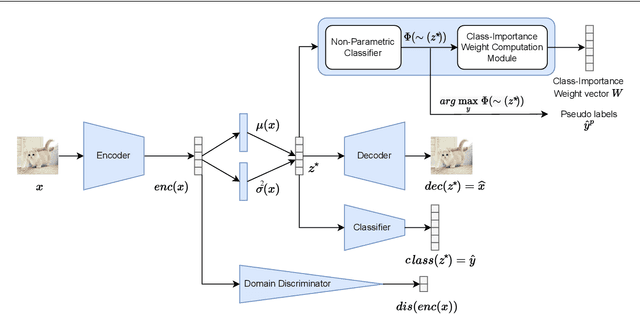
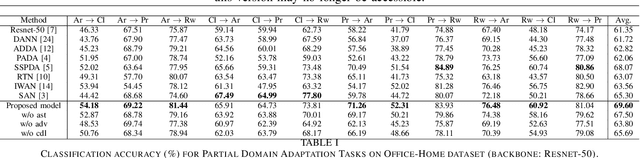
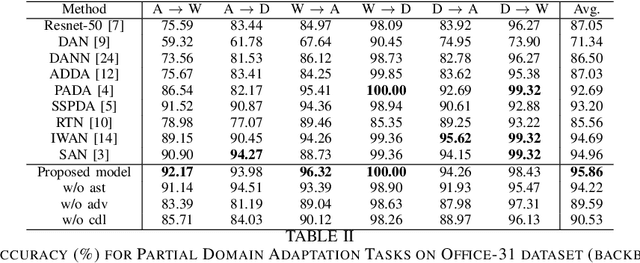
The standard closed-set domain adaptation approaches seek to mitigate distribution discrepancies between two domains under the constraint of both sharing identical label sets. However, in realistic scenarios, finding an optimal source domain with identical label space is a challenging task. Partial domain adaptation alleviates this problem of procuring a labeled dataset with identical label space assumptions and addresses a more practical scenario where the source label set subsumes the target label set. This, however, presents a few additional obstacles during adaptation. Samples with categories private to the source domain thwart relevant knowledge transfer and degrade model performance. In this work, we try to address these issues by coupling variational information and adversarial learning with a pseudo-labeling technique to enforce class distribution alignment and minimize the transfer of superfluous information from the source samples. The experimental findings in numerous cross-domain classification tasks demonstrate that the proposed technique delivers superior and comparable accuracy to existing methods.
PatchRot: A Self-Supervised Technique for Training Vision Transformers
Oct 27, 2022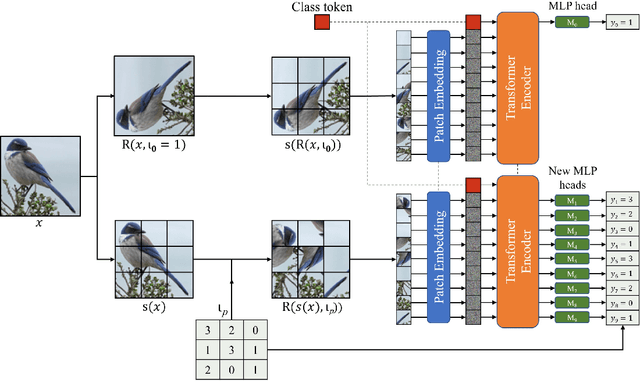
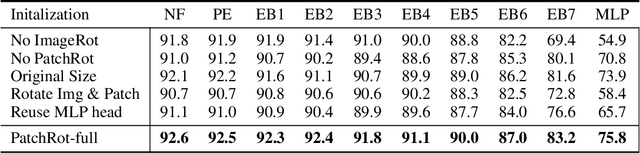
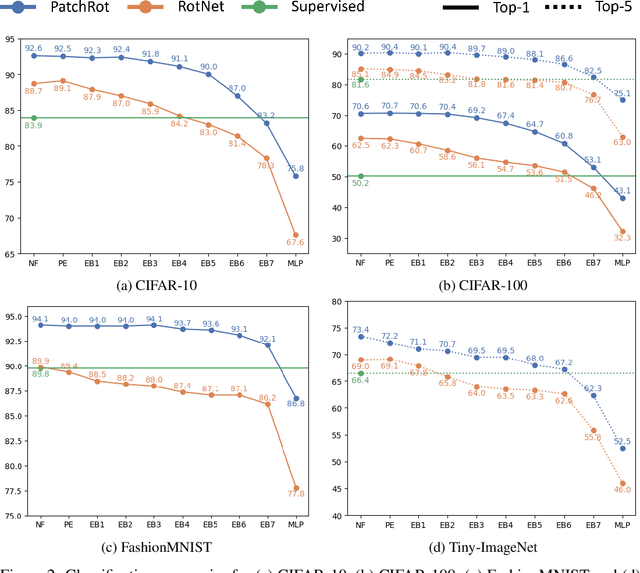
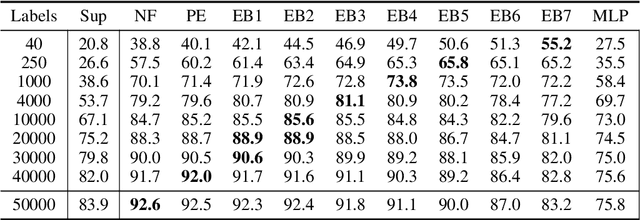
Vision transformers require a huge amount of labeled data to outperform convolutional neural networks. However, labeling a huge dataset is a very expensive process. Self-supervised learning techniques alleviate this problem by learning features similar to supervised learning in an unsupervised way. In this paper, we propose a self-supervised technique PatchRot that is crafted for vision transformers. PatchRot rotates images and image patches and trains the network to predict the rotation angles. The network learns to extract both global and local features from an image. Our extensive experiments on different datasets showcase PatchRot training learns rich features which outperform supervised learning and compared baseline.
Coupling Adversarial Learning with Selective Voting Strategy for Distribution Alignment in Partial Domain Adaptation
Jul 17, 2022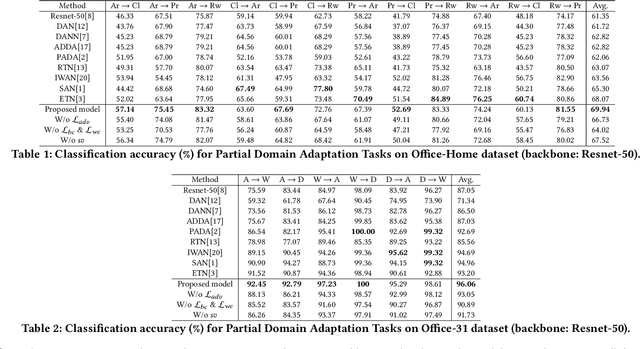
In contrast to a standard closed-set domain adaptation task, partial domain adaptation setup caters to a realistic scenario by relaxing the identical label set assumption. The fact of source label set subsuming the target label set, however, introduces few additional obstacles as training on private source category samples thwart relevant knowledge transfer and mislead the classification process. To mitigate these issues, we devise a mechanism for strategic selection of highly-confident target samples essential for the estimation of class-importance weights. Furthermore, we capture class-discriminative and domain-invariant features by coupling the process of achieving compact and distinct class distributions with an adversarial objective. Experimental findings over numerous cross-domain classification tasks demonstrate the potential of the proposed technique to deliver superior and comparable accuracy over existing methods.
Sparsity Regularization For Cold-Start Recommendation
Jan 28, 2022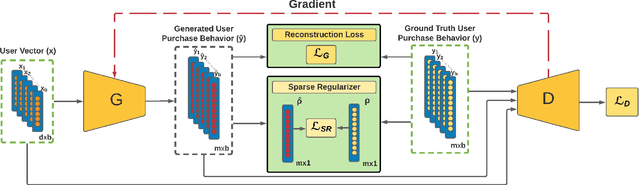
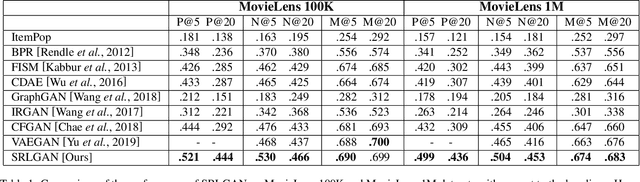

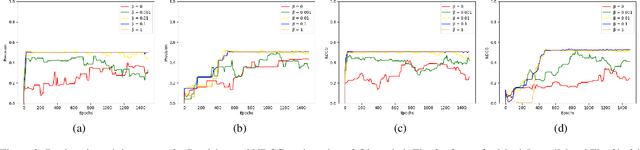
Recently, Generative Adversarial Networks (GANs) have been applied to the problem of Cold-Start Recommendation, but the training performance of these models is hampered by the extreme sparsity in warm user purchase behavior. In this paper we introduce a novel representation for user-vectors by combining user demographics and user preferences, making the model a hybrid system which uses Collaborative Filtering and Content Based Recommendation. Our system models user purchase behavior using weighted user-product preferences (explicit feedback) rather than binary user-product interactions (implicit feedback). Using this we develop a novel sparse adversarial model, SRLGAN, for Cold-Start Recommendation leveraging the sparse user-purchase behavior which ensures training stability and avoids over-fitting on warm users. We evaluate the SRLGAN on two popular datasets and demonstrate state-of-the-art results.
Partial Domain Adaptation Using Selective Representation Learning For Class-Weight Computation
Jan 06, 2021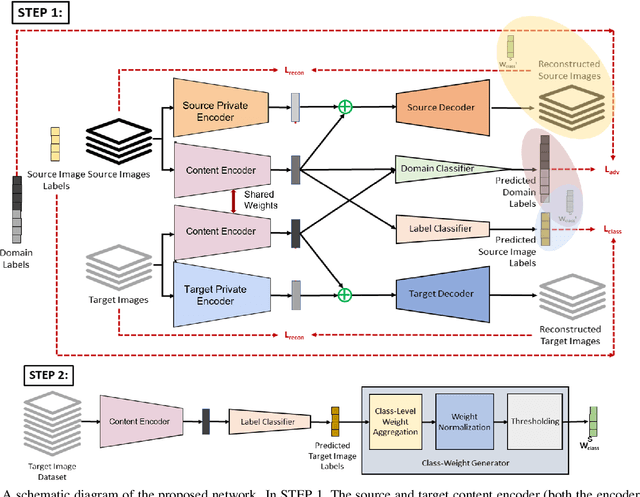
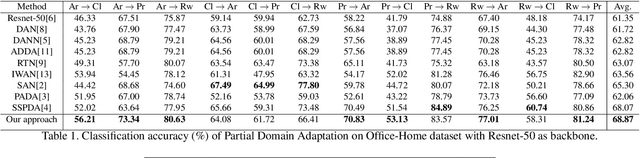
The generalization power of deep-learning models is dependent on rich-labelled data. This supervision using large-scaled annotated information is restrictive in most real-world scenarios where data collection and their annotation involve huge cost. Various domain adaptation techniques exist in literature that bridge this distribution discrepancy. However, a majority of these models require the label sets of both the domains to be identical. To tackle a more practical and challenging scenario, we formulate the problem statement from a partial domain adaptation perspective, where the source label set is a super set of the target label set. Driven by the motivation that image styles are private to each domain, in this work, we develop a method that identifies outlier classes exclusively from image content information and train a label classifier exclusively on class-content from source images. Additionally, elimination of negative transfer of samples from classes private to the source domain is achieved by transforming the soft class-level weights into two clusters, 0 (outlier source classes) and 1 (shared classes) by maximizing the between-cluster variance between them.
Leveraging Seen and Unseen Semantic Relationships for Generative Zero-Shot Learning
Jul 19, 2020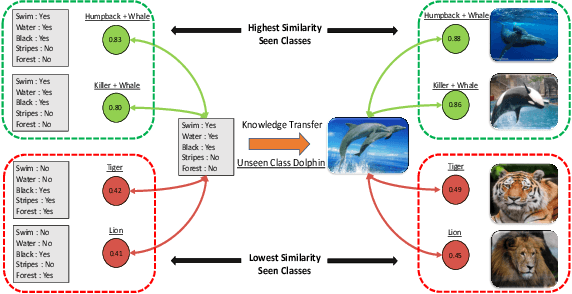

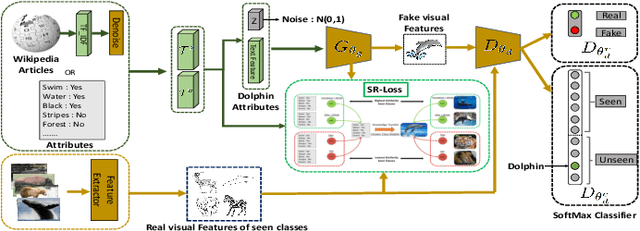
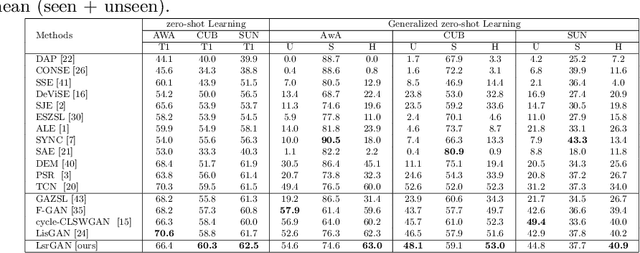
Zero-shot learning (ZSL) addresses the unseen class recognition problem by leveraging semantic information to transfer knowledge from seen classes to unseen classes. Generative models synthesize the unseen visual features and convert ZSL into a classical supervised learning problem. These generative models are trained using the seen classes and are expected to implicitly transfer the knowledge from seen to unseen classes. However, their performance is stymied by overfitting, which leads to substandard performance on Generalized Zero-Shot learning (GZSL). To address this concern, we propose the novel LsrGAN, a generative model that Leverages the Semantic Relationship between seen and unseen categories and explicitly performs knowledge transfer by incorporating a novel Semantic Regularized Loss (SR-Loss). The SR-loss guides the LsrGAN to generate visual features that mirror the semantic relationships between seen and unseen classes. Experiments on seven benchmark datasets, including the challenging Wikipedia text-based CUB and NABirds splits, and Attribute-based AWA, CUB, and SUN, demonstrates the superiority of the LsrGAN compared to previous state-of-the-art approaches under both ZSL and GZSL. Code is available at https: // github. com/ Maunil/ LsrGAN
Representation, Exploration and Recommendation of Music Playlists
Jul 01, 2019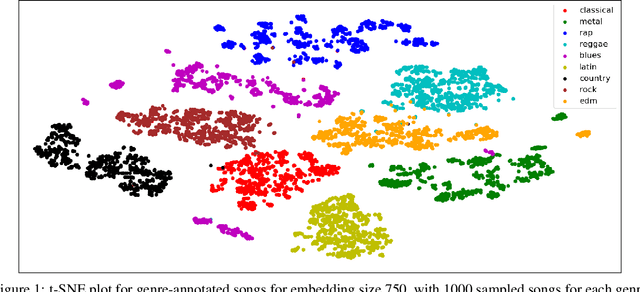
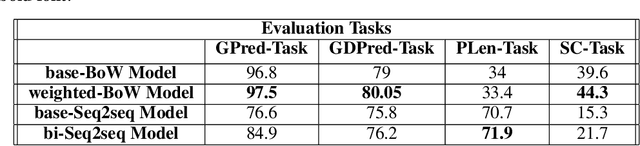
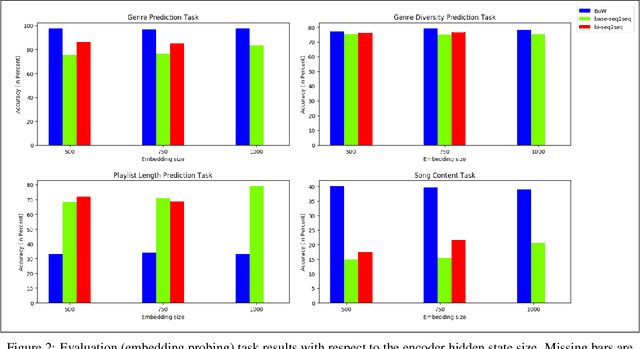
Playlists have become a significant part of our listening experience because of the digital cloud-based services such as Spotify, Pandora, Apple Music. Owing to the meteoric rise in the usage of playlists, recommending playlists is crucial to music services today. Although there has been a lot of work done in playlist prediction, the area of playlist representation hasn't received that level of attention. Over the last few years, sequence-to-sequence models, especially in the field of natural language processing, have shown the effectiveness of learned embeddings in capturing the semantic characteristics of sequences. We can apply similar concepts to music to learn fixed length representations for playlists and use those representations for downstream tasks such as playlist discovery, browsing, and recommendation. In this work, we formulate the problem of learning a fixed-length playlist representation in an unsupervised manner, using Sequence-to-sequence (Seq2seq) models, interpreting playlists as sentences and songs as words. We compare our model with two other encoding architectures for baseline comparison. We evaluate our work using the suite of tasks commonly used for assessing sentence embeddings, along with a few additional tasks pertaining to music, and a recommendation task to study the traits captured by the playlist embeddings and their effectiveness for the purpose of music recommendation.