 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation, Exploration and Recommendation of Music Playlists
Paper and Code
Jul 01, 2019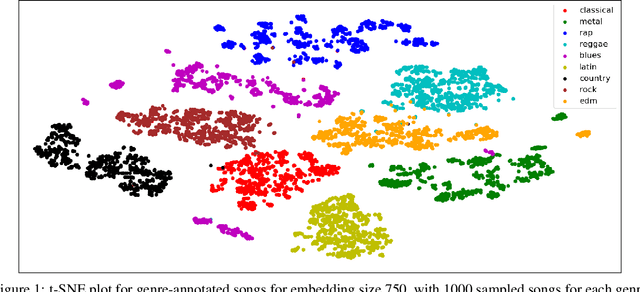
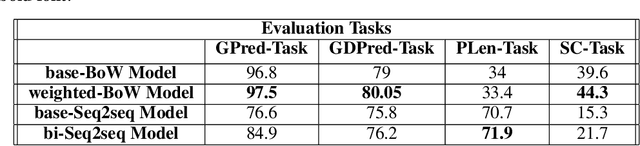
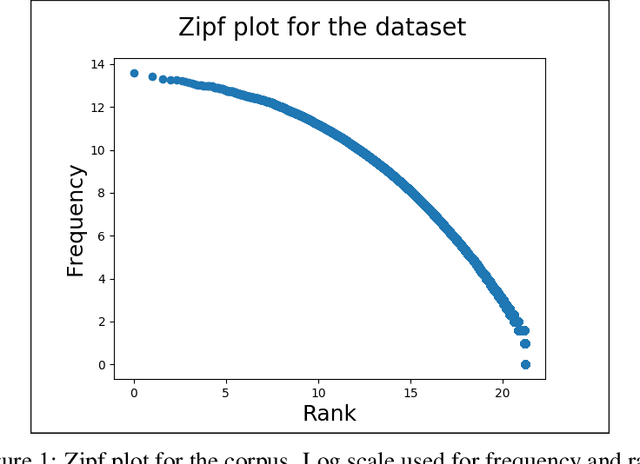
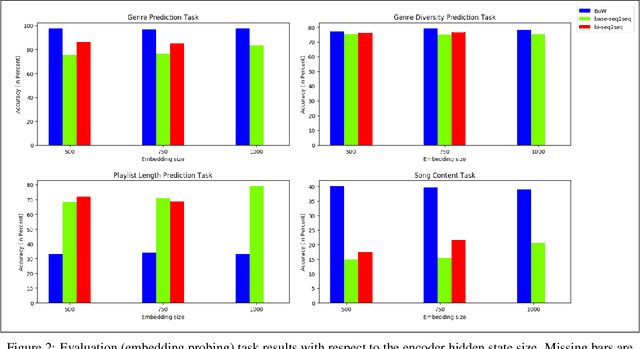
Playlists have become a significant part of our listening experience because of the digital cloud-based services such as Spotify, Pandora, Apple Music. Owing to the meteoric rise in the usage of playlists, recommending playlists is crucial to music services today. Although there has been a lot of work done in playlist prediction, the area of playlist representation hasn't received that level of attention. Over the last few years, sequence-to-sequence models, especially in the field of natural language processing, have shown the effectiveness of learned embeddings in capturing the semantic characteristics of sequences. We can apply similar concepts to music to learn fixed length representations for playlists and use those representations for downstream tasks such as playlist discovery, browsing, and recommendation. In this work, we formulate the problem of learning a fixed-length playlist representation in an unsupervised manner, using Sequence-to-sequence (Seq2seq) models, interpreting playlists as sentences and songs as words. We compare our model with two other encoding architectures for baseline comparison. We evaluate our work using the suite of tasks commonly used for assessing sentence embeddings, along with a few additional tasks pertaining to music, and a recommendation task to study the traits captured by the playlist embeddings and their effectiveness for the purpose of music recommendation.