 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Seen and Unseen Semantic Relationships for Generative Zero-Shot Learning
Jul 19, 2020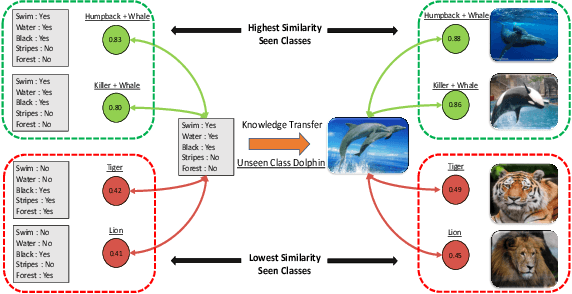

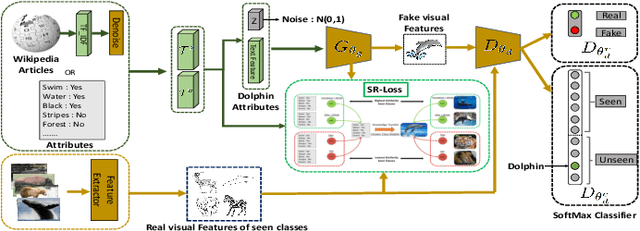
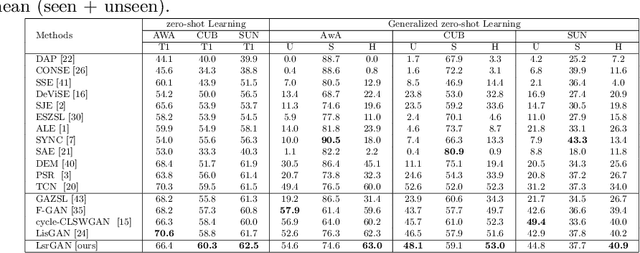
Zero-shot learning (ZSL) addresses the unseen class recognition problem by leveraging semantic information to transfer knowledge from seen classes to unseen classes. Generative models synthesize the unseen visual features and convert ZSL into a classical supervised learning problem. These generative models are trained using the seen classes and are expected to implicitly transfer the knowledge from seen to unseen classes. However, their performance is stymied by overfitting, which leads to substandard performance on Generalized Zero-Shot learning (GZSL). To address this concern, we propose the novel LsrGAN, a generative model that Leverages the Semantic Relationship between seen and unseen categories and explicitly performs knowledge transfer by incorporating a novel Semantic Regularized Loss (SR-Loss). The SR-loss guides the LsrGAN to generate visual features that mirror the semantic relationships between seen and unseen classes. Experiments on seven benchmark datasets, including the challenging Wikipedia text-based CUB and NABirds splits, and Attribute-based AWA, CUB, and SUN, demonstrates the superiority of the LsrGAN compared to previous state-of-the-art approaches under both ZSL and GZSL. Code is available at https: // github. com/ Maunil/ LsrGAN
Representation, Exploration and Recommendation of Music Playlists
Jul 01, 2019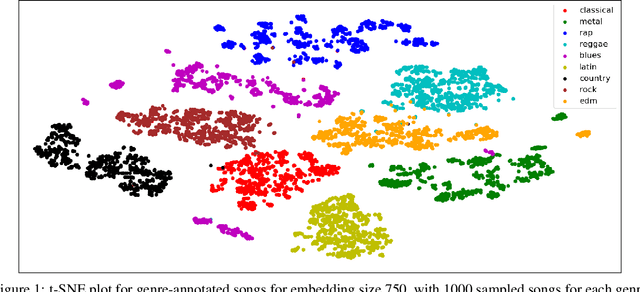
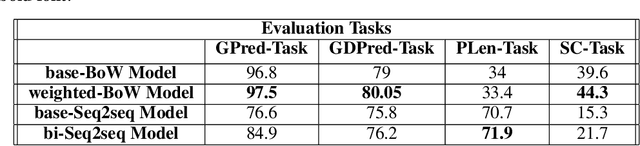
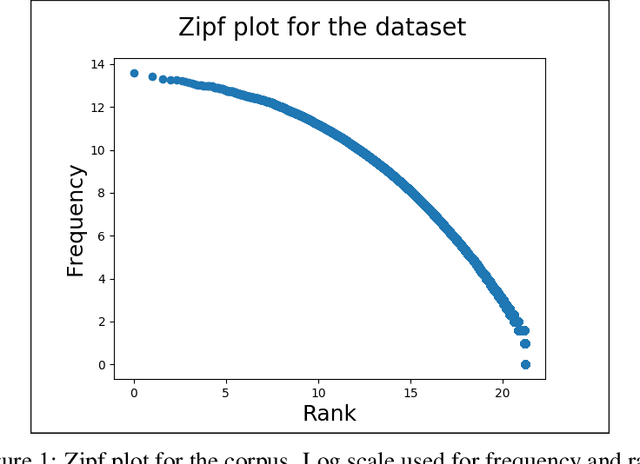
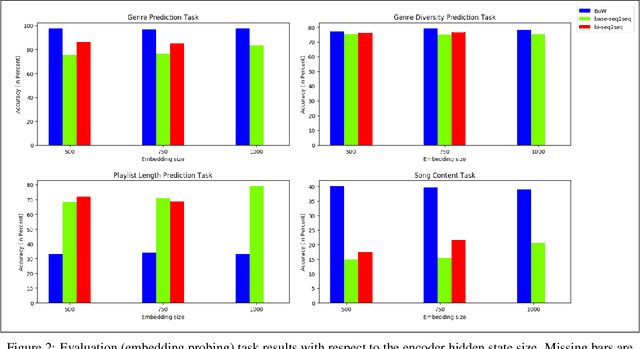
Playlists have become a significant part of our listening experience because of the digital cloud-based services such as Spotify, Pandora, Apple Music. Owing to the meteoric rise in the usage of playlists, recommending playlists is crucial to music services today. Although there has been a lot of work done in playlist prediction, the area of playlist representation hasn't received that level of attention. Over the last few years, sequence-to-sequence models, especially in the field of natural language processing, have shown the effectiveness of learned embeddings in capturing the semantic characteristics of sequences. We can apply similar concepts to music to learn fixed length representations for playlists and use those representations for downstream tasks such as playlist discovery, browsing, and recommendation. In this work, we formulate the problem of learning a fixed-length playlist representation in an unsupervised manner, using Sequence-to-sequence (Seq2seq) models, interpreting playlists as sentences and songs as words. We compare our model with two other encoding architectures for baseline comparison. We evaluate our work using the suite of tasks commonly used for assessing sentence embeddings, along with a few additional tasks pertaining to music, and a recommendation task to study the traits captured by the playlist embeddings and their effectiveness for the purpose of music recommendation.
A Strategy for an Uncompromising Incremental Learner
Jul 17, 2017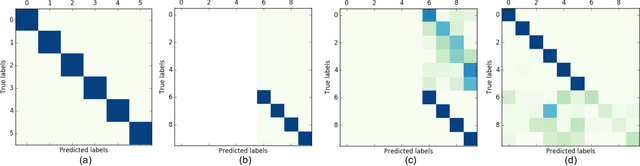
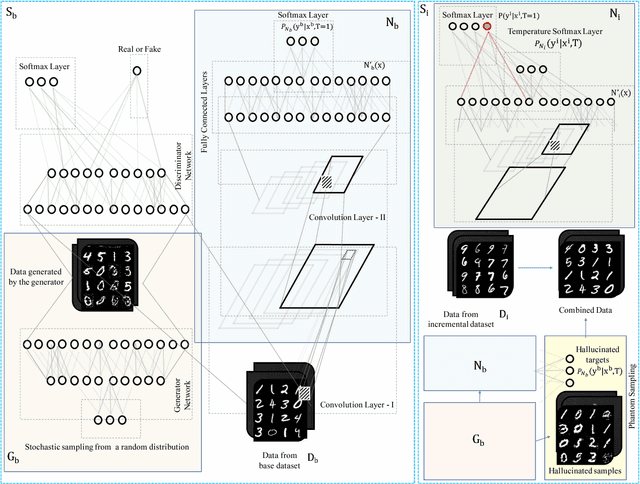
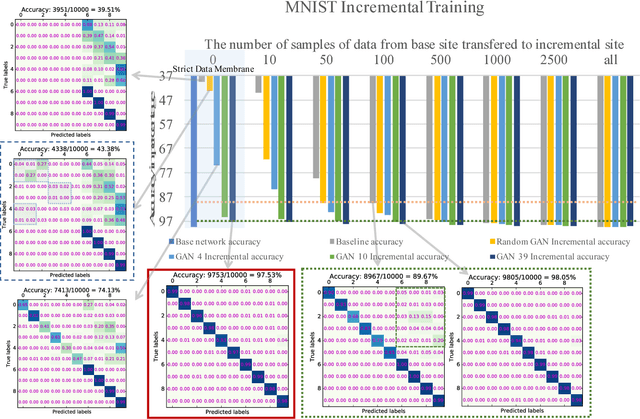
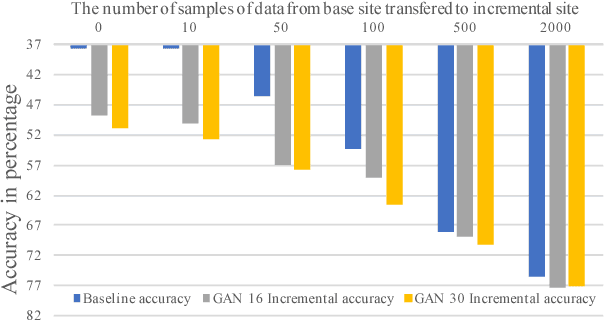
Multi-class supervised learning systems require the knowledge of the entire range of labels they predict. Often when learnt incrementally, they suffer from catastrophic forgetting. To avoid this, generous leeways have to be made to the philosophy of incremental learning that either forces a part of the machine to not learn, or to retrain the machine again with a selection of the historic data. While these hacks work to various degrees, they do not adhere to the spirit of incremental learning. In this article, we redefine incremental learning with stringent conditions that do not allow for any undesirable relaxations and assumptions. We design a strategy involving generative models and the distillation of dark knowledge as a means of hallucinating data along with appropriate targets from past distributions. We call this technique, phantom sampling.We show that phantom sampling helps avoid catastrophic forgetting during incremental learning. Using an implementation based on deep neural networks, we demonstrate that phantom sampling dramatically avoids catastrophic forgetting. We apply these strategies to competitive multi-class incremental learning of deep neural networks. Using various benchmark datasets and through our strategy, we demonstrate that strict incremental learning could be achieved. We further put our strategy to test on challenging cases, including cross-domain increments and incrementing on a novel label space. We also propose a trivial extension to unbounded-continual learning and identify potential for future development.
Efficient Approximate Solutions to Mutual Information Based Global Feature Selection
Jun 23, 2017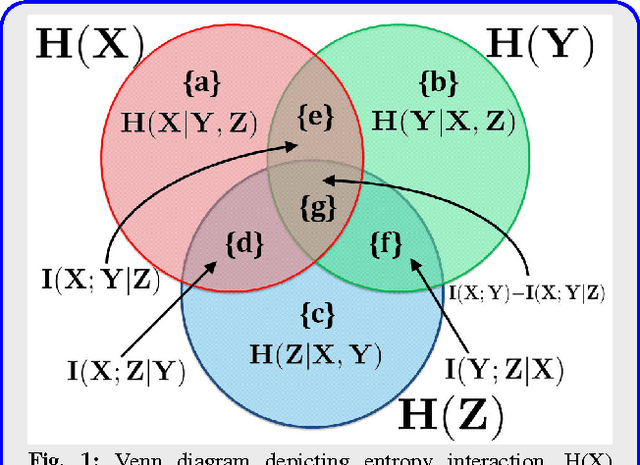
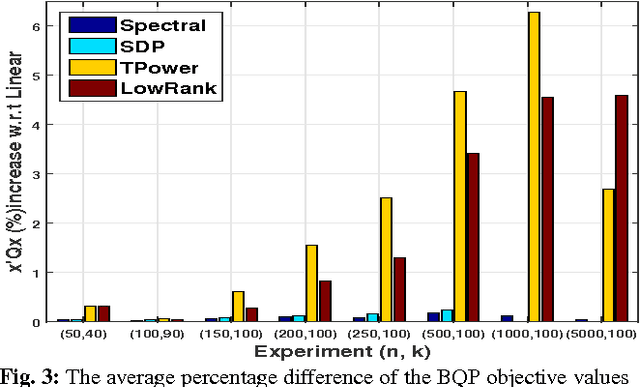
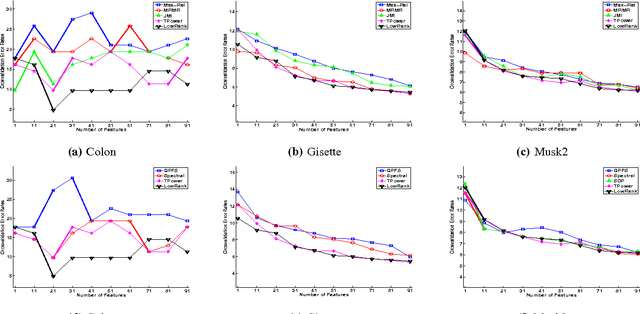
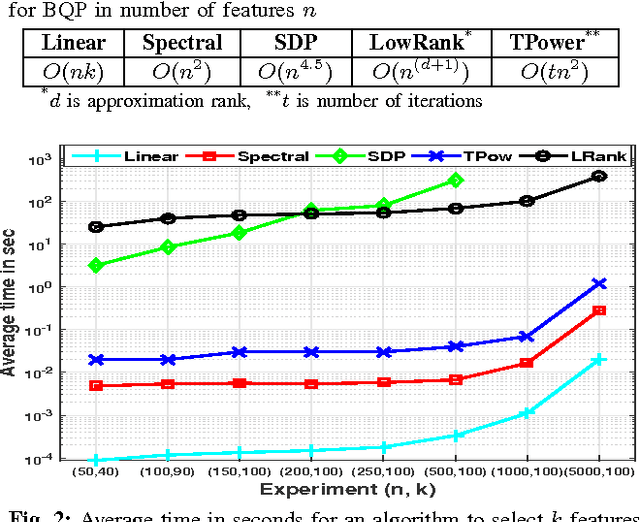
Mutual Information (MI) is often used for feature selection when developing classifier models. Estimating the MI for a subset of features is often intractable. We demonstrate, that under the assumptions of conditional independence, MI between a subset of features can be expressed as the Conditional Mutual Information (CMI) between pairs of features. But selecting features with the highest CMI turns out to be a hard combinatorial problem. In this work, we have applied two unique global methods, Truncated Power Method (TPower) and Low Rank Bilinear Approximation (LowRank), to solve the feature selection problem. These algorithms provide very good approximations to the NP-hard CMI based feature selection problem. We experimentally demonstrate the effectiveness of these procedures across multiple datasets and compare them with existing MI based global and iterative feature selection procedures.
Multiresolution Match Kernels for Gesture Video Classification
Jun 23, 2017
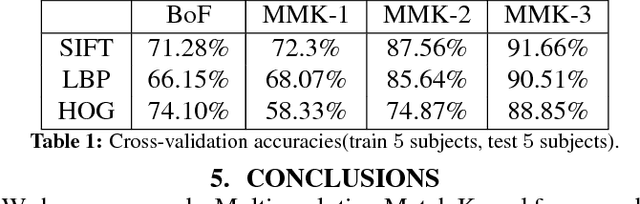
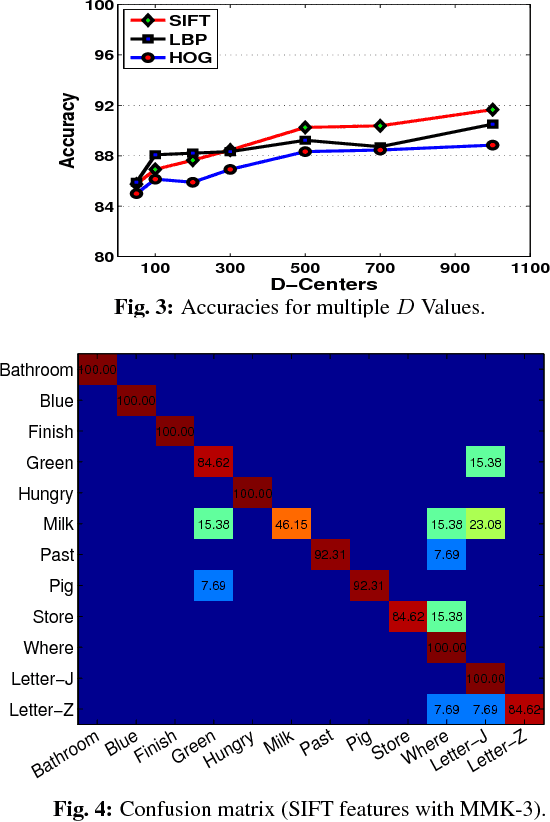
The emergence of depth imaging technologies like the Microsoft Kinect has renewed interest in computational methods for gesture classification based on videos. For several years now, researchers have used the Bag-of-Features (BoF) as a primary method for generation of feature vectors from video data for recognition of gestures. However, the BoF method is a coarse representation of the information in a video, which often leads to poor similarity measures between videos. Besides, when features extracted from different spatio-temporal locations in the video are pooled to create histogram vectors in the BoF method, there is an intrinsic loss of their original locations in space and time. In this paper, we propose a new Multiresolution Match Kernel (MMK) for video classification, which can be considered as a generalization of the BoF method. We apply this procedure to hand gesture classification based on RGB-D videos of the American Sign Language(ASL) hand gestures and our results show promise and usefulness of this new method.
Model Selection with Nonlinear Embedding for Unsupervised Domain Adaptation
Jun 23, 2017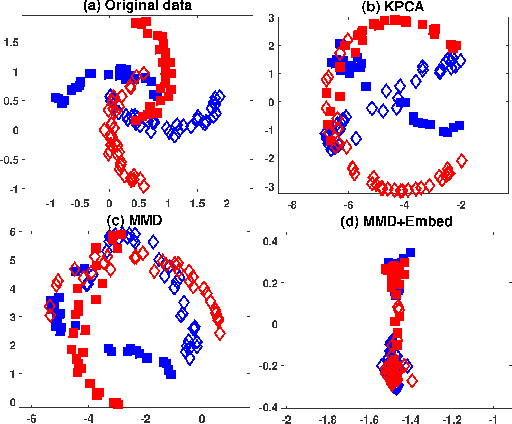
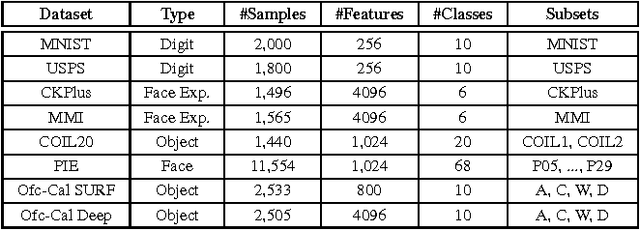

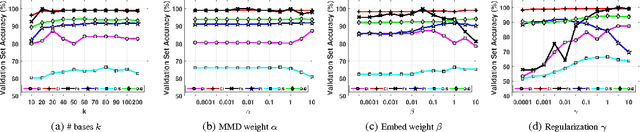
Domain adaptation deals with adapting classifiers trained on data from a source distribution, to work effectively on data from a target distribution. In this paper, we introduce the Nonlinear Embedding Transform (NET) for unsupervised domain adaptation. The NET reduces cross-domain disparity through nonlinear domain alignment. It also embeds the domain-aligned data such that similar data points are clustered together. This results in enhanced classification. To determine the parameters in the NET model (and in other unsupervised domain adaptation models), we introduce a validation procedure by sampling source data points that are similar in distribution to the target data. We test the NET and the validation procedure using popular image datasets and compare the classification results across competitive procedures for unsupervised domain adaptation.
Coupled Support Vector Machines for Supervised Domain Adaptation
Jun 22, 2017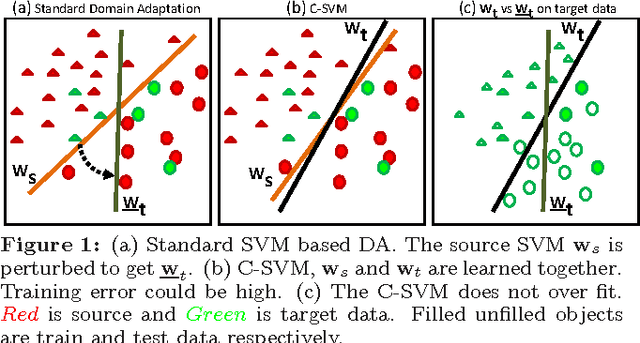
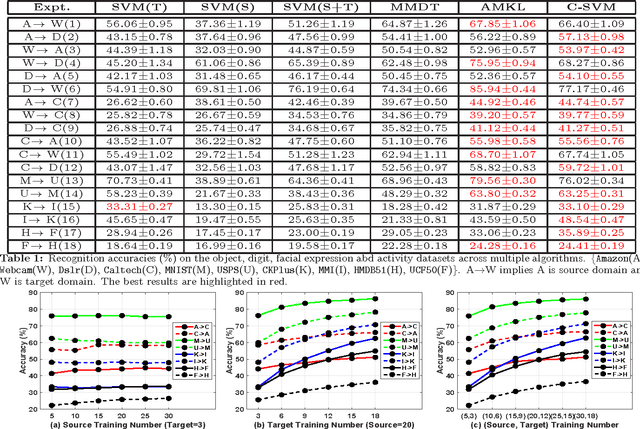
Popular domain adaptation (DA) techniques learn a classifier for the target domain by sampling relevant data points from the source and combining it with the target data. We present a Support Vector Machine (SVM) based supervised DA technique, where the similarity between source and target domains is modeled as the similarity between their SVM decision boundaries. We couple the source and target SVMs and reduce the model to a standard single SVM. We test the Coupled-SVM on multiple datasets and compare our results with other popular SVM based DA approaches.
Nonlinear Embedding Transform for Unsupervised Domain Adaptation
Jun 22, 2017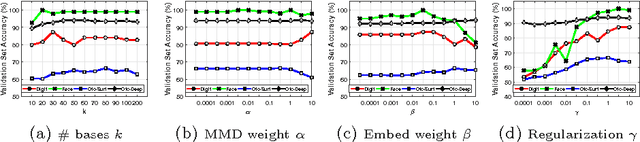
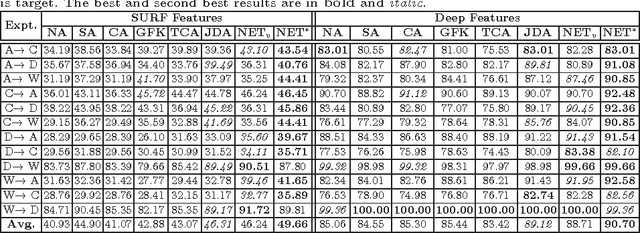
The problem of domain adaptation (DA) deals with adapting classifier models trained on one data distribution to different data distributions. In this paper, we introduce the Nonlinear Embedding Transform (NET) for unsupervised DA by combining domain alignment along with similarity-based embedding. We also introduce a validation procedure to estimate the model parameters for the NET algorithm using the source data. Comprehensive evaluations on multiple vision datasets demonstrate that the NET algorithm outperforms existing competitive procedures for unsupervised DA.
Deep Hashing Network for Unsupervised Domain Adaptation
Jun 22, 2017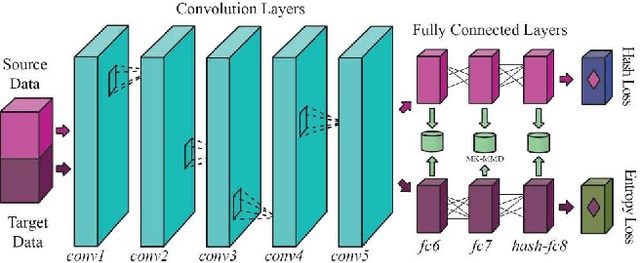


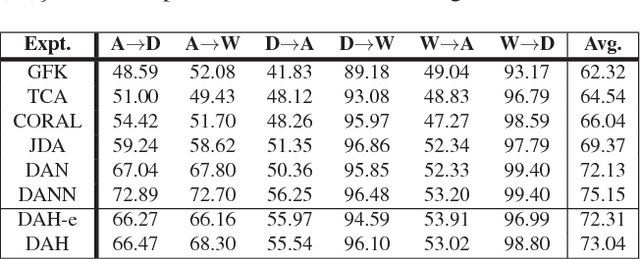
In recent years, deep neural networks have emerged as a dominant machine learning tool for a wide variety of application domains. However, training a deep neural network requires a large amount of labeled data, which is an expensive process in terms of time, labor and human expertise. Domain adaptation or transfer learning algorithms address this challenge by leveraging labeled data in a different, but related source domain, to develop a model for the target domain. Further, the explosive growth of digital data has posed a fundamental challenge concerning its storage and retrieval. Due to its storage and retrieval efficiency, recent years have witnessed a wide application of hashing in a variety of computer vision applications. In this paper, we first introduce a new dataset, Office-Home, to evaluate domain adaptation algorithms. The dataset contains images of a variety of everyday objects from multiple domains. We then propose a novel deep learning framework that can exploit labeled source data and unlabeled target data to learn informative hash codes, to accurately classify unseen target data. To the best of our knowledge, this is the first research effort to exploit the feature learning capabilities of deep neural networks to learn representative hash codes to address the domain adaptation problem. Our extensive empirical studies on multiple transfer tasks corroborate the usefulness of the framework in learning efficient hash codes which outperform existing competitive baselines for unsupervised domain adaptation.