 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeinterwhen: A Generalizable Framework for Verifiable Reasoning with Test-time Monitors
Feb 05, 2026We present a test-time verification framework, interwhen, that ensures that the output of a reasoning model is valid wrt. a given set of verifiers. Verified reasoning is an important goal in high-stakes scenarios such as deploying agents in the physical world or in domains such as law and finance. However, current techniques either rely on the generate-test paradigm that verifies only after the final answer is produced, or verify partial output through a step-extraction paradigm where the task execution is externally broken down into structured steps. The former is inefficient while the latter artificially restricts a model's problem solving strategies. Instead, we propose to verify a model's reasoning trace as-is, taking full advantage of a model's reasoning capabilities while verifying and steering the model's output only when needed. The key idea is meta-prompting, identifying the verifiable properties that any partial solution should satisfy and then prompting the model to follow a custom format in its trace such that partial outputs can be easily parsed and checked. We consider both self-verification and external verification and find that interwhen provides a useful abstraction to provide feedback and steer reasoning models in each case. Using self-verification, interwhen obtains state-of-the-art results on early stopping reasoning models, without any loss in accuracy. Using external verifiers, interwhen obtains 10 p.p. improvement in accuracy over test-time scaling methods, while ensuring 100% soundness and being 4x more efficient. The code for interwhen is available at https://github.com/microsoft/interwhen
Where does an LLM begin computing an instruction?
Nov 19, 2025Following an instruction involves distinct sub-processes, such as reading content, reading the instruction, executing it, and producing an answer. We ask where, along the layer stack, instruction following begins, the point where reading gives way to doing. We introduce three simple datasets (Key-Value, Quote Attribution, Letter Selection) and two hop compositions of these tasks. Using activation patching on minimal-contrast prompt pairs, we measure a layer-wise flip rate that indicates when substituting selected residual activations changes the predicted answer. Across models in the Llama family, we observe an inflection point, which we term onset, where interventions that change predictions before this point become largely ineffective afterward. Multi-hop compositions show a similar onset location. These results provide a simple, replicable way to locate where instruction following begins and to compare this location across tasks and model sizes.
BiasConnect: Investigating Bias Interactions in Text-to-Image Models
Mar 12, 2025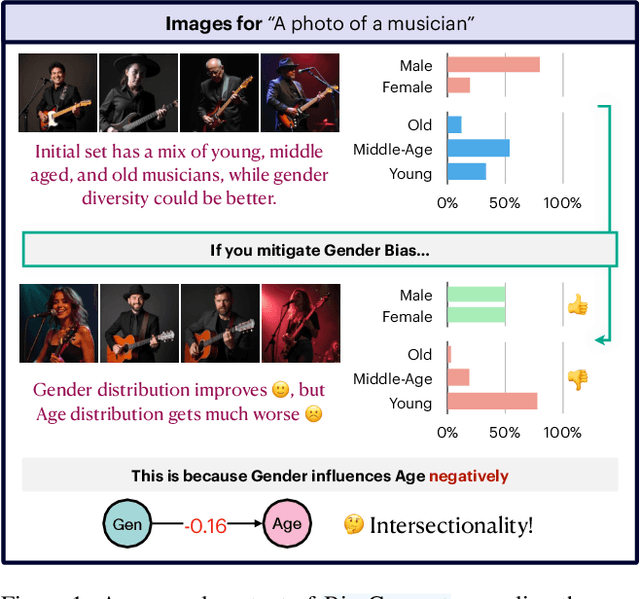
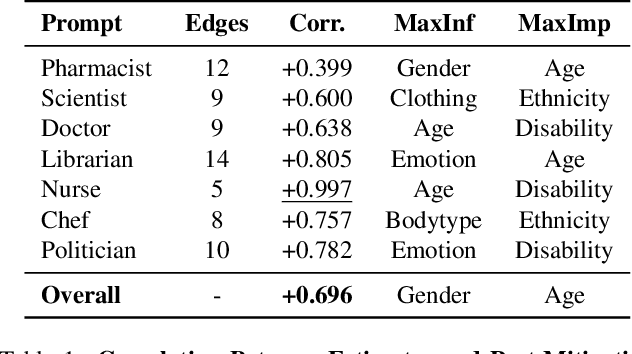
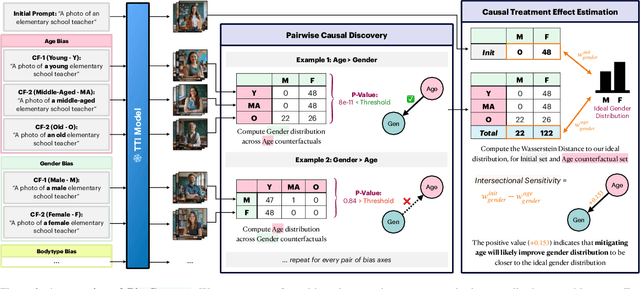
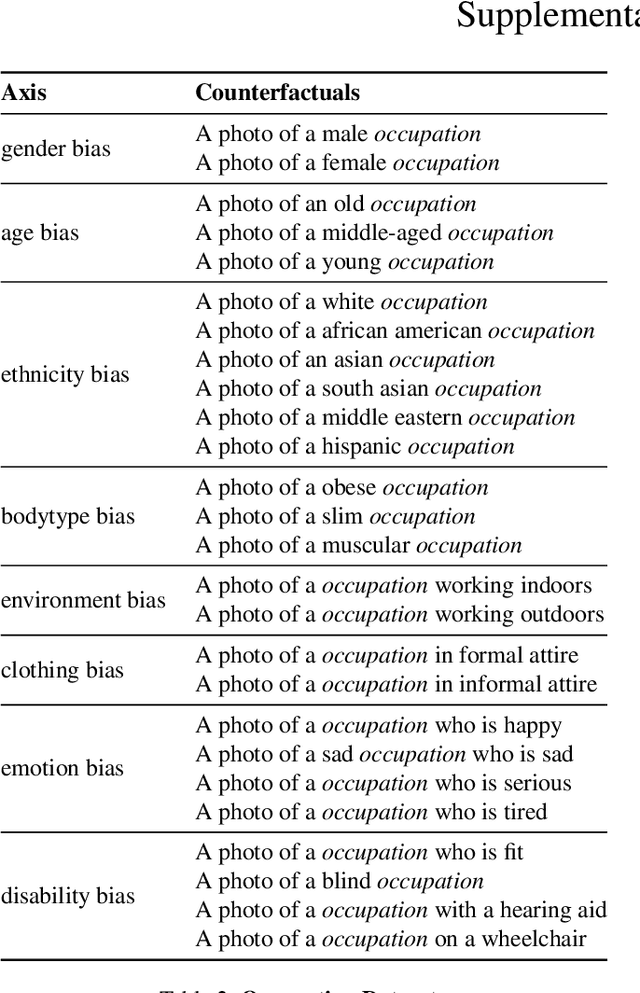
The biases exhibited by Text-to-Image (TTI) models are often treated as if they are independent, but in reality, they may be deeply interrelated. Addressing bias along one dimension, such as ethnicity or age, can inadvertently influence another dimension, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. In this paper, we aim to address these questions by introducing BiasConnect, a novel tool designed to analyze and quantify bias interactions in TTI models. Our approach leverages a counterfactual-based framework to generate pairwise causal graphs that reveals the underlying structure of bias interactions for the given text prompt. Additionally, our method provides empirical estimates that indicate how other bias dimensions shift toward or away from an ideal distribution when a given bias is modified. Our estimates have a strong correlation (+0.69) with the interdependency observations post bias mitigation. We demonstrate the utility of BiasConnect for selecting optimal bias mitigation axes, comparing different TTI models on the dependencies they learn, and understanding the amplification of intersectional societal biases in TTI models.
Walking the Web of Concept-Class Relationships in Incrementally Trained Interpretable Models
Feb 27, 2025



Concept-based methods have emerged as a promising direction to develop interpretable neural networks in standard supervised settings. However, most works that study them in incremental settings assume either a static concept set across all experiences or assume that each experience relies on a distinct set of concepts. In this work, we study concept-based models in a more realistic, dynamic setting where new classes may rely on older concepts in addition to introducing new concepts themselves. We show that concepts and classes form a complex web of relationships, which is susceptible to degradation and needs to be preserved and augmented across experiences. We introduce new metrics to show that existing concept-based models cannot preserve these relationships even when trained using methods to prevent catastrophic forgetting, since they cannot handle forgetting at concept, class, and concept-class relationship levels simultaneously. To address these issues, we propose a novel method - MuCIL - that uses multimodal concepts to perform classification without increasing the number of trainable parameters across experiences. The multimodal concepts are aligned to concepts provided in natural language, making them interpretable by design. Through extensive experimentation, we show that our approach obtains state-of-the-art classification performance compared to other concept-based models, achieving over 2$\times$ the classification performance in some cases. We also study the ability of our model to perform interventions on concepts, and show that it can localize visual concepts in input images, providing post-hoc interpretations.
Learning Causal Attributions in Neural Networks: Beyond Direct Effects
Mar 24, 2023
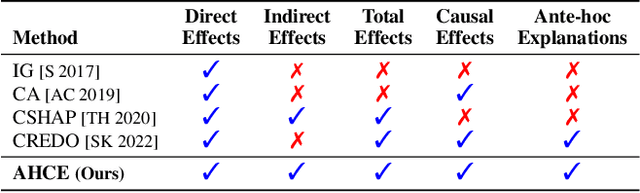
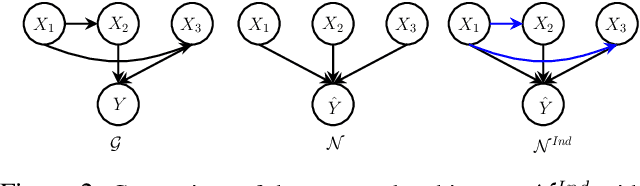

There has been a growing interest in capturing and maintaining causal relationships in Neural Network (NN) models in recent years. We study causal approaches to estimate and maintain input-output attributions in NN models in this work. In particular, existing efforts in this direction assume independence among input variables (by virtue of the NN architecture), and hence study only direct causal effects. Viewing an NN as a structural causal model (SCM), we instead focus on going beyond direct effects, introduce edges among input features, and provide a simple yet effective methodology to capture and maintain direct and indirect causal effects while training an NN model. We also propose effective approximation strategies to quantify causal attributions in high dimensional data. Our wide range of experiments on synthetic and real-world datasets show that the proposed ante-hoc method learns causal attributions for both direct and indirect causal effects close to the ground truth effects.
Towards Estimating Transferability using Hard Subsets
Jan 17, 2023
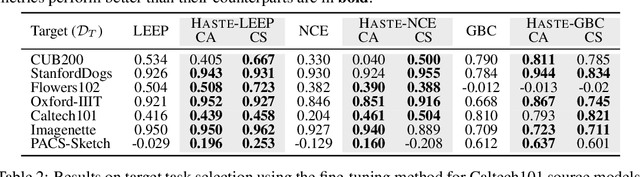
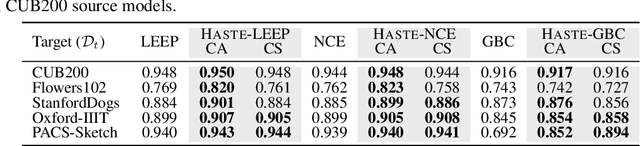
As transfer learning techniques are increasingly used to transfer knowledge from the source model to the target task, it becomes important to quantify which source models are suitable for a given target task without performing computationally expensive fine tuning. In this work, we propose HASTE (HArd Subset TransfErability), a new strategy to estimate the transferability of a source model to a particular target task using only a harder subset of target data. By leveraging the internal and output representations of model, we introduce two techniques, one class agnostic and another class specific, to identify harder subsets and show that HASTE can be used with any existing transferability metric to improve their reliability. We further analyze the relation between HASTE and the optimal average log likelihood as well as negative conditional entropy and empirically validate our theoretical bounds. Our experimental results across multiple source model architectures, target datasets, and transfer learning tasks show that HASTE modified metrics are consistently better or on par with the state of the art transferability metrics.
On Conditioning the Input Noise for Controlled Image Generation with Diffusion Models
May 08, 2022
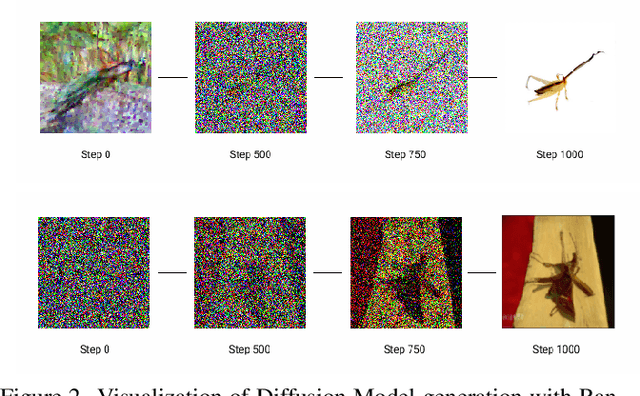


Conditional image generation has paved the way for several breakthroughs in image editing, generating stock photos and 3-D object generation. This continues to be a significant area of interest with the rise of new state-of-the-art methods that are based on diffusion models. However, diffusion models provide very little control over the generated image, which led to subsequent works exploring techniques like classifier guidance, that provides a way to trade off diversity with fidelity. In this work, we explore techniques to condition diffusion models with carefully crafted input noise artifacts. This allows generation of images conditioned on semantic attributes. This is different from existing approaches that input Gaussian noise and further introduce conditioning at the diffusion model's inference step. Our experiments over several examples and conditional settings show the potential of our approach.
Feature Generation for Long-tail Classification
Nov 10, 2021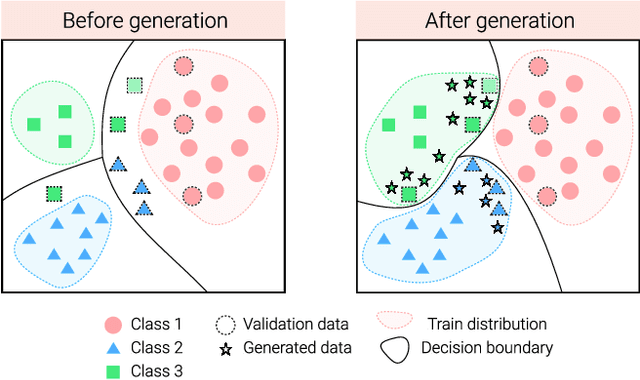
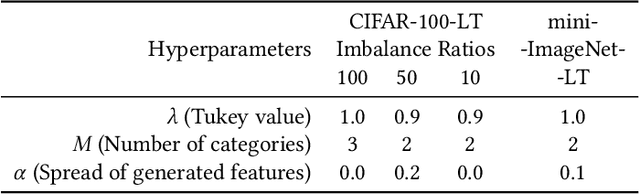
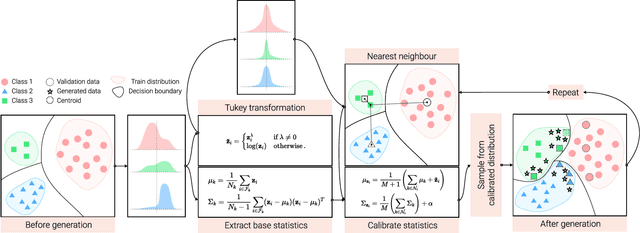
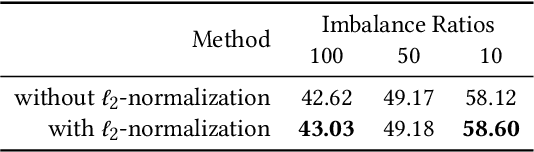
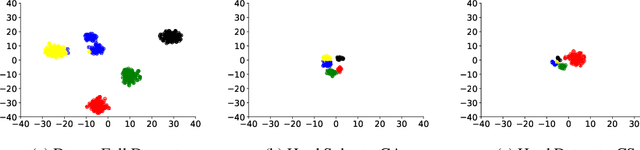
The visual world naturally exhibits an imbalance in the number of object or scene instances resulting in a \emph{long-tailed distribution}. This imbalance poses significant challenges for classification models based on deep learning. Oversampling instances of the tail classes attempts to solve this imbalance. However, the limited visual diversity results in a network with poor representation ability. A simple counter to this is decoupling the representation and classifier networks and using oversampling only to train the classifier. In this paper, instead of repeatedly re-sampling the same image (and thereby features), we explore a direction that attempts to generate meaningful features by estimating the tail category's distribution. Inspired by ideas from recent work on few-shot learning, we create calibrated distributions to sample additional features that are subsequently used to train the classifier. Through several experiments on the CIFAR-100-LT (long-tail) dataset with varying imbalance factors and on mini-ImageNet-LT (long-tail), we show the efficacy of our approach and establish a new state-of-the-art. We also present a qualitative analysis of generated features using t-SNE visualizations and analyze the nearest neighbors used to calibrate the tail class distributions. Our code is available at https://github.com/rahulvigneswaran/TailCalibX.
Attentive Semantic Video Generation using Captions
Oct 21, 2017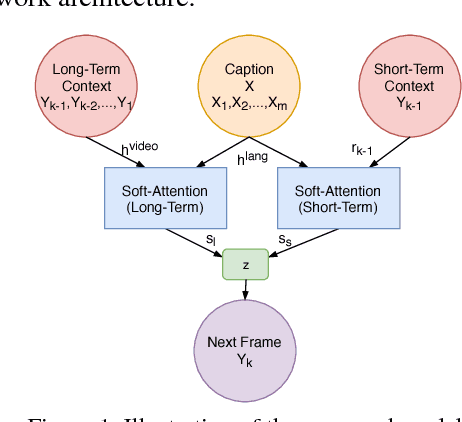
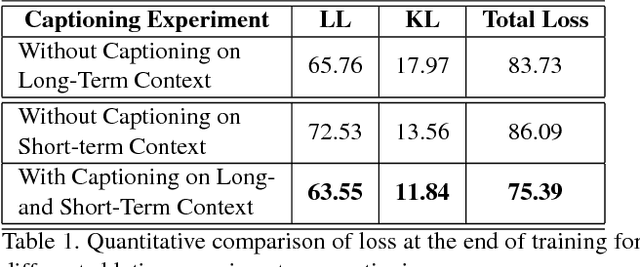
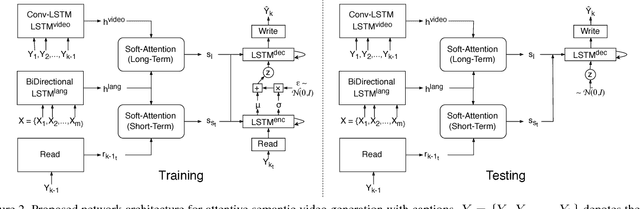

This paper proposes a network architecture to perform variable length semantic video generation using captions. We adopt a new perspective towards video generation where we allow the captions to be combined with the long-term and short-term dependencies between video frames and thus generate a video in an incremental manner. Our experiments demonstrate our network architecture's ability to distinguish between objects, actions and interactions in a video and combine them to generate videos for unseen captions. The network also exhibits the capability to perform spatio-temporal style transfer when asked to generate videos for a sequence of captions. We also show that the network's ability to learn a latent representation allows it generate videos in an unsupervised manner and perform other tasks such as action recognition. (Accepted in International Conference in Computer Vision (ICCV) 2017)
Sync-DRAW: Automatic Video Generation using Deep Recurrent Attentive Architectures
Oct 21, 2017
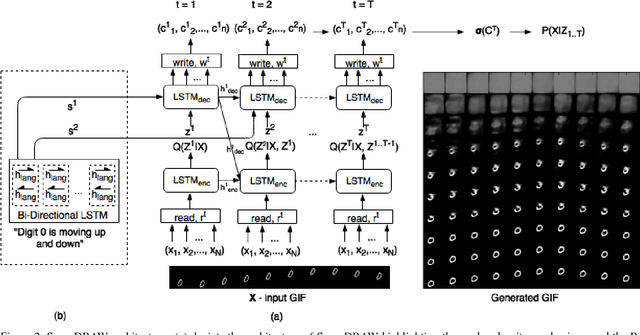


This paper introduces a novel approach for generating videos called Synchronized Deep Recurrent Attentive Writer (Sync-DRAW). Sync-DRAW can also perform text-to-video generation which, to the best of our knowledge, makes it the first approach of its kind. It combines a Variational Autoencoder~(VAE) with a Recurrent Attention Mechanism in a novel manner to create a temporally dependent sequence of frames that are gradually formed over time. The recurrent attention mechanism in Sync-DRAW attends to each individual frame of the video in sychronization, while the VAE learns a latent distribution for the entire video at the global level. Our experiments with Bouncing MNIST, KTH and UCF-101 suggest that Sync-DRAW is efficient in learning the spatial and temporal information of the videos and generates frames with high structural integrity, and can generate videos from simple captions on these datasets. (Accepted as oral paper in ACM-Multimedia 2017)