 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinted Frames: Question Framing Blinds Vision-Language Models
Mar 19, 2026Vision-Language Models (VLMs) have been shown to be blind, often underutilizing their visual inputs even on tasks that require visual reasoning. In this work, we demonstrate that VLMs are selectively blind. They modulate the amount of attention applied to visual inputs based on linguistic framing even when alternative framings demand identical visual reasoning. Using visual attention as a probe, we quantify how framing alters both the amount and distribution of attention over the image. Constrained framings, such as multiple choice and yes/no, induce substantially lower attention to image context compared to open-ended, reduce focus on task-relevant regions, and shift attention towards uninformative tokens. We further demonstrate that this attention misallocation is the principal cause of degraded accuracy and cross-framing inconsistency. Building on this mechanistic insight, we introduce a lightweight prompt-tuning method using learnable tokens that encourages the robust, visually grounded attention patterns observed in open-ended settings, improving visual grounding and improving performance across framings.
Alignment-Aware Model Adaptation via Feedback-Guided Optimization
Feb 02, 2026Fine-tuning is the primary mechanism for adapting foundation models to downstream tasks; however, standard approaches largely optimize task objectives in isolation and do not account for secondary yet critical alignment objectives (e.g., safety and hallucination avoidance). As a result, downstream fine-tuning can degrade alignment and fail to correct pre-existing misaligned behavior. We propose an alignment-aware fine-tuning framework that integrates feedback from an external alignment signal through policy-gradient-based regularization. Our method introduces an adaptive gating mechanism that dynamically balances supervised and alignment-driven gradients on a per-sample basis, prioritizing uncertain or misaligned cases while allowing well-aligned examples to follow standard supervised updates. The framework further learns abstention behavior for fully misaligned inputs, incorporating conservative responses directly into the fine-tuned model. Experiments on general and domain-specific instruction-tuning benchmarks demonstrate consistent reductions in harmful and hallucinated outputs without sacrificing downstream task performance. Additional analyses show robustness to adversarial fine-tuning, prompt-based attacks, and unsafe initializations, establishing adaptively gated alignment optimization as an effective approach for alignment-preserving and alignment-recovering model adaptation.
Do LLMs Benefit from User and Item Embeddings in Recommendation Tasks?
Jan 08, 2026Large Language Models (LLMs) have emerged as promising recommendation systems, offering novel ways to model user preferences through generative approaches. However, many existing methods often rely solely on text semantics or incorporate collaborative signals in a limited manner, typically using only user or item embeddings. These methods struggle to handle multiple item embeddings representing user history, reverting to textual semantics and neglecting richer collaborative information. In this work, we propose a simple yet effective solution that projects user and item embeddings, learned from collaborative filtering, into the LLM token space via separate lightweight projector modules. A finetuned LLM then conditions on these projected embeddings alongside textual tokens to generate recommendations. Preliminary results show that this design effectively leverages structured user-item interaction data, improves recommendation performance over text-only LLM baselines, and offers a practical path for bridging traditional recommendation systems with modern LLMs.
ChartGaze: Enhancing Chart Understanding in LVLMs with Eye-Tracking Guided Attention Refinement
Sep 16, 2025Charts are a crucial visual medium for communicating and representing information. While Large Vision-Language Models (LVLMs) have made progress on chart question answering (CQA), the task remains challenging, particularly when models attend to irrelevant regions of the chart. In this work, we present ChartGaze, a new eye-tracking dataset that captures human gaze patterns during chart reasoning tasks. Through a systematic comparison of human and model attention, we find that LVLMs often diverge from human gaze, leading to reduced interpretability and accuracy. To address this, we propose a gaze-guided attention refinement that aligns image-text attention with human fixations. Our approach improves both answer accuracy and attention alignment, yielding gains of up to 2.56 percentage points across multiple models. These results demonstrate the promise of incorporating human gaze to enhance both the reasoning quality and interpretability of chart-focused LVLMs.
RewardRank: Optimizing True Learning-to-Rank Utility
Aug 19, 2025
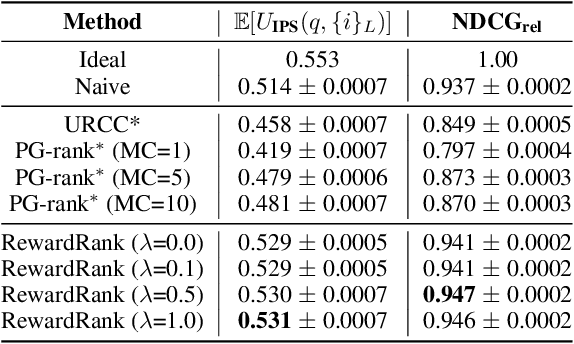
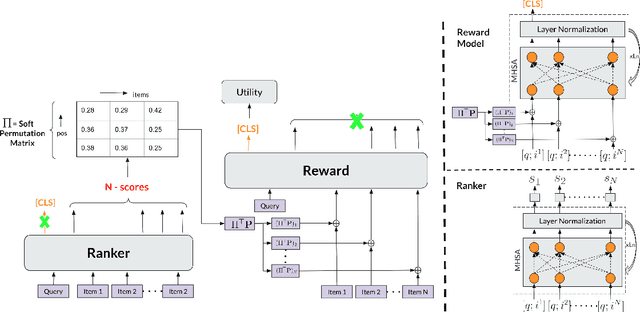
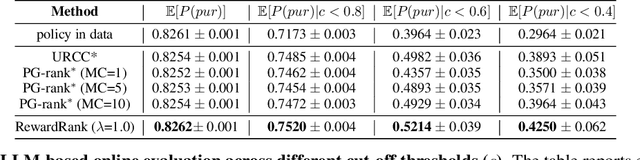
Traditional ranking systems rely on proxy loss functions that assume simplistic user behavior, such as users preferring a rank list where items are sorted by hand-crafted relevance. However, real-world user interactions are influenced by complex behavioral biases, including position bias, brand affinity, decoy effects, and similarity aversion, which these objectives fail to capture. As a result, models trained on such losses often misalign with actual user utility, such as the probability of any click or purchase across the ranked list. In this work, we propose a data-driven framework for modeling user behavior through counterfactual reward learning. Our method, RewardRank, first trains a deep utility model to estimate user engagement for entire item permutations using logged data. Then, a ranking policy is optimized to maximize predicted utility via differentiable soft permutation operators, enabling end-to-end training over the space of factual and counterfactual rankings. To address the challenge of evaluation without ground-truth for unseen permutations, we introduce two automated protocols: (i) $\textit{KD-Eval}$, using a position-aware oracle for counterfactual reward estimation, and (ii) $\textit{LLM-Eval}$, which simulates user preferences via large language models. Experiments on large-scale benchmarks, including Baidu-ULTR and the Amazon KDD Cup datasets, demonstrate that our approach consistently outperforms strong baselines, highlighting the effectiveness of modeling user behavior dynamics for utility-optimized ranking. Our code is available at: https://github.com/GauravBh1010tt/RewardRank
Mitigate One, Skew Another? Tackling Intersectional Biases in Text-to-Image Models
May 22, 2025The biases exhibited by text-to-image (TTI) models are often treated as independent, though in reality, they may be deeply interrelated. Addressing bias along one dimension - such as ethnicity or age - can inadvertently affect another, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. To address this, we introduce BiasConnect, a novel tool for analyzing and quantifying bias interactions in TTI models. BiasConnect uses counterfactual interventions along different bias axes to reveal the underlying structure of these interactions and estimates the effect of mitigating one bias axis on another. These estimates show strong correlation (+0.65) with observed post-mitigation outcomes. Building on BiasConnect, we propose InterMit, an intersectional bias mitigation algorithm guided by user-defined target distributions and priority weights. InterMit achieves lower bias (0.33 vs. 0.52) with fewer mitigation steps (2.38 vs. 3.15 average steps), and yields superior image quality compared to traditional techniques. Although our implementation is training-free, InterMit is modular and can be integrated with many existing debiasing approaches for TTI models, making it a flexible and extensible solution.
Revealing Weaknesses in Text Watermarking Through Self-Information Rewrite Attacks
May 08, 2025Text watermarking aims to subtly embed statistical signals into text by controlling the Large Language Model (LLM)'s sampling process, enabling watermark detectors to verify that the output was generated by the specified model. The robustness of these watermarking algorithms has become a key factor in evaluating their effectiveness. Current text watermarking algorithms embed watermarks in high-entropy tokens to ensure text quality. In this paper, we reveal that this seemingly benign design can be exploited by attackers, posing a significant risk to the robustness of the watermark. We introduce a generic efficient paraphrasing attack, the Self-Information Rewrite Attack (SIRA), which leverages the vulnerability by calculating the self-information of each token to identify potential pattern tokens and perform targeted attack. Our work exposes a widely prevalent vulnerability in current watermarking algorithms. The experimental results show SIRA achieves nearly 100% attack success rates on seven recent watermarking methods with only 0.88 USD per million tokens cost. Our approach does not require any access to the watermark algorithms or the watermarked LLM and can seamlessly transfer to any LLM as the attack model, even mobile-level models. Our findings highlight the urgent need for more robust watermarking.
ADiff4TPP: Asynchronous Diffusion Models for Temporal Point Processes
Apr 29, 2025


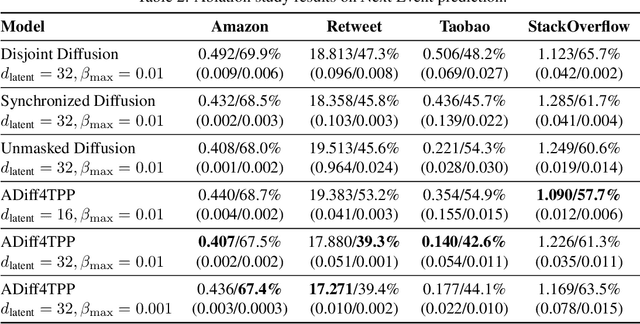
This work introduces a novel approach to modeling temporal point processes using diffusion models with an asynchronous noise schedule. At each step of the diffusion process, the noise schedule injects noise of varying scales into different parts of the data. With a careful design of the noise schedules, earlier events are generated faster than later ones, thus providing stronger conditioning for forecasting the more distant future. We derive an objective to effectively train these models for a general family of noise schedules based on conditional flow matching. Our method models the joint distribution of the latent representations of events in a sequence and achieves state-of-the-art results in predicting both the next inter-event time and event type on benchmark datasets. Additionally, it flexibly accommodates varying lengths of observation and prediction windows in different forecasting settings by adjusting the starting and ending points of the generation process. Finally, our method shows superior performance in long-horizon prediction tasks, outperforming existing baseline methods.
The Power of One: A Single Example is All it Takes for Segmentation in VLMs
Mar 13, 2025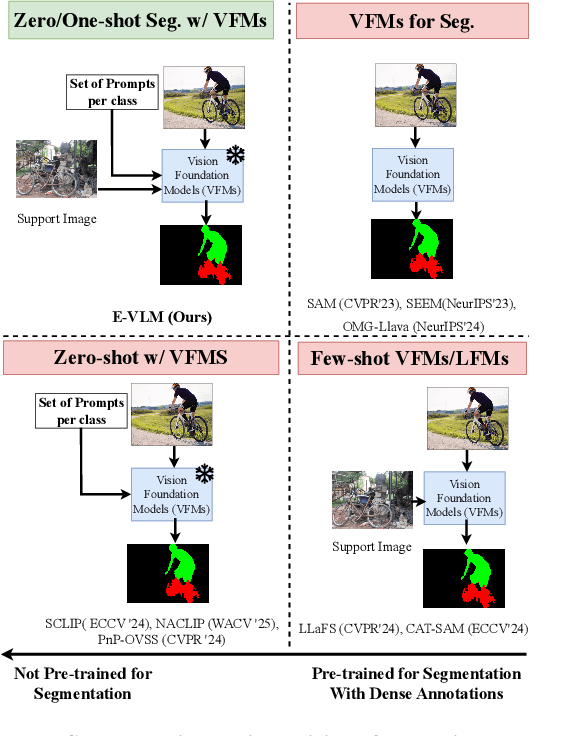
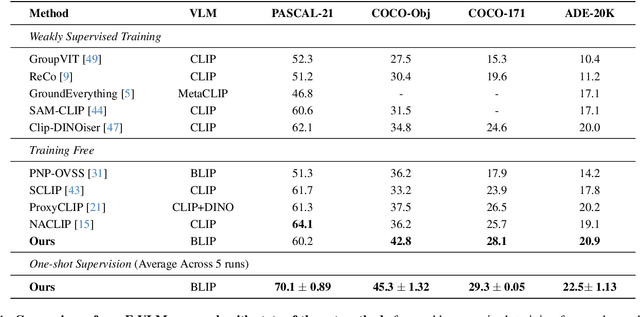
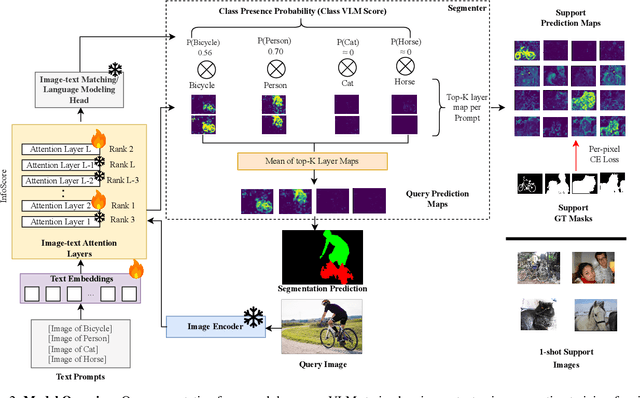
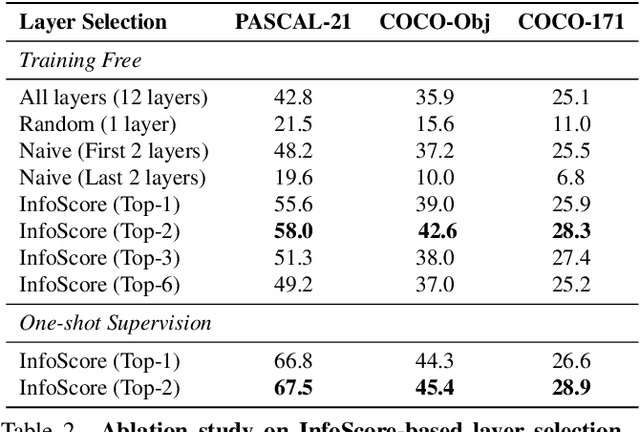
Large-scale vision-language models (VLMs), trained on extensive datasets of image-text pairs, exhibit strong multimodal understanding capabilities by implicitly learning associations between textual descriptions and image regions. This emergent ability enables zero-shot object detection and segmentation, using techniques that rely on text-image attention maps, without necessarily training on abundant labeled segmentation datasets. However, performance of such methods depends heavily on prompt engineering and manually selected layers or head choices for the attention layers. In this work, we demonstrate that, rather than relying solely on textual prompts, providing a single visual example for each category and fine-tuning the text-to-image attention layers and embeddings significantly improves the performance. Additionally, we propose learning an ensemble through few-shot fine-tuning across multiple layers and/or prompts. An entropy-based ranking and selection mechanism for text-to-image attention layers is proposed to identify the top-performing layers without the need for segmentation labels. This eliminates the need for hyper-parameter selection of text-to-image attention layers, providing a more flexible and scalable solution for open-vocabulary segmentation. We show that this approach yields strong zero-shot performance, further enhanced through fine-tuning with a single visual example. Moreover, we demonstrate that our method and findings are general and can be applied across various vision-language models (VLMs).
BiasConnect: Investigating Bias Interactions in Text-to-Image Models
Mar 12, 2025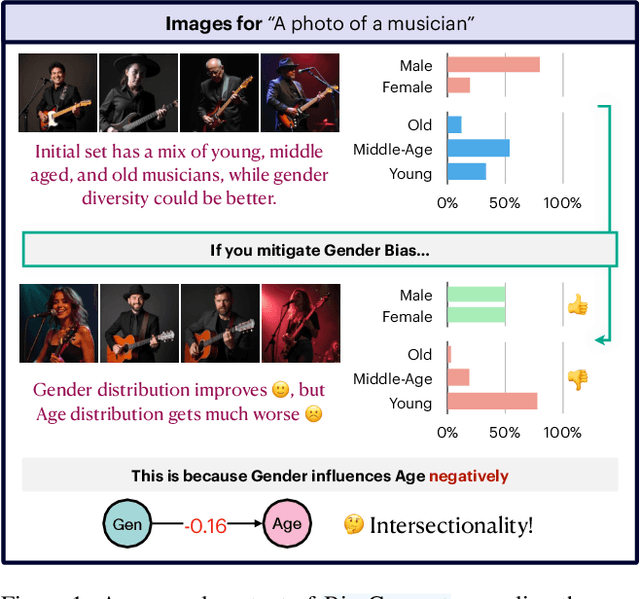
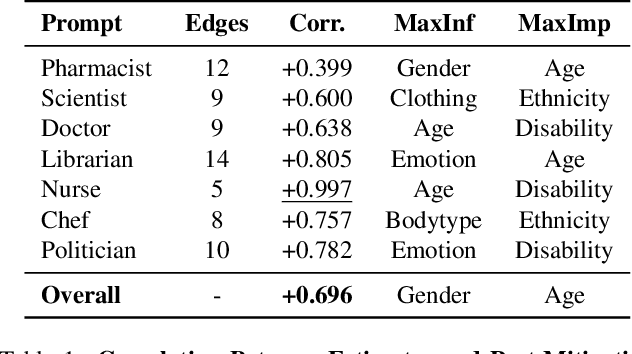
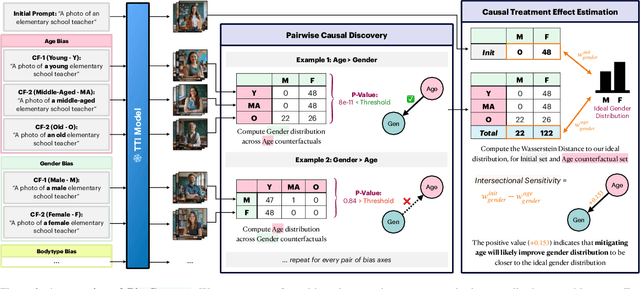
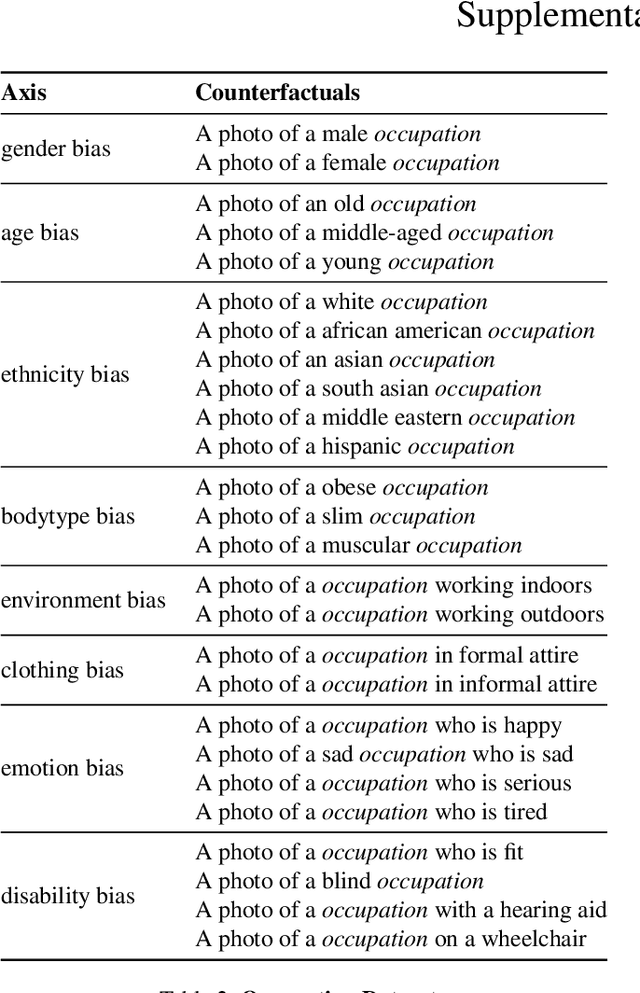
The biases exhibited by Text-to-Image (TTI) models are often treated as if they are independent, but in reality, they may be deeply interrelated. Addressing bias along one dimension, such as ethnicity or age, can inadvertently influence another dimension, like gender, either mitigating or exacerbating existing disparities. Understanding these interdependencies is crucial for designing fairer generative models, yet measuring such effects quantitatively remains a challenge. In this paper, we aim to address these questions by introducing BiasConnect, a novel tool designed to analyze and quantify bias interactions in TTI models. Our approach leverages a counterfactual-based framework to generate pairwise causal graphs that reveals the underlying structure of bias interactions for the given text prompt. Additionally, our method provides empirical estimates that indicate how other bias dimensions shift toward or away from an ideal distribution when a given bias is modified. Our estimates have a strong correlation (+0.69) with the interdependency observations post bias mitigation. We demonstrate the utility of BiasConnect for selecting optimal bias mitigation axes, comparing different TTI models on the dependencies they learn, and understanding the amplification of intersectional societal biases in TTI models.