 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeight Control and Optimal Torque Planning for Jumping With Wheeled-Bipedal Robots
May 05, 2026This paper mainly studies the accurate height jumping control of wheeled-bipedal robots based on torque planning and energy consumption optimization. Due to the characteristics of underactuated, nonlinear estimation, and instantaneous impact in the jumping process, accurate control of the wheeled-bipedal robot's jumping height is complicated. In reality, robots often jump at excessive height to ensure safety, causing additional motor loss, greater ground reaction force and more energy consumption. To solve this problem, a novel wheeled-bipedal jumping dynamical model(W-JBD) is proposed to achieve accurate height control. It performs well but not suitable for the real robot because the torque has a striking step. Therefore, the Bayesian optimization for torque planning method(BOTP) is proposed, which can obtain the optimal torque planning without accurate dynamic model and within few iterations. BOTP method can reduce 82.3% height error, 26.9% energy cost with continuous torque curve. This result is validated in the Webots simulation platform. Based on the torque curve obtained in the W-JBD model to narrow the searching space, BOTP can quickly converge (40 times on average). Cooperating W-JBD model and BOTP method, it is possible to achieve the height control of real robots with reasonable times of experiments.
What Has Been Overlooked in Contrastive Source-Free Domain Adaptation: Leveraging Source-Informed Latent Augmentation within Neighborhood Context
Dec 18, 2024Source-free domain adaptation (SFDA) involves adapting a model originally trained using a labeled dataset ({\em source domain}) to perform effectively on an unlabeled dataset ({\em target domain}) without relying on any source data during adaptation. This adaptation is especially crucial when significant disparities in data distributions exist between the two domains and when there are privacy concerns regarding the source model's training data. The absence of access to source data during adaptation makes it challenging to analytically estimate the domain gap. To tackle this issue, various techniques have been proposed, such as unsupervised clustering, contrastive learning, and continual learning. In this paper, we first conduct an extensive theoretical analysis of SFDA based on contrastive learning, primarily because it has demonstrated superior performance compared to other techniques. Motivated by the obtained insights, we then introduce a straightforward yet highly effective latent augmentation method tailored for contrastive SFDA. This augmentation method leverages the dispersion of latent features within the neighborhood of the query sample, guided by the source pre-trained model, to enhance the informativeness of positive keys. Our approach, based on a single InfoNCE-based contrastive loss, outperforms state-of-the-art SFDA methods on widely recognized benchmark datasets.
Ensemble diverse hypotheses and knowledge distillation for unsupervised cross-subject adaptation
Apr 15, 2022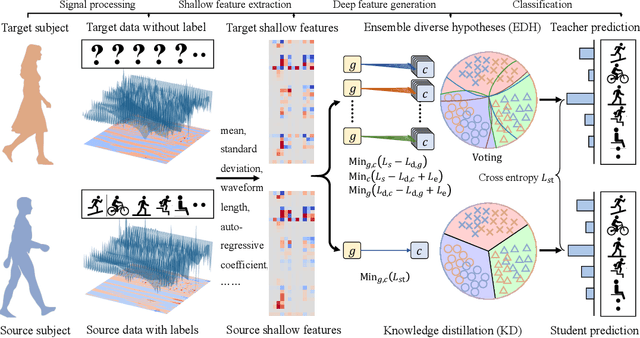
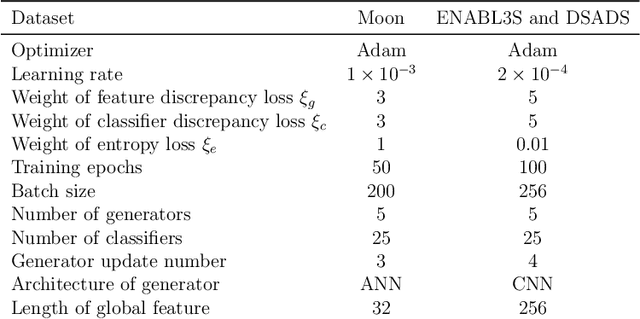
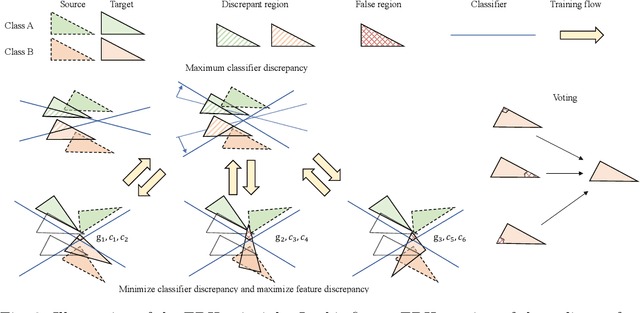
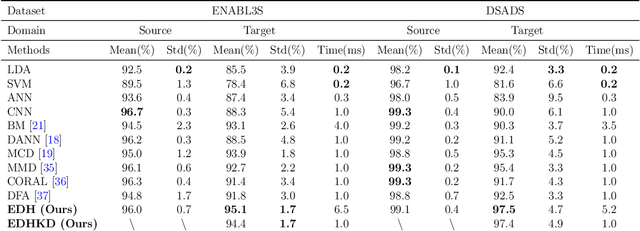
Recognizing human locomotion intent and activities is important for controlling the wearable robots while walking in complex environments. However, human-robot interface signals are usually user-dependent, which causes that the classifier trained on source subjects performs poorly on new subjects. To address this issue, this paper designs the ensemble diverse hypotheses and knowledge distillation (EDHKD) method to realize unsupervised cross-subject adaptation. EDH mitigates the divergence between labeled data of source subjects and unlabeled data of target subjects to accurately classify the locomotion modes of target subjects without labeling data. Compared to previous domain adaptation methods based on the single learner, which may only learn a subset of features from input signals, EDH can learn diverse features by incorporating multiple diverse feature generators and thus increases the accuracy and decreases the variance of classifying target data, but it sacrifices the efficiency. To solve this problem, EDHKD (student) distills the knowledge from the EDH (teacher) to a single network to remain efficient and accurate. The performance of the EDHKD is theoretically proved and experimentally validated on a 2D moon dataset and two public human locomotion datasets. Experimental results show that the EDHKD outperforms all other methods. The EDHKD can classify target data with 96.9%, 94.4%, and 97.4% average accuracy on the above three datasets with a short computing time (1 ms). Compared to a benchmark (BM) method, the EDHKD increases 1.3% and 7.1% average accuracy for classifying the locomotion modes of target subjects. The EDHKD also stabilizes the learning curves. Therefore, the EDHKD is significant for increasing the generalization ability and efficiency of the human intent prediction and human activity recognition system, which will improve human-robot interactions.
Preserving Domain Private Representation via Mutual Information Maximization
Jan 09, 2022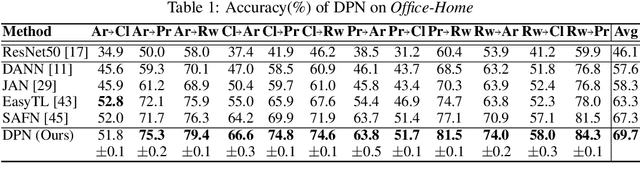
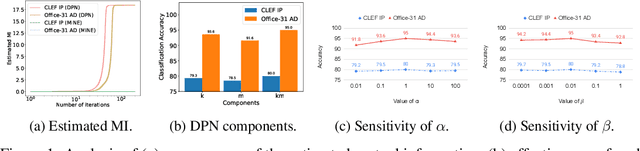
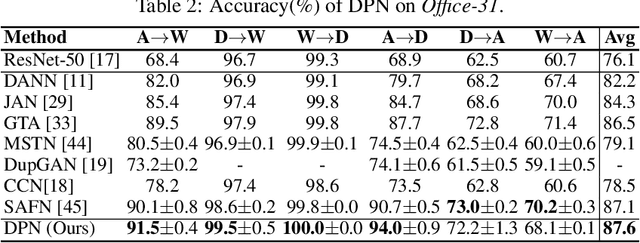
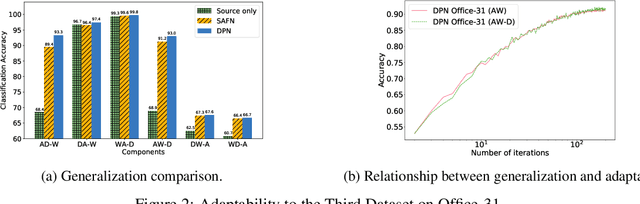
Recent advances in unsupervised domain adaptation have shown that mitigating the domain divergence by extracting the domain-invariant representation could significantly improve the generalization of a model to an unlabeled data domain. Nevertheless, the existing methods fail to effectively preserve the representation that is private to the label-missing domain, which could adversely affect the generalization. In this paper, we propose an approach to preserve such representation so that the latent distribution of the unlabeled domain could represent both the domain-invariant features and the individual characteristics that are private to the unlabeled domain. In particular, we demonstrate that maximizing the mutual information between the unlabeled domain and its latent space while mitigating the domain divergence can achieve such preservation. We also theoretically and empirically validate that preserving the representation that is private to the unlabeled domain is important and of necessity for the cross-domain generalization. Our approach outperforms state-of-the-art methods on several public datasets.
How does the structure embedded in learning policy affect learning quadruped locomotion?
Aug 29, 2020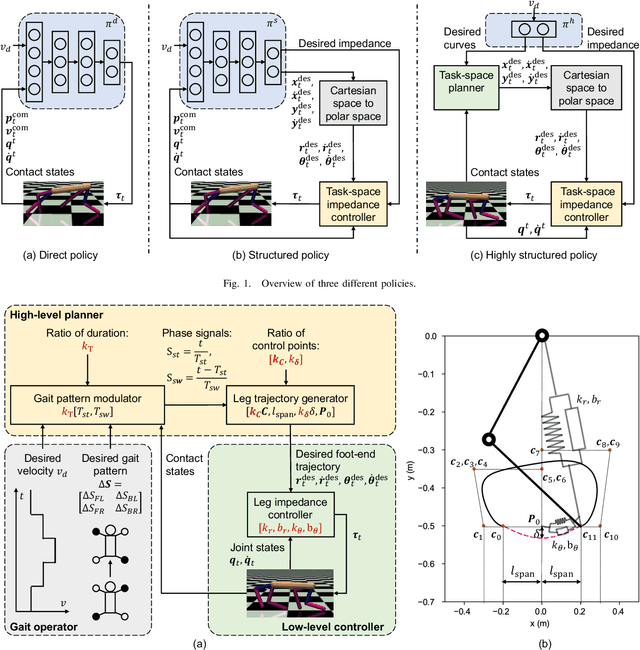
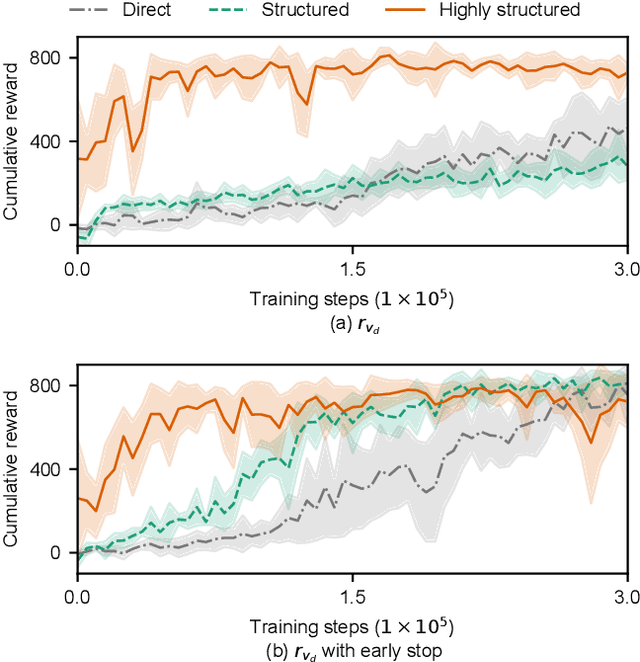
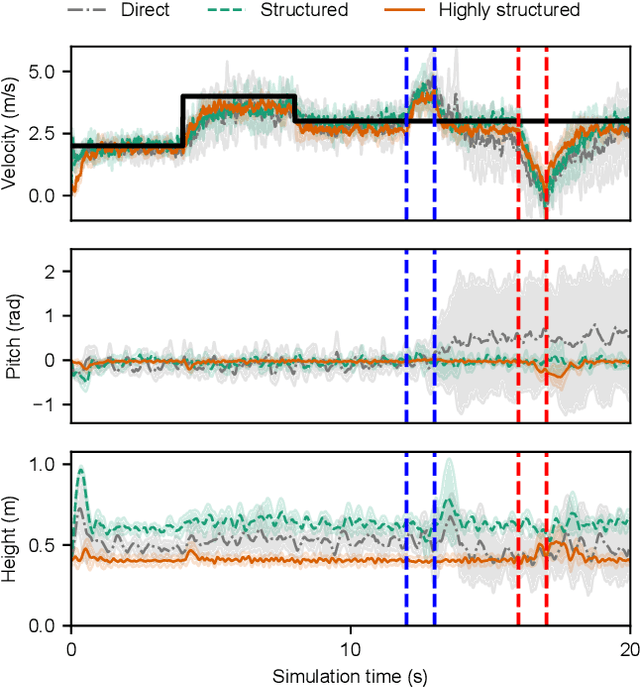
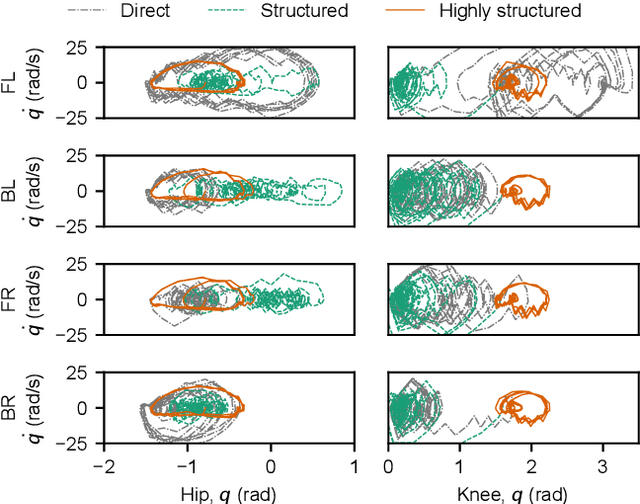
Reinforcement learning (RL) is a popular data-driven method that has demonstrated great success in robotics. Previous works usually focus on learning an end-to-end (direct) policy to directly output joint torques. While the direct policy seems convenient, the resultant performance may not meet our expectations. To improve its performance, more sophisticated reward functions or more structured policies can be utilized. This paper focuses on the latter because the structured policy is more intuitive and can inherit insights from previous model-based controllers. It is unsurprising that the structure, such as a better choice of the action space and constraints of motion trajectory, may benefit the training process and the final performance of the policy at the cost of generality, but the quantitative effect is still unclear. To analyze the effect of the structure quantitatively, this paper investigates three policies with different levels of structure in learning quadruped locomotion: a direct policy, a structured policy, and a highly structured policy. The structured policy is trained to learn a task-space impedance controller and the highly structured policy learns a controller tailored for trot running, which we adopt from previous work. To evaluate trained policies, we design a simulation experiment to track different desired velocities under force disturbances. Simulation results show that structured policy and highly structured policy require 1/3 and 3/4 fewer training steps than the direct policy to achieve a similar level of cumulative reward, and seem more robust and efficient than the direct policy. We highlight that the structure embedded in the policies significantly affects the overall performance of learning a complicated task when complex dynamics are involved, such as legged locomotion.
Off-policy Maximum Entropy Reinforcement Learning : Soft Actor-Critic with Advantage Weighted Mixture Policy(SAC-AWMP)
Feb 07, 2020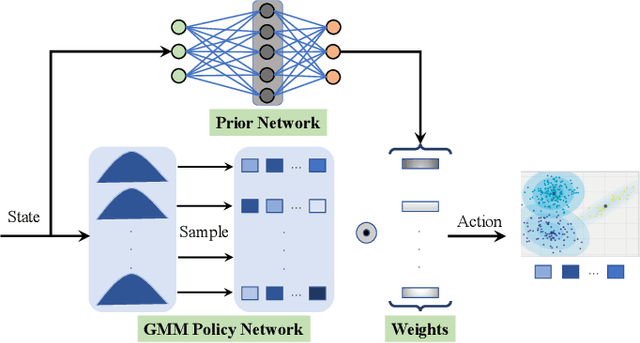
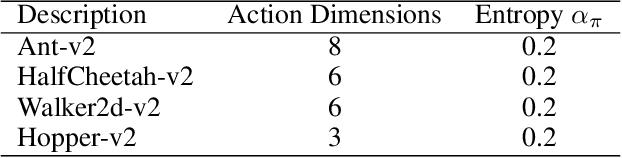

The optimal policy of a reinforcement learning problem is often discontinuous and non-smooth. I.e., for two states with similar representations, their optimal policies can be significantly different. In this case, representing the entire policy with a function approximator (FA) with shared parameters for all states maybe not desirable, as the generalization ability of parameters sharing makes representing discontinuous, non-smooth policies difficult. A common way to solve this problem, known as Mixture-of-Experts, is to represent the policy as the weighted sum of multiple components, where different components perform well on different parts of the state space. Following this idea and inspired by a recent work called advantage-weighted information maximization, we propose to learn for each state weights of these components, so that they entail the information of the state itself and also the preferred action learned so far for the state. The action preference is characterized via the advantage function. In this case, the weight of each component would only be large for certain groups of states whose representations are similar and preferred action representations are also similar. Therefore each component is easy to be represented. We call a policy parameterized in this way an Advantage Weighted Mixture Policy (AWMP) and apply this idea to improve soft-actor-critic (SAC), one of the most competitive continuous control algorithm. Experimental results demonstrate that SAC with AWMP clearly outperforms SAC in four commonly used continuous control tasks and achieve stable performance across different random seeds.
Teach Biped Robots to Walk via Gait Principles and Reinforcement Learning with Adversarial Critics
Oct 22, 2019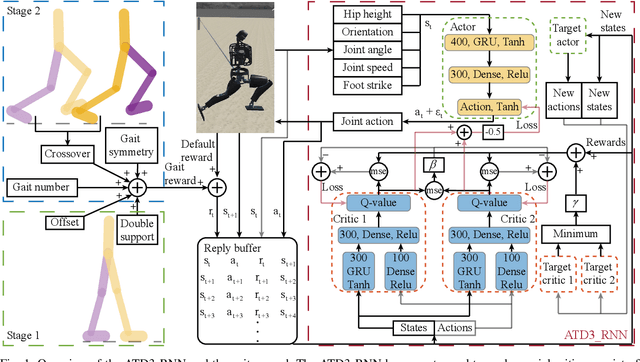
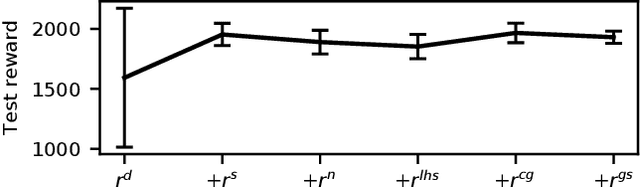
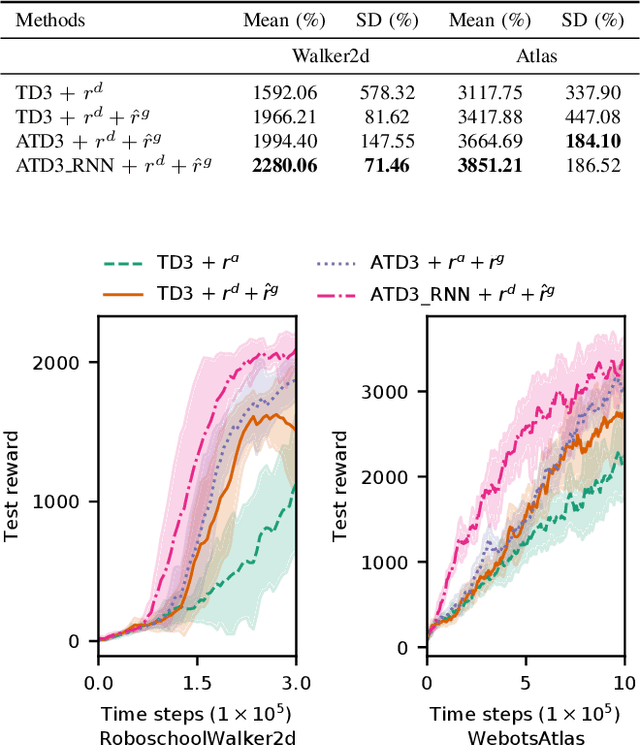
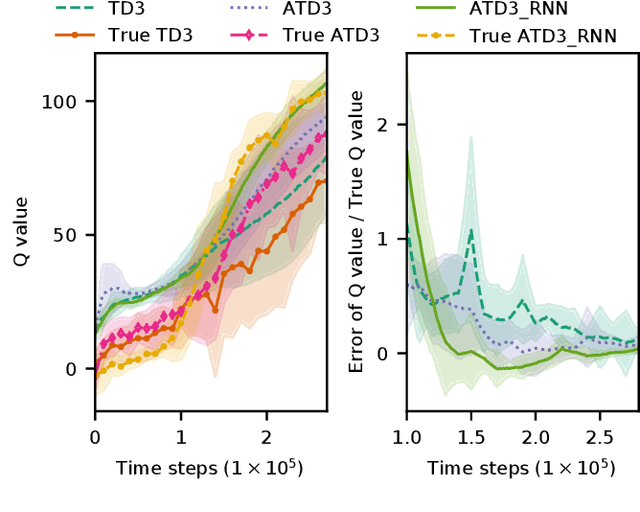
Controlling a biped robot to walk stably is a challenging task considering its nonlinearity and hybrid dynamics. Reinforcement learning can address these issues by directly mapping the observed states to optimal actions that maximize the cumulative reward. However, the local minima caused by unsuitable rewards and the overestimation of the cumulative reward impede the maximization of the cumulative reward. To increase the cumulative reward, this paper designs a gait reward based on walking principles, which compensates the local minima for unnatural motions. Besides, an Adversarial Twin Delayed Deep Deterministic (ATD3) policy gradient algorithm with a recurrent neural network (RNN) is proposed to further boost the cumulative reward by mitigating the overestimation of the cumulative reward. Experimental results in the Roboschool Walker2d and Webots Atlas simulators indicate that the test rewards increase by 23.50% and 9.63% after adding the gait reward. The test rewards further increase by 15.96% and 12.68% after using the ATD3_RNN, and the reason may be that the ATD3_RNN decreases the error of estimating cumulative reward from 19.86% to 3.35%. Besides, the cosine kinetic similarity between the human and the biped robot trained by the gait reward and ATD3_RNN increases by over 69.23%. Consequently, the designed gait reward and ATD3_RNN boost the cumulative reward and teach biped robots to walk better.
Sequential Decision Fusion for Environmental Classification in Assistive Walking
Apr 25, 2019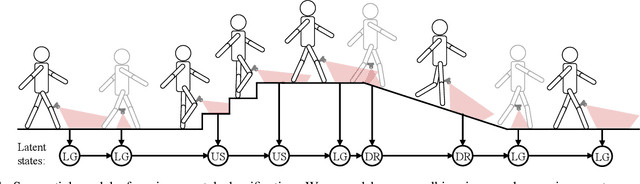
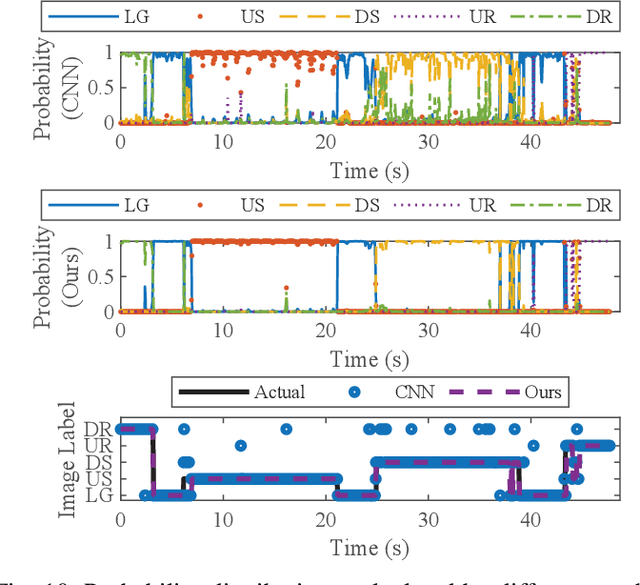
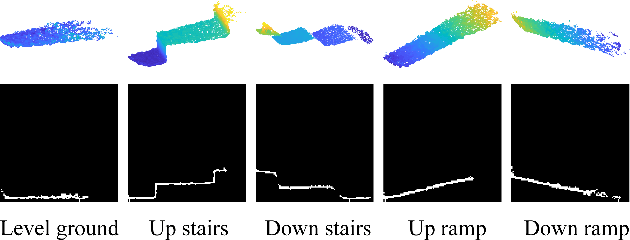
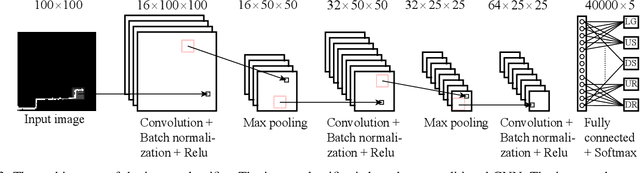
Powered prostheses are effective for helping amputees walk on level ground, but these devices are inconvenient to use in complex environments. Prostheses need to understand the motion intent of amputees to help them walk in complex environments. Recently, researchers have found that they can use vision sensors to classify environments and predict the motion intent of amputees. Previous researchers can classify environments accurately in the offline analysis, but they neglect to decrease the corresponding time delay. To increase the accuracy and decrease the time delay of environmental classification, we propose a new decision fusion method in this paper. We fuse sequential decisions of environmental classification by constructing a hidden Markov model and designing a transition probability matrix. We evaluate our method by inviting able-bodied subjects and amputees to implement indoor and outdoor experiments. Experimental results indicate that our method can classify environments more accurately and with less time delay than previous methods. Besides classifying environments, the proposed decision fusion method may also optimize sequential predictions of the human motion intent in the future.
Linked Dynamic Graph CNN: Learning on Point Cloud via Linking Hierarchical Features
Apr 22, 2019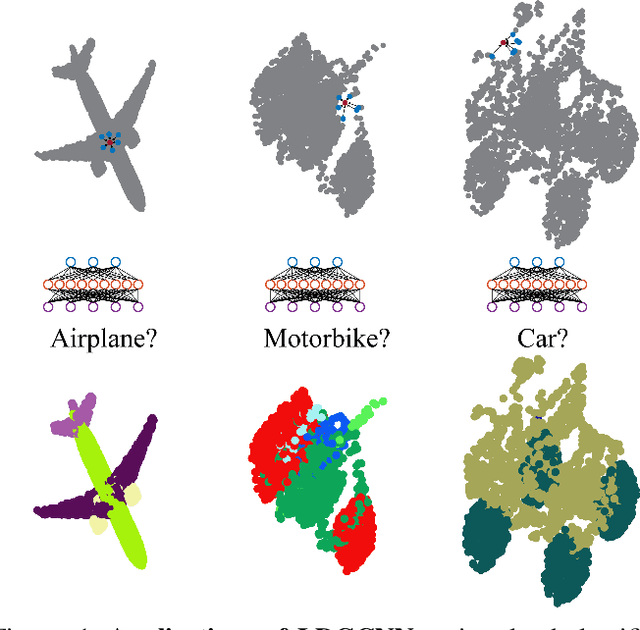


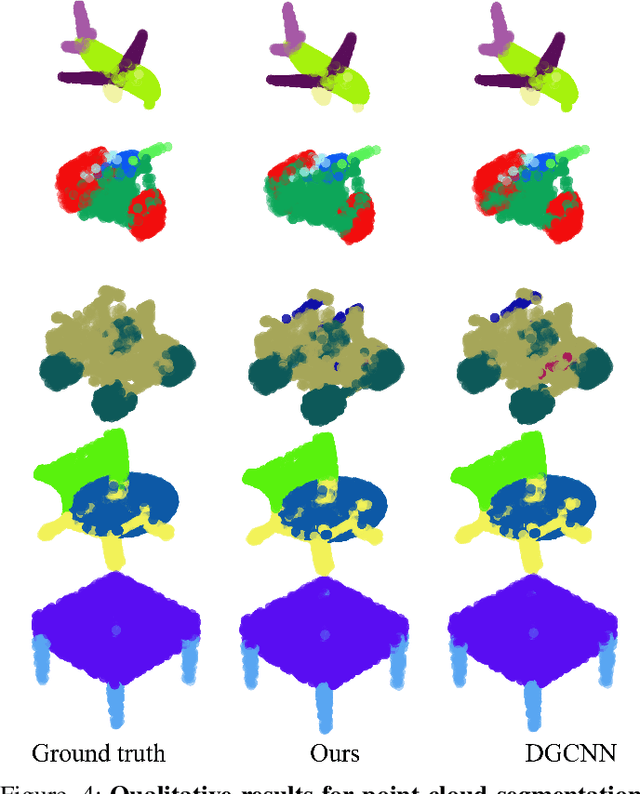
Learning on point cloud is eagerly in demand because the point cloud is a common type of geometric data and can aid robots to understand environments robustly. However, the point cloud is sparse, unstructured, and unordered, which cannot be recognized accurately by a traditional convolutional neural network (CNN) nor a recurrent neural network (RNN). Fortunately, a graph convolutional neural network (Graph CNN) can process sparse and unordered data. Hence, we propose a linked dynamic graph CNN (LDGCNN) to classify and segment point cloud directly in this paper. We remove the transformation network, link hierarchical features from dynamic graphs, freeze feature extractor, and retrain the classifier to increase the performance of LDGCNN. We explain our network using theoretical analysis and visualization. Through experiments, we show that the proposed LDGCNN achieves state-of-art performance on two standard datasets: ModelNet40 and ShapeNet.
Sensor Fusion for Predictive Control of Human-Prosthesis-Environment Dynamics in Assistive Walking: A Survey
Mar 22, 2019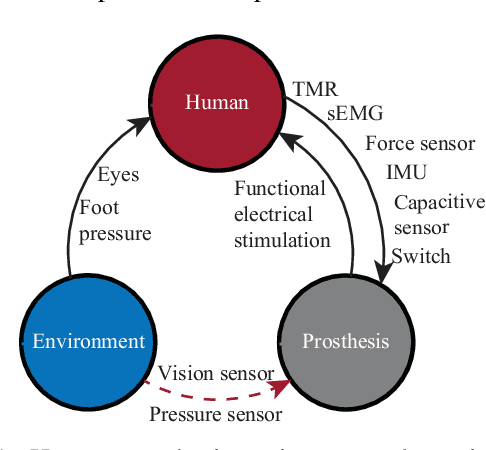
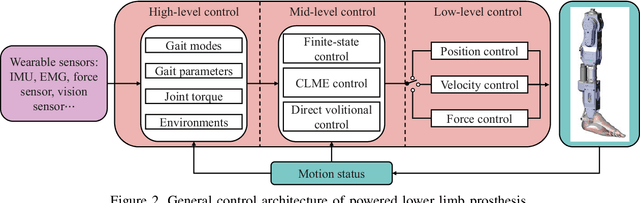
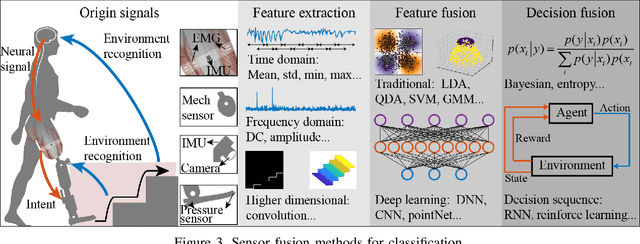
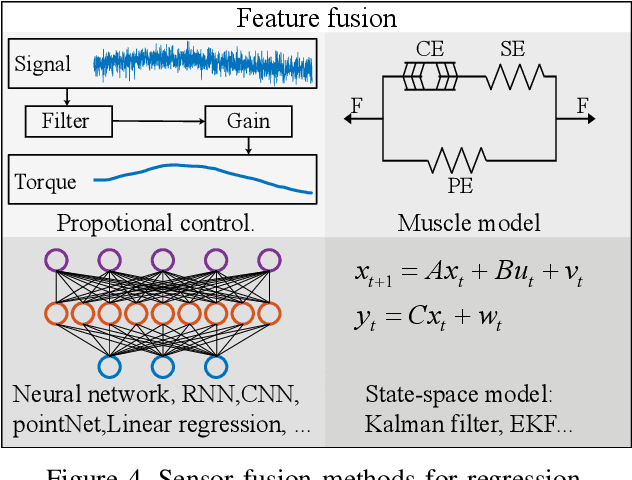
This survey paper concerns Sensor Fusion for Predictive Control of Human-Prosthesis-Environment Dynamics in Assistive Walking. The powered lower limb prosthesis can imitate the human limb motion and help amputees to recover the walking ability, but it is still a challenge for amputees to walk in complex environments with the powered prosthesis. Previous researchers mainly focused on the interaction between a human and the prosthesis without considering the environmental information, which can provide an environmental context for human-prosthesis interaction. Therefore, in this review, recent sensor fusion methods for the predictive control of human-prosthesis-environment dynamics in assistive walking are critically surveyed. In that backdrop, several pertinent research issues that need further investigation are presented. In particular, general controllers, comparison of sensors, and complete procedures of sensor fusion methods that are applicable in assistive walking are introduced. Also, possible sensor fusion research for human-prosthesis-environment dynamics is presented.