 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Shape-adaptive Assist-as-needed Rehabilitation Policy from Therapist-informed Input
Oct 06, 2025Therapist-in-the-loop robotic rehabilitation has shown great promise in enhancing rehabilitation outcomes by integrating the strengths of therapists and robotic systems. However, its broader adoption remains limited due to insufficient safe interaction and limited adaptation capability. This article proposes a novel telerobotics-mediated framework that enables therapists to intuitively and safely deliver assist-as-needed~(AAN) therapy based on two primary contributions. First, our framework encodes the therapist-informed corrective force into via-points in a latent space, allowing the therapist to provide only minimal assistance while encouraging patient maintaining own motion preferences. Second, a shape-adaptive ANN rehabilitation policy is learned to partially and progressively deform the reference trajectory for movement therapy based on encoded patient motion preferences and therapist-informed via-points. The effectiveness of the proposed shape-adaptive AAN strategy was validated on a telerobotic rehabilitation system using two representative tasks. The results demonstrate its practicality for remote AAN therapy and its superiority over two state-of-the-art methods in reducing corrective force and improving movement smoothness.
Learning Task-adaptive Quasi-stiffness Control for A Powered Transfemoral Prosthesis
Nov 25, 2023While significant advancements have been made in the mechanical and task-specific controller designs of powered transfemoral prostheses, developing a task-adaptive control framework that generalizes across various locomotion modes and terrain conditions remains an open problem. This study proposes a task-adaptive learning quasi-stiffness control framework for powered prostheses that generalizes across tasks, including the torque-angle relationship reconstruction part and the quasi-stiffness controller design part. Quasi-stiffness is defined as the slope of the human joint's torque-angle relationship. To accurately obtain the torque-angle relationship in a new task, a Gaussian Process Regression (GPR) model is introduced to predict the target features of the human joint's angle and torque in the task. Then a Kernelized Movement Primitives (KMP) is employed to reconstruct the torque-angle relationship of a new task from multiple human demonstrations and estimated target features. Based on the torque-angle relationship of the new task, a quasi-stiffness control approach is designed for a powered prosthesis. Finally, the proposed framework is validated through practical examples, including varying speed and incline walking tasks. The proposed framework has the potential to expand to variable walking tasks in daily life for the transfemoral amputees.
TeachingBot: Robot Teacher for Human Handwriting
Sep 21, 2023Teaching physical skills to humans requires one-on-one interaction between the teacher and the learner. With a shortage of human teachers, such a teaching mode faces the challenge of scaling up. Robots, with their replicable nature and physical capabilities, offer a solution. In this work, we present TeachingBot, a robotic system designed for teaching handwriting to human learners. We tackle two primary challenges in this teaching task: the adaptation to each learner's unique style and the creation of an engaging learning experience. TeachingBot captures the learner's style using a probabilistic learning approach based on the learner's handwriting. Then, based on the learned style, it provides physical guidance to human learners with variable impedance to make the learning experience engaging. Results from human-subject experiments based on 15 human subjects support the effectiveness of TeachingBot, demonstrating improved human learning outcomes compared to baseline methods. Additionally, we illustrate how TeachingBot customizes its teaching approach for individual learners, leading to enhanced overall engagement and effectiveness.
How does the structure embedded in learning policy affect learning quadruped locomotion?
Aug 29, 2020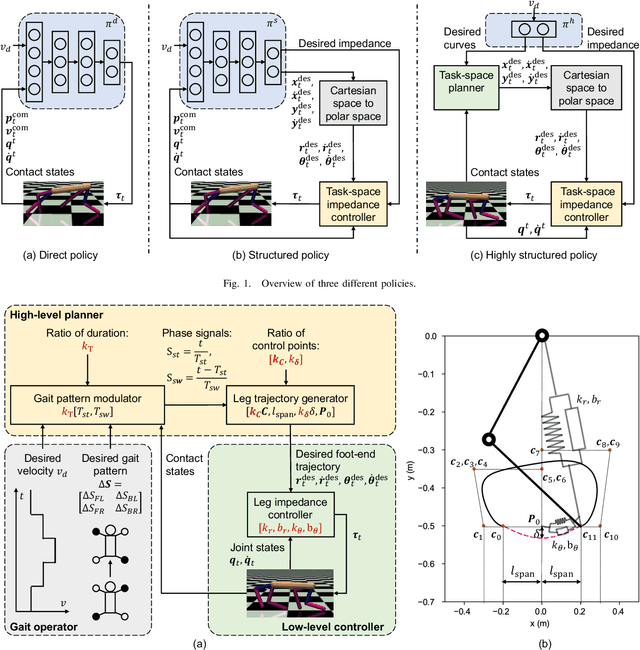
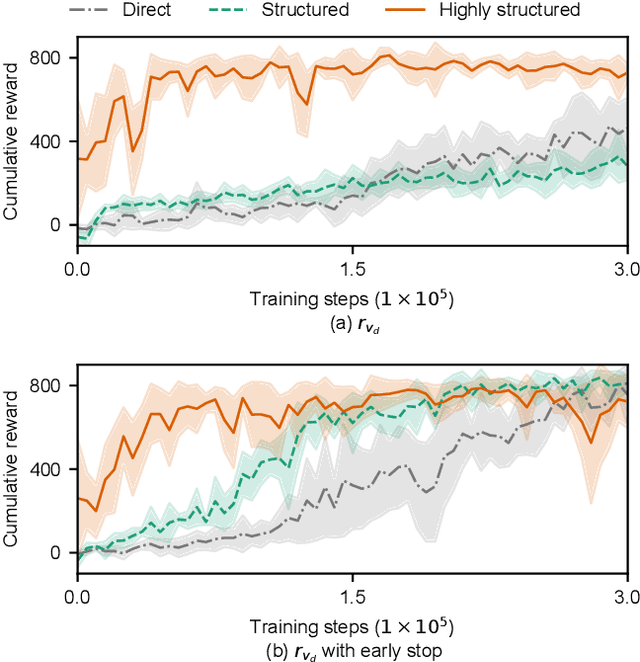
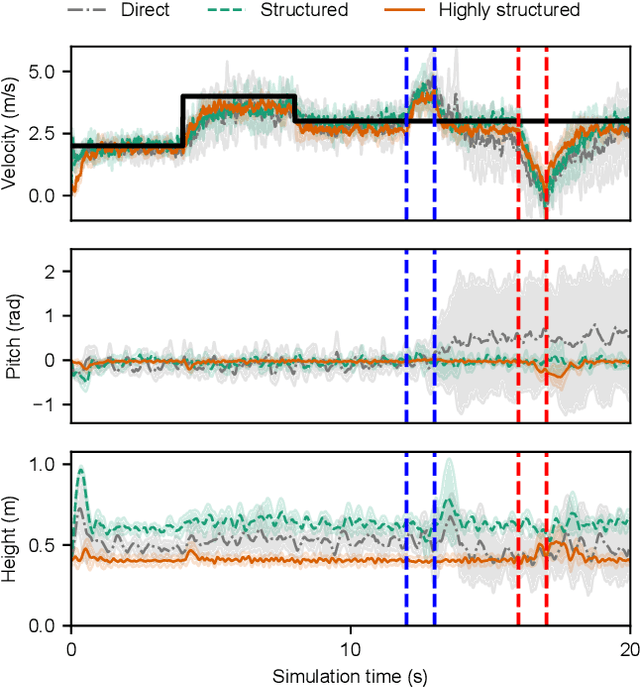
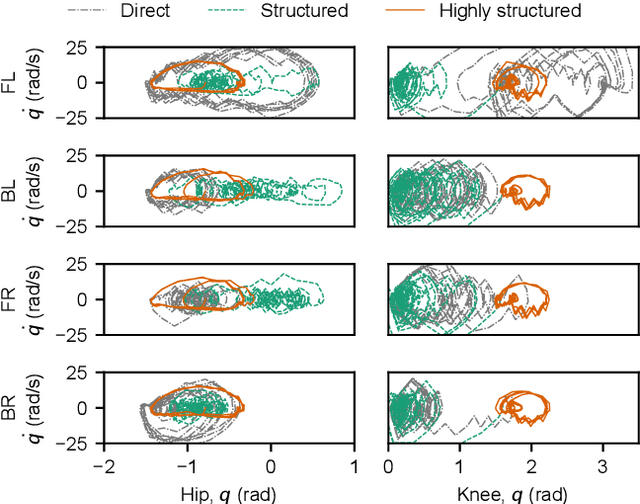
Reinforcement learning (RL) is a popular data-driven method that has demonstrated great success in robotics. Previous works usually focus on learning an end-to-end (direct) policy to directly output joint torques. While the direct policy seems convenient, the resultant performance may not meet our expectations. To improve its performance, more sophisticated reward functions or more structured policies can be utilized. This paper focuses on the latter because the structured policy is more intuitive and can inherit insights from previous model-based controllers. It is unsurprising that the structure, such as a better choice of the action space and constraints of motion trajectory, may benefit the training process and the final performance of the policy at the cost of generality, but the quantitative effect is still unclear. To analyze the effect of the structure quantitatively, this paper investigates three policies with different levels of structure in learning quadruped locomotion: a direct policy, a structured policy, and a highly structured policy. The structured policy is trained to learn a task-space impedance controller and the highly structured policy learns a controller tailored for trot running, which we adopt from previous work. To evaluate trained policies, we design a simulation experiment to track different desired velocities under force disturbances. Simulation results show that structured policy and highly structured policy require 1/3 and 3/4 fewer training steps than the direct policy to achieve a similar level of cumulative reward, and seem more robust and efficient than the direct policy. We highlight that the structure embedded in the policies significantly affects the overall performance of learning a complicated task when complex dynamics are involved, such as legged locomotion.
Off-policy Maximum Entropy Reinforcement Learning : Soft Actor-Critic with Advantage Weighted Mixture Policy(SAC-AWMP)
Feb 07, 2020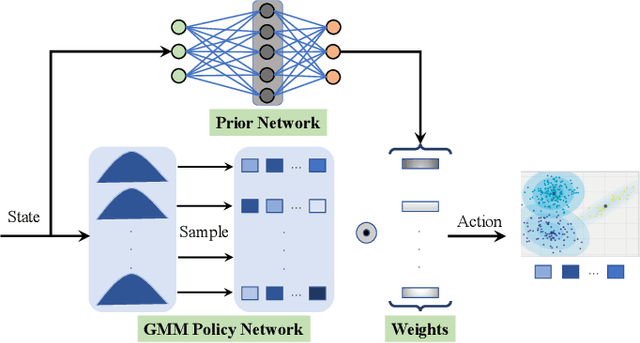
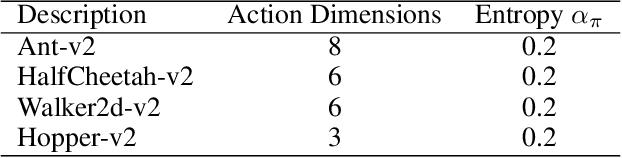

The optimal policy of a reinforcement learning problem is often discontinuous and non-smooth. I.e., for two states with similar representations, their optimal policies can be significantly different. In this case, representing the entire policy with a function approximator (FA) with shared parameters for all states maybe not desirable, as the generalization ability of parameters sharing makes representing discontinuous, non-smooth policies difficult. A common way to solve this problem, known as Mixture-of-Experts, is to represent the policy as the weighted sum of multiple components, where different components perform well on different parts of the state space. Following this idea and inspired by a recent work called advantage-weighted information maximization, we propose to learn for each state weights of these components, so that they entail the information of the state itself and also the preferred action learned so far for the state. The action preference is characterized via the advantage function. In this case, the weight of each component would only be large for certain groups of states whose representations are similar and preferred action representations are also similar. Therefore each component is easy to be represented. We call a policy parameterized in this way an Advantage Weighted Mixture Policy (AWMP) and apply this idea to improve soft-actor-critic (SAC), one of the most competitive continuous control algorithm. Experimental results demonstrate that SAC with AWMP clearly outperforms SAC in four commonly used continuous control tasks and achieve stable performance across different random seeds.
Teach Biped Robots to Walk via Gait Principles and Reinforcement Learning with Adversarial Critics
Oct 22, 2019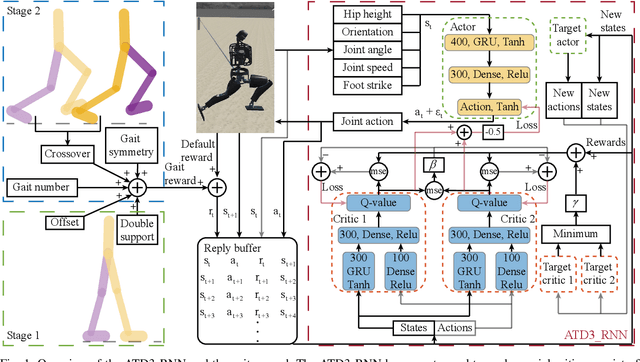
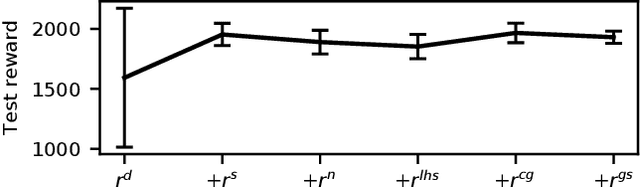
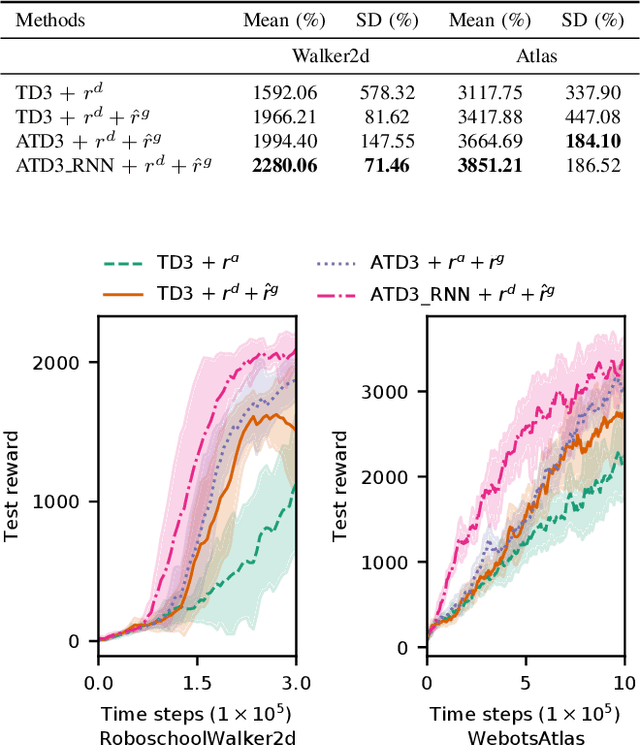
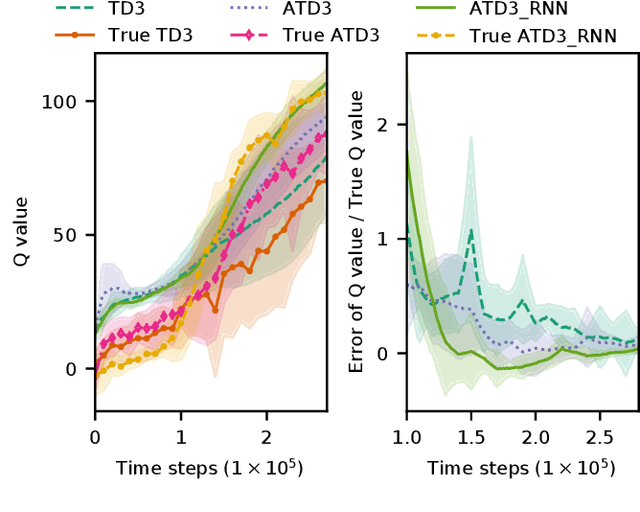
Controlling a biped robot to walk stably is a challenging task considering its nonlinearity and hybrid dynamics. Reinforcement learning can address these issues by directly mapping the observed states to optimal actions that maximize the cumulative reward. However, the local minima caused by unsuitable rewards and the overestimation of the cumulative reward impede the maximization of the cumulative reward. To increase the cumulative reward, this paper designs a gait reward based on walking principles, which compensates the local minima for unnatural motions. Besides, an Adversarial Twin Delayed Deep Deterministic (ATD3) policy gradient algorithm with a recurrent neural network (RNN) is proposed to further boost the cumulative reward by mitigating the overestimation of the cumulative reward. Experimental results in the Roboschool Walker2d and Webots Atlas simulators indicate that the test rewards increase by 23.50% and 9.63% after adding the gait reward. The test rewards further increase by 15.96% and 12.68% after using the ATD3_RNN, and the reason may be that the ATD3_RNN decreases the error of estimating cumulative reward from 19.86% to 3.35%. Besides, the cosine kinetic similarity between the human and the biped robot trained by the gait reward and ATD3_RNN increases by over 69.23%. Consequently, the designed gait reward and ATD3_RNN boost the cumulative reward and teach biped robots to walk better.
Compare Contact Model-based Control and Contact Model-free Learning: A Survey of Robotic Peg-in-hole Assembly Strategies
Apr 10, 2019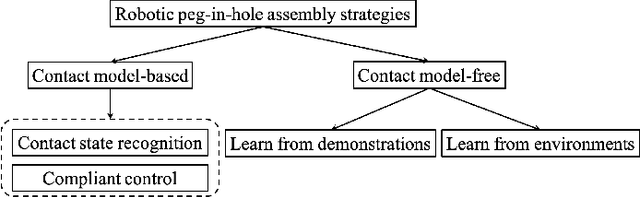
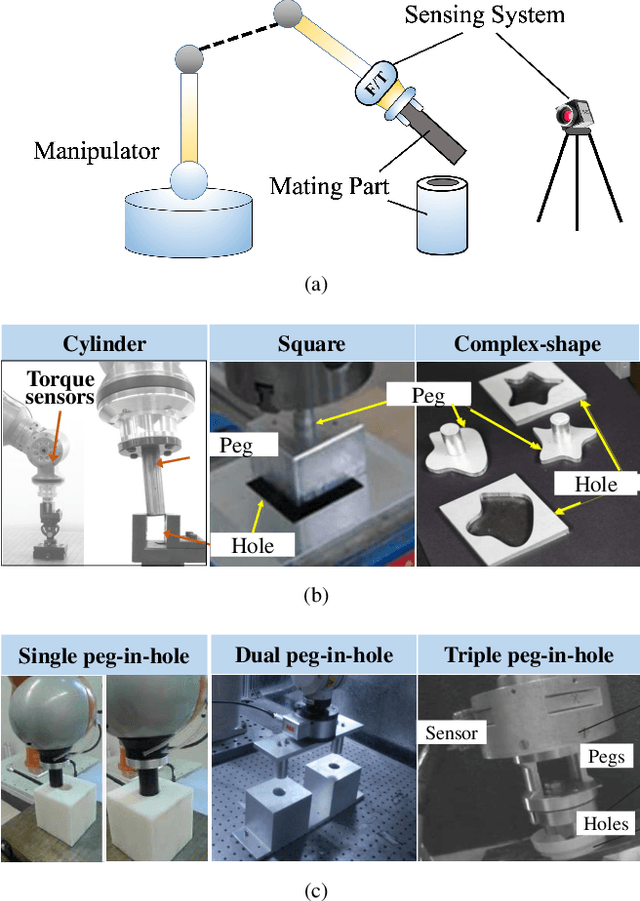
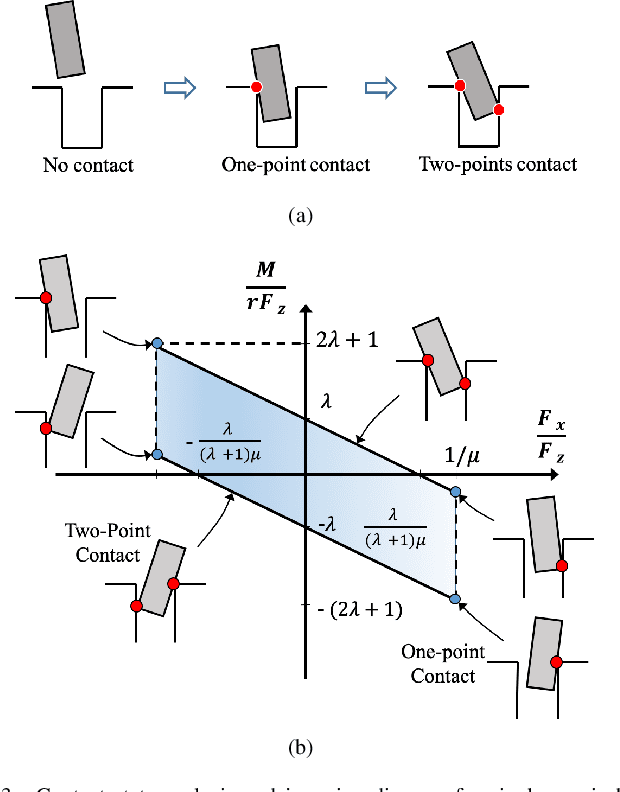
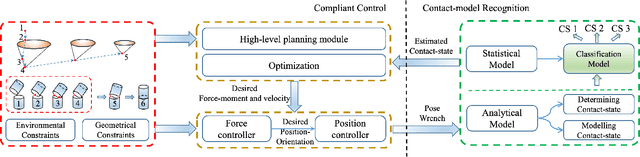
In this paper, we present an overview of robotic peg-in-hole assembly and analyze two main strategies: contact model-based and contact model-free strategies. More specifically, we first introduce the contact model control approaches, including contact state recognition and compliant control two steps. Additionally, we focus on a comprehensive analysis of the whole robotic assembly system. Second, without the contact state recognition process, we decompose the contact model-free learning algorithms into two main subfields: learning from demonstrations and learning from environments (mainly based on reinforcement learning). For each subfield, we survey the landmark studies and ongoing research to compare the different categories. We hope to strengthen the relation between these two research communities by revealing the underlying links. Ultimately, the remaining challenges and open questions in the field of robotic peg-in-hole assembly community is discussed. The promising directions and potential future work are also considered.