 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach Biped Robots to Walk via Gait Principles and Reinforcement Learning with Adversarial Critics
Paper and Code
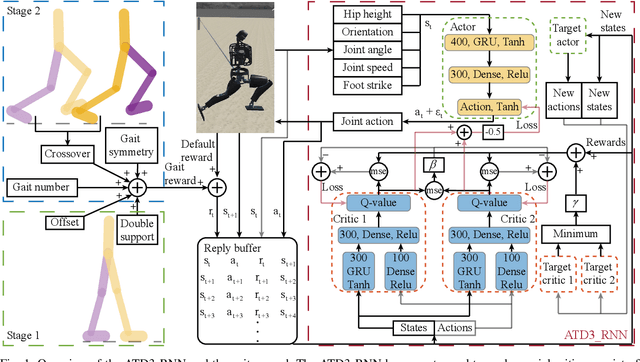
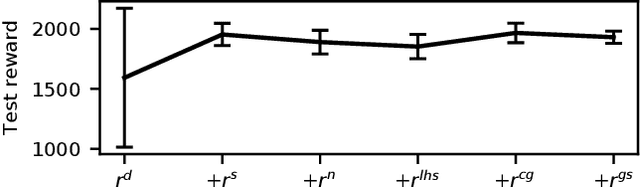
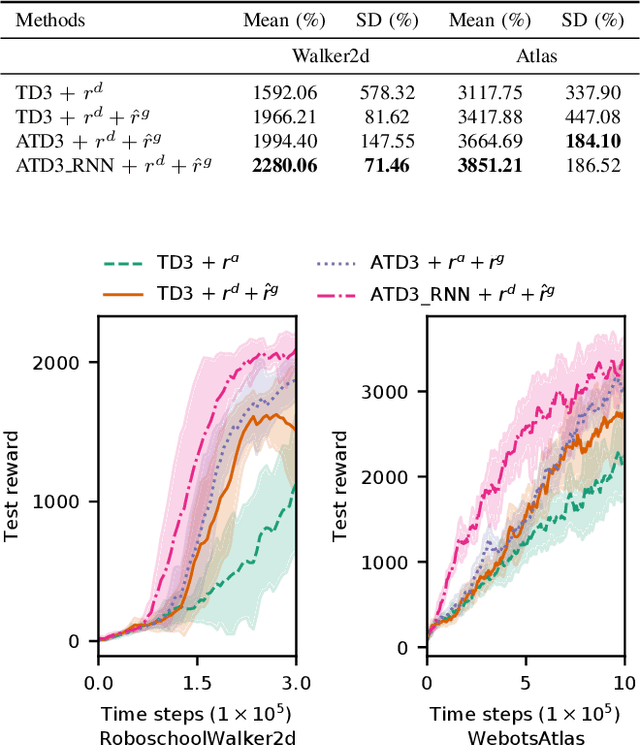
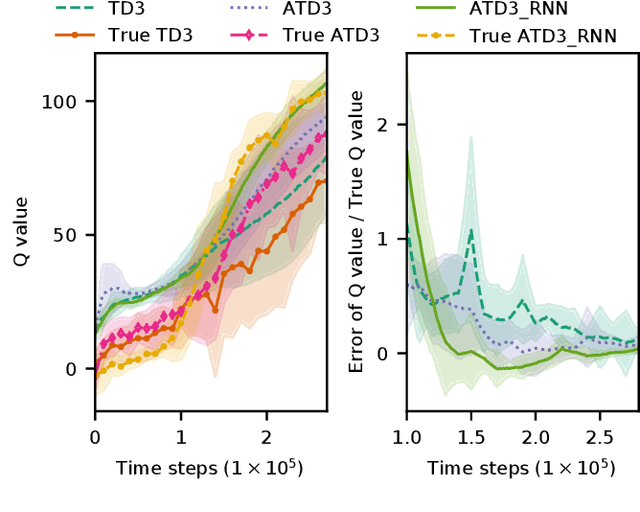
Controlling a biped robot to walk stably is a challenging task considering its nonlinearity and hybrid dynamics. Reinforcement learning can address these issues by directly mapping the observed states to optimal actions that maximize the cumulative reward. However, the local minima caused by unsuitable rewards and the overestimation of the cumulative reward impede the maximization of the cumulative reward. To increase the cumulative reward, this paper designs a gait reward based on walking principles, which compensates the local minima for unnatural motions. Besides, an Adversarial Twin Delayed Deep Deterministic (ATD3) policy gradient algorithm with a recurrent neural network (RNN) is proposed to further boost the cumulative reward by mitigating the overestimation of the cumulative reward. Experimental results in the Roboschool Walker2d and Webots Atlas simulators indicate that the test rewards increase by 23.50% and 9.63% after adding the gait reward. The test rewards further increase by 15.96% and 12.68% after using the ATD3_RNN, and the reason may be that the ATD3_RNN decreases the error of estimating cumulative reward from 19.86% to 3.35%. Besides, the cosine kinetic similarity between the human and the biped robot trained by the gait reward and ATD3_RNN increases by over 69.23%. Consequently, the designed gait reward and ATD3_RNN boost the cumulative reward and teach biped robots to walk better.