 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeight Control and Optimal Torque Planning for Jumping With Wheeled-Bipedal Robots
May 05, 2026This paper mainly studies the accurate height jumping control of wheeled-bipedal robots based on torque planning and energy consumption optimization. Due to the characteristics of underactuated, nonlinear estimation, and instantaneous impact in the jumping process, accurate control of the wheeled-bipedal robot's jumping height is complicated. In reality, robots often jump at excessive height to ensure safety, causing additional motor loss, greater ground reaction force and more energy consumption. To solve this problem, a novel wheeled-bipedal jumping dynamical model(W-JBD) is proposed to achieve accurate height control. It performs well but not suitable for the real robot because the torque has a striking step. Therefore, the Bayesian optimization for torque planning method(BOTP) is proposed, which can obtain the optimal torque planning without accurate dynamic model and within few iterations. BOTP method can reduce 82.3% height error, 26.9% energy cost with continuous torque curve. This result is validated in the Webots simulation platform. Based on the torque curve obtained in the W-JBD model to narrow the searching space, BOTP can quickly converge (40 times on average). Cooperating W-JBD model and BOTP method, it is possible to achieve the height control of real robots with reasonable times of experiments.
A Powered Prosthetic Hand with Vision System for Enhancing the Anthropopathic Grasp
Dec 10, 2024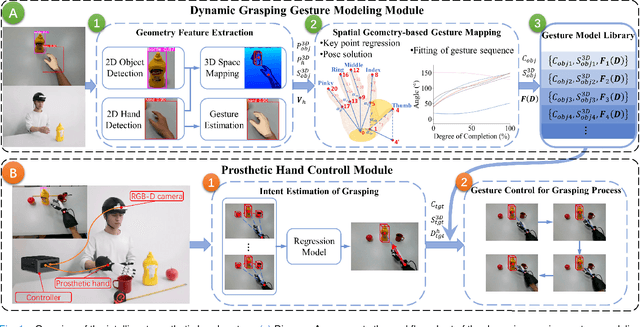
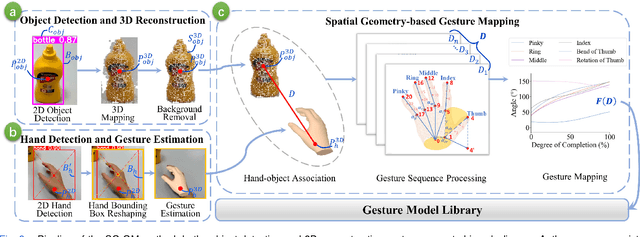
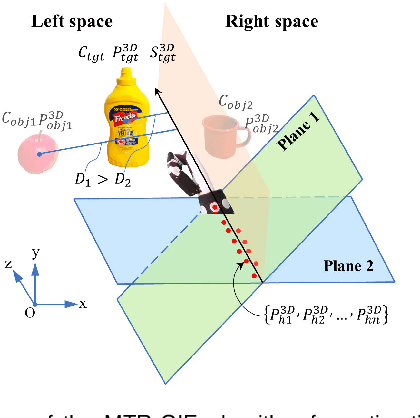

The anthropomorphism of grasping process significantly benefits the experience and grasping efficiency of prosthetic hand wearers. Currently, prosthetic hands controlled by signals such as brain-computer interfaces (BCI) and electromyography (EMG) face difficulties in precisely recognizing the amputees' grasping gestures and executing anthropomorphic grasp processes. Although prosthetic hands equipped with vision systems enables the objects' feature recognition, they lack perception of human grasping intention. Therefore, this paper explores the estimation of grasping gestures solely through visual data to accomplish anthropopathic grasping control and the determination of grasping intention within a multi-object environment. To address this, we propose the Spatial Geometry-based Gesture Mapping (SG-GM) method, which constructs gesture functions based on the geometric features of the human hand grasping processes. It's subsequently implemented on the prosthetic hand. Furthermore, we propose the Motion Trajectory Regression-based Grasping Intent Estimation (MTR-GIE) algorithm. This algorithm predicts pre-grasping object utilizing regression prediction and prior spatial segmentation estimation derived from the prosthetic hand's position and trajectory. The experiments were conducted to grasp 8 common daily objects including cup, fork, etc. The experimental results presented a similarity coefficient $R^{2}$ of grasping process of 0.911, a Root Mean Squared Error ($RMSE$) of 2.47\degree, a success rate of grasping of 95.43$\%$, and an average duration of grasping process of 3.07$\pm$0.41 s. Furthermore, grasping experiments in a multi-object environment were conducted. The average accuracy of intent estimation reached 94.35$\%$. Our methodologies offer a groundbreaking approach to enhance the prosthetic hand's functionality and provides valuable insights for future research.
LLM-assisted Physical Invariant Extraction for Cyber-Physical Systems Anomaly Detection
Nov 17, 2024



Modern industrial infrastructures rely heavily on Cyber-Physical Systems (CPS), but these are vulnerable to cyber-attacks with potentially catastrophic effects. To reduce these risks, anomaly detection methods based on physical invariants have been developed. However, these methods often require domain-specific expertise to manually define invariants, making them costly and difficult to scale. To address this limitation, we propose a novel approach to extract physical invariants from CPS testbeds for anomaly detection. Our insight is that CPS design documentation often contains semantically rich descriptions of physical procedures, which can profile inter-correlated dynamics among system components. Leveraging the built-in physics and engineering knowledge of recent generative AI models, we aim to automate this traditionally manual process, improving scalability and reducing costs. This work focuses on designing and optimizing a Retrieval-Augmented-Generation (RAG) workflow with a customized prompting system tailored for CPS documentation, enabling accurate extraction of semantic information and inference of physical invariants from complex, multimodal content. Then, rather than directly applying the inferred invariants for anomaly detection, we introduce an innovative statistics-based learning approach that integrates these invariants into the training dataset. This method addresses limitations such as hallucination and concept drift, enhancing the reliability of the model. We evaluate our approach on real-world public CPS security dataset which contains 86 data points and 58 attacking cases. The results show that our approach achieves a high precision of 0.923, accurately detecting anomalies while minimizing false alarms.
Fast Hip Joint Moment Estimation with A General Moment Feature Generation Method
Oct 01, 2024The hip joint moment during walking is a crucial basis for hip exoskeleton control. Compared to generating assistive torque profiles based on gait estimation, estimating hip joint moment directly using hip joint angles offers advantages such as simplified sensing and adaptability to variable walking speeds. Existing methods that directly estimate moment from hip joint angles are mainly used for offline biomechanical estimation. However, they suffer from long computation time and lack of personalization, rendering them unsuitable for personalized control of hip exoskeletons. To address these challenges, this paper proposes a fast hip joint moment estimation method based on generalized moment features (GMF). The method first employs a GMF generator to learn a feature representation of joint moment, namely the proposed GMF, which is independent of individual differences. Subsequently, a GRU-based neural network with fast computational performance is trained to learn the mapping from the joint kinematics to the GMF. Finally, the predicted GMF is decoded into the joint moment with a GMF decoder. The joint estimation model is trained and tested on a dataset comprising 20 subjects under 28 walking speed conditions. Results show that the proposed method achieves a root mean square error of 0.1180 $\pm$ 0.0021 Nm/kg for subjects in test dataset, and the computation time per estimation using the employed GRU-based estimator is 1.3420 $\pm$ 0.0031 ms, significantly faster than mainstream neural network architectures, while maintaining comparable network accuracy. These promising results demonstrate that the proposed method enhances the accuracy and computational speed of joint moment estimation neural networks, with potential for guiding exoskeleton control.
Enhancing Prosthetic Safety and Environmental Adaptability: A Visual-Inertial Prosthesis Motion Estimation Approach on Uneven Terrains
Apr 29, 2024



Environment awareness is crucial for enhancing walking safety and stability of amputee wearing powered prosthesis when crossing uneven terrains such as stairs and obstacles. However, existing environmental perception systems for prosthesis only provide terrain types and corresponding parameters, which fails to prevent potential collisions when crossing uneven terrains and may lead to falls and other severe consequences. In this paper, a visual-inertial motion estimation approach is proposed for prosthesis to perceive its movement and the changes of spatial relationship between the prosthesis and uneven terrain when traversing them. To achieve this, we estimate the knee motion by utilizing a depth camera to perceive the environment and align feature points extracted from stairs and obstacles. Subsequently, an error-state Kalman filter is incorporated to fuse the inertial data into visual estimations to reduce the feature extraction error and obtain a more robust estimation. The motion of prosthetic joint and toe are derived using the prosthesis model parameters. Experiment conducted on our collected dataset and stair walking trials with a powered prosthesis shows that the proposed method can accurately tracking the motion of the human leg and prosthesis with an average root-mean-square error of toe trajectory less than 5 cm. The proposed method is expected to enable the environmental adaptive control for prosthesis, thereby enhancing amputee's safety and mobility in uneven terrains.
RESMatch: Referring Expression Segmentation in a Semi-Supervised Manner
Feb 11, 2024Referring expression segmentation (RES), a task that involves localizing specific instance-level objects based on free-form linguistic descriptions, has emerged as a crucial frontier in human-AI interaction. It demands an intricate understanding of both visual and textual contexts and often requires extensive training data. This paper introduces RESMatch, the first semi-supervised learning (SSL) approach for RES, aimed at reducing reliance on exhaustive data annotation. Extensive validation on multiple RES datasets demonstrates that RESMatch significantly outperforms baseline approaches, establishing a new state-of-the-art. Although existing SSL techniques are effective in image segmentation, we find that they fall short in RES. Facing the challenges including the comprehension of free-form linguistic descriptions and the variability in object attributes, RESMatch introduces a trifecta of adaptations: revised strong perturbation, text augmentation, and adjustments for pseudo-label quality and strong-weak supervision. This pioneering work lays the groundwork for future research in semi-supervised learning for referring expression segmentation.
D3PRefiner: A Diffusion-based Denoise Method for 3D Human Pose Refinement
Jan 08, 2024Three-dimensional (3D) human pose estimation using a monocular camera has gained increasing attention due to its ease of implementation and the abundance of data available from daily life. However, owing to the inherent depth ambiguity in images, the accuracy of existing monocular camera-based 3D pose estimation methods remains unsatisfactory, and the estimated 3D poses usually include much noise. By observing the histogram of this noise, we find each dimension of the noise follows a certain distribution, which indicates the possibility for a neural network to learn the mapping between noisy poses and ground truth poses. In this work, in order to obtain more accurate 3D poses, a Diffusion-based 3D Pose Refiner (D3PRefiner) is proposed to refine the output of any existing 3D pose estimator. We first introduce a conditional multivariate Gaussian distribution to model the distribution of noisy 3D poses, using paired 2D poses and noisy 3D poses as conditions to achieve greater accuracy. Additionally, we leverage the architecture of current diffusion models to convert the distribution of noisy 3D poses into ground truth 3D poses. To evaluate the effectiveness of the proposed method, two state-of-the-art sequence-to-sequence 3D pose estimators are used as basic 3D pose estimation models, and the proposed method is evaluated on different types of 2D poses and different lengths of the input sequence. Experimental results demonstrate the proposed architecture can significantly improve the performance of current sequence-to-sequence 3D pose estimators, with a reduction of at least 10.3% in the mean per joint position error (MPJPE) and at least 11.0% in the Procrustes MPJPE (P-MPJPE).
Learning Task-adaptive Quasi-stiffness Control for A Powered Transfemoral Prosthesis
Nov 25, 2023While significant advancements have been made in the mechanical and task-specific controller designs of powered transfemoral prostheses, developing a task-adaptive control framework that generalizes across various locomotion modes and terrain conditions remains an open problem. This study proposes a task-adaptive learning quasi-stiffness control framework for powered prostheses that generalizes across tasks, including the torque-angle relationship reconstruction part and the quasi-stiffness controller design part. Quasi-stiffness is defined as the slope of the human joint's torque-angle relationship. To accurately obtain the torque-angle relationship in a new task, a Gaussian Process Regression (GPR) model is introduced to predict the target features of the human joint's angle and torque in the task. Then a Kernelized Movement Primitives (KMP) is employed to reconstruct the torque-angle relationship of a new task from multiple human demonstrations and estimated target features. Based on the torque-angle relationship of the new task, a quasi-stiffness control approach is designed for a powered prosthesis. Finally, the proposed framework is validated through practical examples, including varying speed and incline walking tasks. The proposed framework has the potential to expand to variable walking tasks in daily life for the transfemoral amputees.
Learning to Assist Different Wearers in Multitasks: Efficient and Individualized Human-In-the-Loop Adaption Framework for Exoskeleton Robots
Sep 26, 2023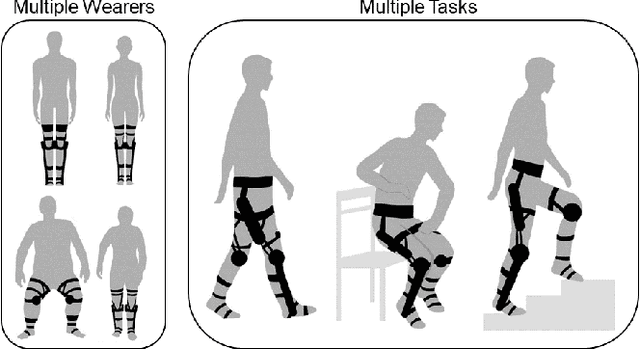
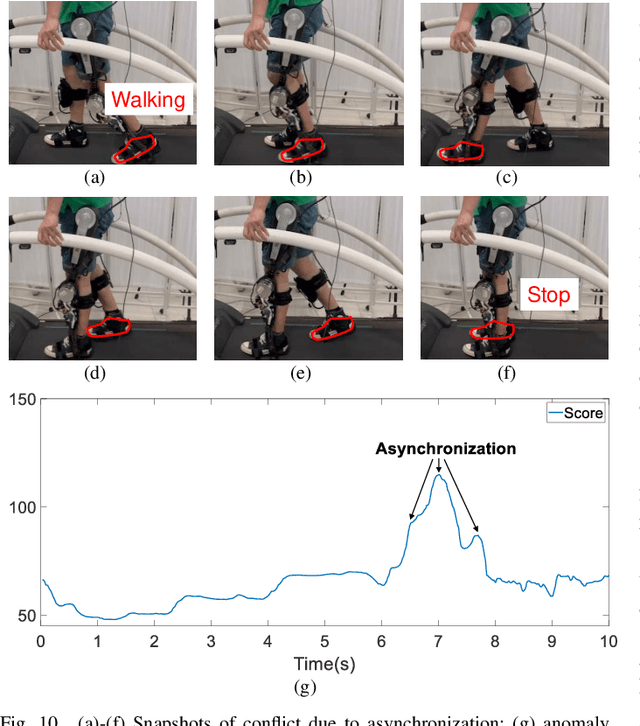
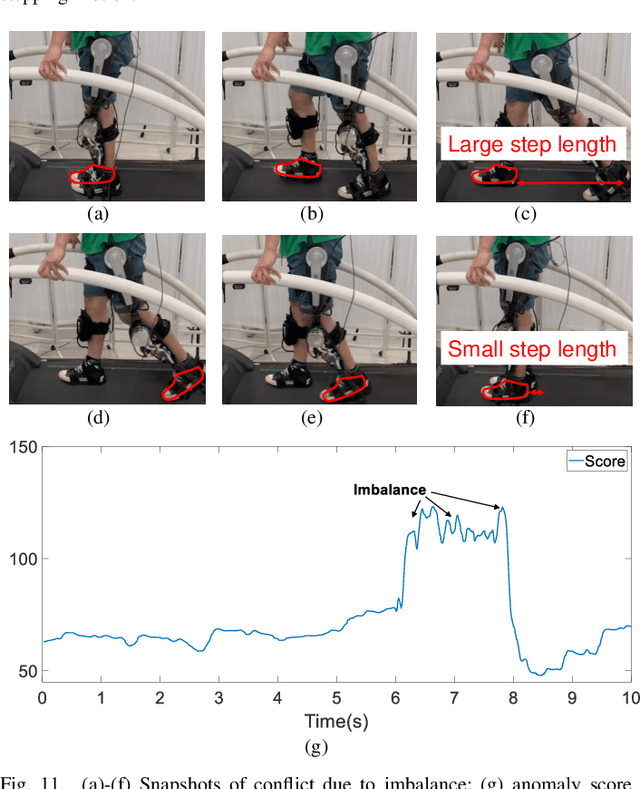
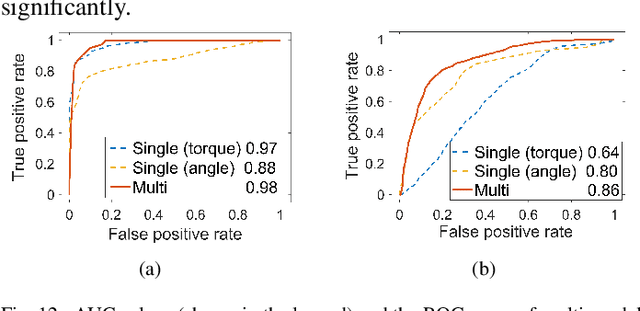
One of the typical purposes of using lower-limb exoskeleton robots is to provide assistance to the wearer by supporting their weight and augmenting their physical capabilities according to a given task and human motion intentions. The generalizability of robots across different wearers in multiple tasks is important to ensure that the robot can provide correct and effective assistance in actual implementation. However, most lower-limb exoskeleton robots exhibit only limited generalizability. Therefore, this paper proposes a human-in-the-loop learning and adaptation framework for exoskeleton robots to improve their performance in various tasks and for different wearers. To suit different wearers, an individualized walking trajectory is generated online using dynamic movement primitives and Bayes optimization. To accommodate various tasks, a task translator is constructed using a neural network to generalize a trajectory to more complex scenarios. These generalization techniques are integrated into a unified variable impedance model, which regulates the exoskeleton to provide assistance while ensuring safety. In addition, an anomaly detection network is developed to quantitatively evaluate the wearer's comfort, which is considered in the trajectory learning procedure and contributes to the relaxation of conflicts in impedance control. The proposed framework is easy to implement, because it requires proprioceptive sensors only to perform and deploy data-efficient learning schemes. This makes the exoskeleton practical for deployment in complex scenarios, accommodating different walking patterns, habits, tasks, and conflicts. Experiments and comparative studies on a lower-limb exoskeleton robot are performed to demonstrate the effectiveness of the proposed framework.
Deep3DSketch+: Rapid 3D Modeling from Single Free-hand Sketches
Sep 22, 2023The rapid development of AR/VR brings tremendous demands for 3D content. While the widely-used Computer-Aided Design (CAD) method requires a time-consuming and labor-intensive modeling process, sketch-based 3D modeling offers a potential solution as a natural form of computer-human interaction. However, the sparsity and ambiguity of sketches make it challenging to generate high-fidelity content reflecting creators' ideas. Precise drawing from multiple views or strategic step-by-step drawings is often required to tackle the challenge but is not friendly to novice users. In this work, we introduce a novel end-to-end approach, Deep3DSketch+, which performs 3D modeling using only a single free-hand sketch without inputting multiple sketches or view information. Specifically, we introduce a lightweight generation network for efficient inference in real-time and a structural-aware adversarial training approach with a Stroke Enhancement Module (SEM) to capture the structural information to facilitate learning of the realistic and fine-detailed shape structures for high-fidelity performance. Extensive experiments demonstrated the effectiveness of our approach with the state-of-the-art (SOTA) performance on both synthetic and real datasets.