 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Model of Message Sensation Value in Short Video Multimodal Features that Predicts Sensory and Behavioral Engagement
Apr 21, 2026The contemporary media landscape is characterized by sensational short videos. While prior research examines the effects of individual multimodal features, the collective impact of multimodal features on viewer engagement with short videos remains unknown. Grounded in the theoretical framework of Message Sensation Value (MSV), this study develops and tests a computational model of MSV with multimodal feature analysis and human evaluation of 1,200 short videos. This model that predicts sensory and behavioral engagement was further validated across two unseen datasets from three short video platforms (combined N = 14,492). While MSV is positively associated with sensory engagement, it shows an inverted U-shaped relationship with behavioral engagement: Higher MSV elicits stronger sensory stimulation, but moderate MSV optimizes behavioral engagement. This research advances the theoretical understanding of short video engagement and introduces a robust computational tool for short video research.
Rhythm: Learning Interactive Whole-Body Control for Dual Humanoids
Mar 03, 2026Realizing interactive whole-body control for multi-humanoid systems is critical for unlocking complex collaborative capabilities in shared environments. Although recent advancements have significantly enhanced the agility of individual robots, bridging the gap to physically coupled multi-humanoid interaction remains challenging, primarily due to severe kinematic mismatches and complex contact dynamics. To address this, we introduce Rhythm, the first unified framework enabling real-world deployment of dual-humanoid systems for complex, physically plausible interactions. Our framework integrates three core components: (1) an Interaction-Aware Motion Retargeting (IAMR) module that generates feasible humanoid interaction references from human data; (2) an Interaction-Guided Reinforcement Learning (IGRL) policy that masters coupled dynamics via graph-based rewards; and (3) a real-world deployment system that enables robust transfer of dual-humanoid interaction. Extensive experiments on physical Unitree G1 robots demonstrate that our framework achieves robust interactive whole-body control, successfully transferring diverse behaviors such as hugging and dancing from simulation to reality.
ES4R: Speech Encoding Based on Prepositive Affective Modeling for Empathetic Response Generation
Jan 16, 2026Empathetic speech dialogue requires not only understanding linguistic content but also perceiving rich paralinguistic information such as prosody, tone, and emotional intensity for affective understandings. Existing speech-to-speech large language models either rely on ASR transcription or use encoders to extract latent representations, often weakening affective information and contextual coherence in multi-turn dialogues. To address this, we propose \textbf{ES4R}, a framework for speech-based empathetic response generation. Our core innovation lies in explicitly modeling structured affective context before speech encoding, rather than relying on implicit learning by the encoder or explicit emotion supervision. Specifically, we introduce a dual-level attention mechanism to capture turn-level affective states and dialogue-level affective dynamics. The resulting affective representations are then integrated with textual semantics through speech-guided cross-modal attention to generate empathetic responses. For speech output, we employ energy-based strategy selection and style fusion to achieve empathetic speech synthesis. ES4R consistently outperforms strong baselines in both automatic and human evaluations and remains robust across different LLM backbones.
AIonopedia: an LLM agent orchestrating multimodal learning for ionic liquid discovery
Nov 14, 2025The discovery of novel Ionic Liquids (ILs) is hindered by critical challenges in property prediction, including limited data, poor model accuracy, and fragmented workflows. Leveraging the power of Large Language Models (LLMs), we introduce AIonopedia, to the best of our knowledge, the first LLM agent for IL discovery. Powered by an LLM-augmented multimodal domain foundation model for ILs, AIonopedia enables accurate property predictions and incorporates a hierarchical search architecture for molecular screening and design. Trained and evaluated on a newly curated and comprehensive IL dataset, our model delivers superior performance. Complementing these results, evaluations on literature-reported systems indicate that the agent can perform effective IL modification. Moving beyond offline tests, the practical efficacy was further confirmed through real-world wet-lab validation, in which the agent demonstrated exceptional generalization capabilities on challenging out-of-distribution tasks, underscoring its ability to accelerate real-world IL discovery.
Scaling Linear Attention with Sparse State Expansion
Jul 22, 2025The Transformer architecture, despite its widespread success, struggles with long-context scenarios due to quadratic computation and linear memory growth. While various linear attention variants mitigate these efficiency constraints by compressing context into fixed-size states, they often degrade performance in tasks such as in-context retrieval and reasoning. To address this limitation and achieve more effective context compression, we propose two key innovations. First, we introduce a row-sparse update formulation for linear attention by conceptualizing state updating as information classification. This enables sparse state updates via softmax-based top-$k$ hard classification, thereby extending receptive fields and reducing inter-class interference. Second, we present Sparse State Expansion (SSE) within the sparse framework, which expands the contextual state into multiple partitions, effectively decoupling parameter size from state capacity while maintaining the sparse classification paradigm. Our design, supported by efficient parallelized implementations, yields effective classification and discriminative state representations. We extensively validate SSE in both pure linear and hybrid (SSE-H) architectures across language modeling, in-context retrieval, and mathematical reasoning benchmarks. SSE demonstrates strong retrieval performance and scales favorably with state size. Moreover, after reinforcement learning (RL) training, our 2B SSE-H model achieves state-of-the-art mathematical reasoning performance among small reasoning models, scoring 64.7 on AIME24 and 51.3 on AIME25, significantly outperforming similarly sized open-source Transformers. These results highlight SSE as a promising and efficient architecture for long-context modeling.
Object Concepts Emerge from Motion
May 27, 2025Object concepts play a foundational role in human visual cognition, enabling perception, memory, and interaction in the physical world. Inspired by findings in developmental neuroscience - where infants are shown to acquire object understanding through observation of motion - we propose a biologically inspired framework for learning object-centric visual representations in an unsupervised manner. Our key insight is that motion boundary serves as a strong signal for object-level grouping, which can be used to derive pseudo instance supervision from raw videos. Concretely, we generate motion-based instance masks using off-the-shelf optical flow and clustering algorithms, and use them to train visual encoders via contrastive learning. Our framework is fully label-free and does not rely on camera calibration, making it scalable to large-scale unstructured video data. We evaluate our approach on three downstream tasks spanning both low-level (monocular depth estimation) and high-level (3D object detection and occupancy prediction) vision. Our models outperform previous supervised and self-supervised baselines and demonstrate strong generalization to unseen scenes. These results suggest that motion-induced object representations offer a compelling alternative to existing vision foundation models, capturing a crucial but overlooked level of abstraction: the visual instance. The corresponding code will be released upon paper acceptance.
Decouple and Orthogonalize: A Data-Free Framework for LoRA Merging
May 21, 2025With more open-source models available for diverse tasks, model merging has gained attention by combining models into one, reducing training, storage, and inference costs. Current research mainly focuses on model merging for full fine-tuning, overlooking the popular LoRA. However, our empirical analysis reveals that: a) existing merging methods designed for full fine-tuning perform poorly on LoRA; b) LoRA modules show much larger parameter magnitude variance than full fine-tuned weights; c) greater parameter magnitude variance correlates with worse merging performance. Considering that large magnitude variances cause deviations in the distribution of the merged parameters, resulting in information loss and performance degradation, we propose a Decoupled and Orthogonal merging approach(DO-Merging). By separating parameters into magnitude and direction components and merging them independently, we reduce the impact of magnitude differences on the directional alignment of the merged models, thereby preserving task information. Furthermore, we introduce a data-free, layer-wise gradient descent method with orthogonal constraints to mitigate interference during the merging of direction components. We provide theoretical guarantees for both the decoupling and orthogonal components. And we validate through extensive experiments across vision, language, and multi-modal domains that our proposed DO-Merging can achieve significantly higher performance than existing merging methods at a minimal cost. Notably, each component can be flexibly integrated with existing methods, offering near free-lunch improvements across tasks.
Dynamic Base model Shift for Delta Compression
May 16, 2025
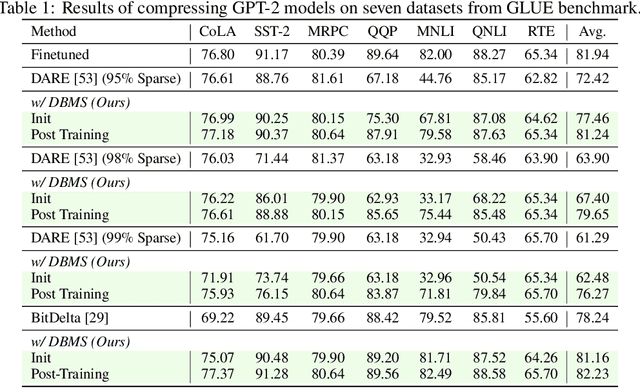

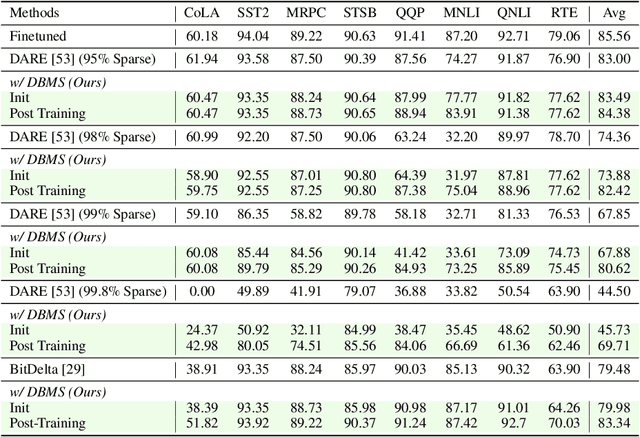
Transformer-based models with the pretrain-finetune paradigm bring about significant progress, along with the heavy storage and deployment costs of finetuned models on multiple tasks. Delta compression attempts to lower the costs by reducing the redundancy of delta parameters (i.e., the difference between the finetuned and pre-trained model weights) through pruning or quantization. However, existing methods by default employ the pretrained model as the base model and compress the delta parameters for every task, which may causes significant performance degradation, especially when the compression rate is extremely high. To tackle this issue, we investigate the impact of different base models on the performance of delta compression and find that the pre-trained base model can hardly be optimal. To this end, we propose Dynamic Base Model Shift (DBMS), which dynamically adapts the base model to the target task before performing delta compression. Specifically, we adjust two parameters, which respectively determine the magnitude of the base model shift and the overall scale of delta compression, to boost the compression performance on each task. Through low-cost learning of these two parameters, our DBMS can maintain most of the finetuned model's performance even under an extremely high compression ratio setting, significantly surpassing existing methods. Moreover, our DBMS is orthogonal and can be integrated with a variety of other methods, and it has been evaluated across different types of models including language, vision transformer, and multi-modal models.
Emotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding
May 10, 2025Emotion understanding in videos aims to accurately recognize and interpret individuals' emotional states by integrating contextual, visual, textual, and auditory cues. While Large Multimodal Models (LMMs) have demonstrated significant progress in general vision-language (VL) tasks, their performance in emotion-specific scenarios remains limited. Moreover, fine-tuning LMMs on emotion-related tasks often leads to catastrophic forgetting, hindering their ability to generalize across diverse tasks. To address these challenges, we present Emotion-Qwen, a tailored multimodal framework designed to enhance both emotion understanding and general VL reasoning. Emotion-Qwen incorporates a sophisticated Hybrid Compressor based on the Mixture of Experts (MoE) paradigm, which dynamically routes inputs to balance emotion-specific and general-purpose processing. The model is pre-trained in a three-stage pipeline on large-scale general and emotional image datasets to support robust multimodal representations. Furthermore, we construct the Video Emotion Reasoning (VER) dataset, comprising more than 40K bilingual video clips with fine-grained descriptive annotations, to further enrich Emotion-Qwen's emotional reasoning capability. Experimental results demonstrate that Emotion-Qwen achieves state-of-the-art performance on multiple emotion recognition benchmarks, while maintaining competitive results on general VL tasks. Code and models are available at https://anonymous.4open.science/r/Emotion-Qwen-Anonymous.
RankPO: Preference Optimization for Job-Talent Matching
Mar 13, 2025Matching job descriptions (JDs) with suitable talent requires models capable of understanding not only textual similarities between JDs and candidate resumes but also contextual factors such as geographical location and academic seniority. To address this challenge, we propose a two-stage training framework for large language models (LLMs). In the first stage, a contrastive learning approach is used to train the model on a dataset constructed from real-world matching rules, such as geographical alignment and research area overlap. While effective, this model primarily learns patterns that defined by the matching rules. In the second stage, we introduce a novel preference-based fine-tuning method inspired by Direct Preference Optimization (DPO), termed Rank Preference Optimization (RankPO), to align the model with AI-curated pairwise preferences emphasizing textual understanding. Our experiments show that while the first-stage model achieves strong performance on rule-based data (nDCG@20 = 0.706), it lacks robust textual understanding (alignment with AI annotations = 0.46). By fine-tuning with RankPO, we achieve a balanced model that retains relatively good performance in the original tasks while significantly improving the alignment with AI preferences. The code and data are available at https://github.com/yflyzhang/RankPO.