 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Feature Compression for Model-Specific Representations
Apr 08, 2026As deep learning inference is increasingly deployed in shared and cloud-based settings, a growing concern is input repurposing, in which data submitted for one task is reused by unauthorized models for another. Existing privacy defenses largely focus on restricting data access, but provide limited control over what downstream uses a released representation can still support. We propose a feature extraction framework that suppresses cross-model transfer while preserving accuracy for a designated classifier. The framework employs a variational latent bottleneck, trained with a task-driven cross-entropy objective and KL regularization, but without any pixel-level reconstruction loss, to encode inputs into a compact latent space. A dynamic binary mask, computed from per-dimension KL divergence and gradient-based saliency with respect to the frozen target model, suppresses latent dimensions that are uninformative for the intended task. Because saliency computation requires gradient access, the encoder is trained in a white-box setting, whereas inference requires only a forward pass through the frozen target model. On CIFAR-100, the processed representations retain strong utility for the designated classifier while reducing the accuracy of all unintended classifiers to below 2%, yielding a suppression ratio exceeding 45 times relative to unintended models. Preliminary experiments on CIFAR-10, Tiny ImageNet, and Pascal VOC provide exploratory evidence that the approach extends across task settings, although further evaluation is needed to assess robustness against adaptive adversaries.
Emotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding
May 10, 2025Emotion understanding in videos aims to accurately recognize and interpret individuals' emotional states by integrating contextual, visual, textual, and auditory cues. While Large Multimodal Models (LMMs) have demonstrated significant progress in general vision-language (VL) tasks, their performance in emotion-specific scenarios remains limited. Moreover, fine-tuning LMMs on emotion-related tasks often leads to catastrophic forgetting, hindering their ability to generalize across diverse tasks. To address these challenges, we present Emotion-Qwen, a tailored multimodal framework designed to enhance both emotion understanding and general VL reasoning. Emotion-Qwen incorporates a sophisticated Hybrid Compressor based on the Mixture of Experts (MoE) paradigm, which dynamically routes inputs to balance emotion-specific and general-purpose processing. The model is pre-trained in a three-stage pipeline on large-scale general and emotional image datasets to support robust multimodal representations. Furthermore, we construct the Video Emotion Reasoning (VER) dataset, comprising more than 40K bilingual video clips with fine-grained descriptive annotations, to further enrich Emotion-Qwen's emotional reasoning capability. Experimental results demonstrate that Emotion-Qwen achieves state-of-the-art performance on multiple emotion recognition benchmarks, while maintaining competitive results on general VL tasks. Code and models are available at https://anonymous.4open.science/r/Emotion-Qwen-Anonymous.
Detecting Manipulated Contents Using Knowledge-Grounded Inference
Apr 29, 2025The detection of manipulated content, a prevalent form of fake news, has been widely studied in recent years. While existing solutions have been proven effective in fact-checking and analyzing fake news based on historical events, the reliance on either intrinsic knowledge obtained during training or manually curated context hinders them from tackling zero-day manipulated content, which can only be recognized with real-time contextual information. In this work, we propose Manicod, a tool designed for detecting zero-day manipulated content. Manicod first sources contextual information about the input claim from mainstream search engines, and subsequently vectorizes the context for the large language model (LLM) through retrieval-augmented generation (RAG). The LLM-based inference can produce a "truthful" or "manipulated" decision and offer a textual explanation for the decision. To validate the effectiveness of Manicod, we also propose a dataset comprising 4270 pieces of manipulated fake news derived from 2500 recent real-world news headlines. Manicod achieves an overall F1 score of 0.856 on this dataset and outperforms existing methods by up to 1.9x in F1 score on their benchmarks on fact-checking and claim verification.
Instance Segmentation of Scene Sketches Using Natural Image Priors
Feb 13, 2025
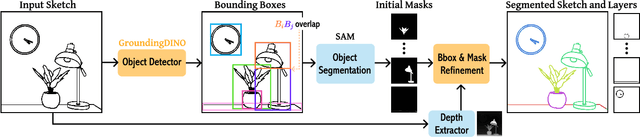
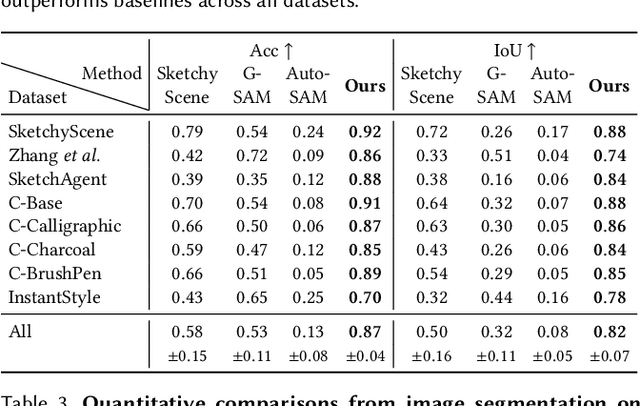
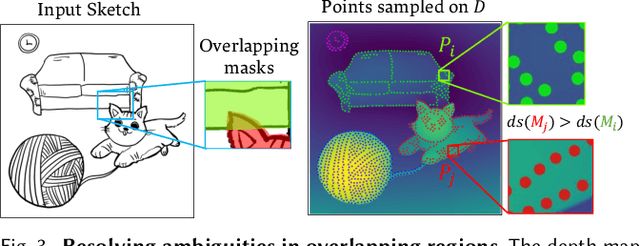
Sketch segmentation involves grouping pixels within a sketch that belong to the same object or instance. It serves as a valuable tool for sketch editing tasks, such as moving, scaling, or removing specific components. While image segmentation models have demonstrated remarkable capabilities in recent years, sketches present unique challenges for these models due to their sparse nature and wide variation in styles. We introduce SketchSeg, a method for instance segmentation of raster scene sketches. Our approach adapts state-of-the-art image segmentation and object detection models to the sketch domain by employing class-agnostic fine-tuning and refining segmentation masks using depth cues. Furthermore, our method organizes sketches into sorted layers, where occluded instances are inpainted, enabling advanced sketch editing applications. As existing datasets in this domain lack variation in sketch styles, we construct a synthetic scene sketch segmentation dataset featuring sketches with diverse brush strokes and varying levels of detail. We use this dataset to demonstrate the robustness of our approach and will release it to promote further research in the field. Project webpage: https://sketchseg.github.io/sketch-seg/
Global Attention-Guided Dual-Domain Point Cloud Feature Learning for Classification and Segmentation
Jul 12, 2024



Previous studies have demonstrated the effectiveness of point-based neural models on the point cloud analysis task. However, there remains a crucial issue on producing the efficient input embedding for raw point coordinates. Moreover, another issue lies in the limited efficiency of neighboring aggregations, which is a critical component in the network stem. In this paper, we propose a Global Attention-guided Dual-domain Feature Learning network (GAD) to address the above-mentioned issues. We first devise the Contextual Position-enhanced Transformer (CPT) module, which is armed with an improved global attention mechanism, to produce a global-aware input embedding that serves as the guidance to subsequent aggregations. Then, the Dual-domain K-nearest neighbor Feature Fusion (DKFF) is cascaded to conduct effective feature aggregation through novel dual-domain feature learning which appreciates both local geometric relations and long-distance semantic connections. Extensive experiments on multiple point cloud analysis tasks (e.g., classification, part segmentation, and scene semantic segmentation) demonstrate the superior performance of the proposed method and the efficacy of the devised modules.
Multiple VLAD encoding of CNNs for image classification
Jun 30, 2017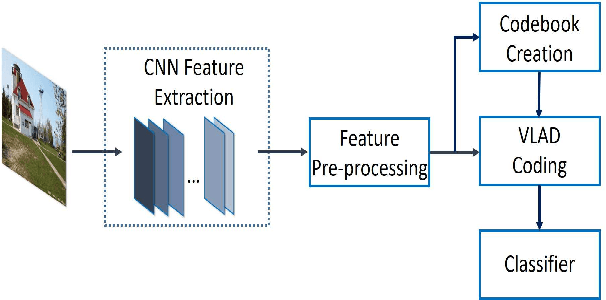
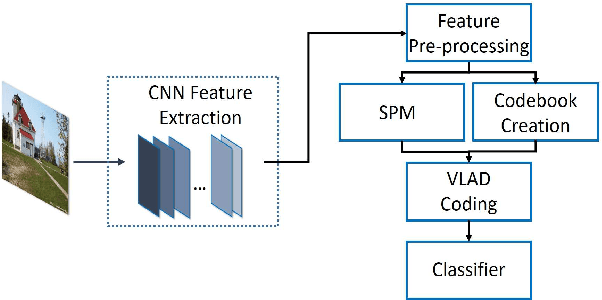


Despite the effectiveness of convolutional neural networks (CNNs) especially in image classification tasks, the effect of convolution features on learned representations is still limited. It mostly focuses on the salient object of the images, but ignores the variation information on clutter and local. In this paper, we propose a special framework, which is the multiple VLAD encoding method with the CNNs features for image classification. Furthermore, in order to improve the performance of the VLAD coding method, we explore the multiplicity of VLAD encoding with the extension of three kinds of encoding algorithms, which are the VLAD-SA method, the VLAD-LSA and the VLAD-LLC method. Finally, we equip the spatial pyramid patch (SPM) on VLAD encoding to add the spatial information of CNNs feature. In particular, the power of SPM leads our framework to yield better performance compared to the existing method.