 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudMamba: Grouped Selective State Spaces for Point Cloud Analysis
Nov 11, 2025Due to the long-range modeling ability and linear complexity property, Mamba has attracted considerable attention in point cloud analysis. Despite some interesting progress, related work still suffers from imperfect point cloud serialization, insufficient high-level geometric perception, and overfitting of the selective state space model (S6) at the core of Mamba. To this end, we resort to an SSM-based point cloud network termed CloudMamba to address the above challenges. Specifically, we propose sequence expanding and sequence merging, where the former serializes points along each axis separately and the latter serves to fuse the corresponding higher-order features causally inferred from different sequences, enabling unordered point sets to adapt more stably to the causal nature of Mamba without parameters. Meanwhile, we design chainedMamba that chains the forward and backward processes in the parallel bidirectional Mamba, capturing high-level geometric information during scanning. In addition, we propose a grouped selective state space model (GS6) via parameter sharing on S6, alleviating the overfitting problem caused by the computational mode in S6. Experiments on various point cloud tasks validate CloudMamba's ability to achieve state-of-the-art results with significantly less complexity.
HyperDiff: Hypergraph Guided Diffusion Model for 3D Human Pose Estimation
Aug 20, 2025Monocular 3D human pose estimation (HPE) often encounters challenges such as depth ambiguity and occlusion during the 2D-to-3D lifting process. Additionally, traditional methods may overlook multi-scale skeleton features when utilizing skeleton structure information, which can negatively impact the accuracy of pose estimation. To address these challenges, this paper introduces a novel 3D pose estimation method, HyperDiff, which integrates diffusion models with HyperGCN. The diffusion model effectively captures data uncertainty, alleviating depth ambiguity and occlusion. Meanwhile, HyperGCN, serving as a denoiser, employs multi-granularity structures to accurately model high-order correlations between joints. This improves the model's denoising capability especially for complex poses. Experimental results demonstrate that HyperDiff achieves state-of-the-art performance on the Human3.6M and MPI-INF-3DHP datasets and can flexibly adapt to varying computational resources to balance performance and efficiency.
PiCo: Enhancing Text-Image Alignment with Improved Noise Selection and Precise Mask Control in Diffusion Models
May 06, 2025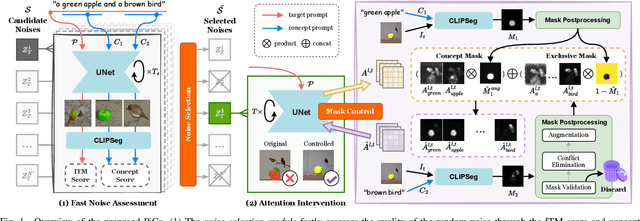
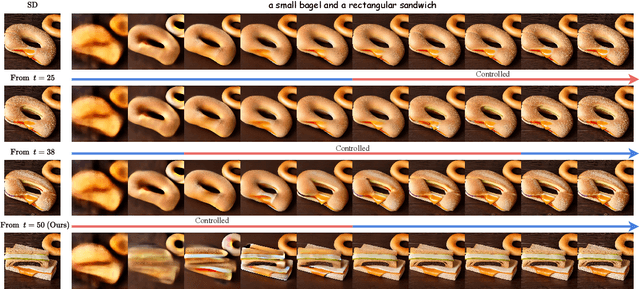


Advanced diffusion models have made notable progress in text-to-image compositional generation. However, it is still a challenge for existing models to achieve text-image alignment when confronted with complex text prompts. In this work, we highlight two factors that affect this alignment: the quality of the randomly initialized noise and the reliability of the generated controlling mask. We then propose PiCo (Pick-and-Control), a novel training-free approach with two key components to tackle these two factors. First, we develop a noise selection module to assess the quality of the random noise and determine whether the noise is suitable for the target text. A fast sampling strategy is utilized to ensure efficiency in the noise selection stage. Second, we introduce a referring mask module to generate pixel-level masks and to precisely modulate the cross-attention maps. The referring mask is applied to the standard diffusion process to guide the reasonable interaction between text and image features. Extensive experiments have been conducted to verify the effectiveness of PiCo in liberating users from the tedious process of random generation and in enhancing the text-image alignment for diverse text descriptions.
Uncertainty Guided Refinement for Fine-Grained Salient Object Detection
Apr 13, 2025



Recently, salient object detection (SOD) methods have achieved impressive performance. However, salient regions predicted by existing methods usually contain unsaturated regions and shadows, which limits the model for reliable fine-grained predictions. To address this, we introduce the uncertainty guidance learning approach to SOD, intended to enhance the model's perception of uncertain regions. Specifically, we design a novel Uncertainty Guided Refinement Attention Network (UGRAN), which incorporates three important components, i.e., the Multilevel Interaction Attention (MIA) module, the Scale Spatial-Consistent Attention (SSCA) module, and the Uncertainty Refinement Attention (URA) module. Unlike conventional methods dedicated to enhancing features, the proposed MIA facilitates the interaction and perception of multilevel features, leveraging the complementary characteristics among multilevel features. Then, through the proposed SSCA, the salient information across diverse scales within the aggregated features can be integrated more comprehensively and integrally. In the subsequent steps, we utilize the uncertainty map generated from the saliency prediction map to enhance the model's perception capability of uncertain regions, generating a highly-saturated fine-grained saliency prediction map. Additionally, we devise an adaptive dynamic partition (ADP) mechanism to minimize the computational overhead of the URA module and improve the utilization of uncertainty guidance. Experiments on seven benchmark datasets demonstrate the superiority of the proposed UGRAN over the state-of-the-art methodologies. Codes will be released at https://github.com/I2-Multimedia-Lab/UGRAN.
Uni4D: A Unified Self-Supervised Learning Framework for Point Cloud Videos
Apr 07, 2025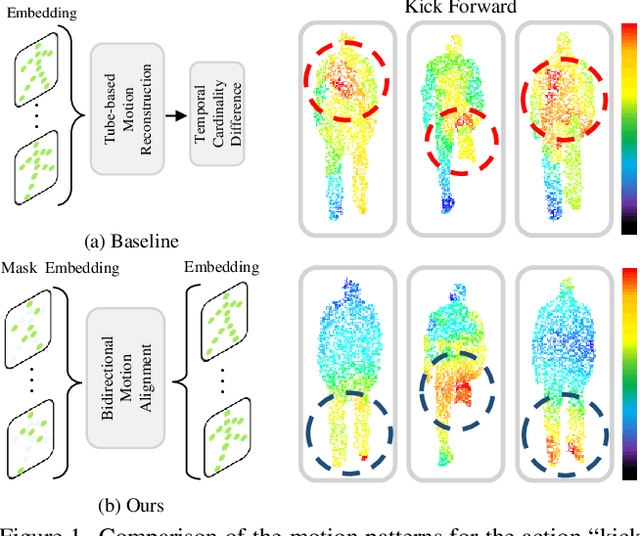
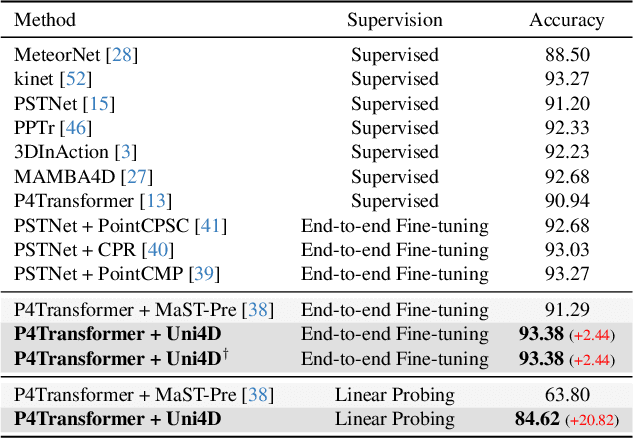
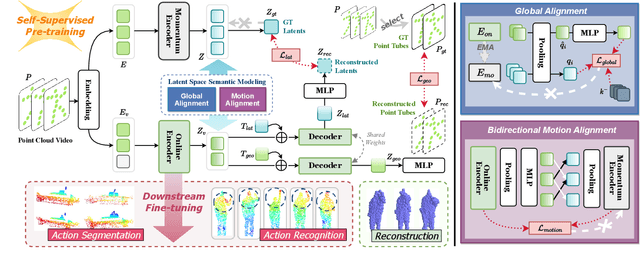

Point cloud video representation learning is primarily built upon the masking strategy in a self-supervised manner. However, the progress is slow due to several significant challenges: (1) existing methods learn the motion particularly with hand-crafted designs, leading to unsatisfactory motion patterns during pre-training which are non-transferable on fine-tuning scenarios. (2) previous Masked AutoEncoder (MAE) frameworks are limited in resolving the huge representation gap inherent in 4D data. In this study, we introduce the first self-disentangled MAE for learning discriminative 4D representations in the pre-training stage. To address the first challenge, we propose to model the motion representation in a latent space. The second issue is resolved by introducing the latent tokens along with the typical geometry tokens to disentangle high-level and low-level features during decoding. Extensive experiments on MSR-Action3D, NTU-RGBD, HOI4D, NvGesture, and SHREC'17 verify this self-disentangled learning framework. We demonstrate that it can boost the fine-tuning performance on all 4D tasks, which we term Uni4D. Our pre-trained model presents discriminative and meaningful 4D representations, particularly benefits processing long videos, as Uni4D gets $+3.8\%$ segmentation accuracy on HOI4D, significantly outperforming either self-supervised or fully-supervised methods after end-to-end fine-tuning.
Relevance-guided Audio Visual Fusion for Video Saliency Prediction
Nov 18, 2024
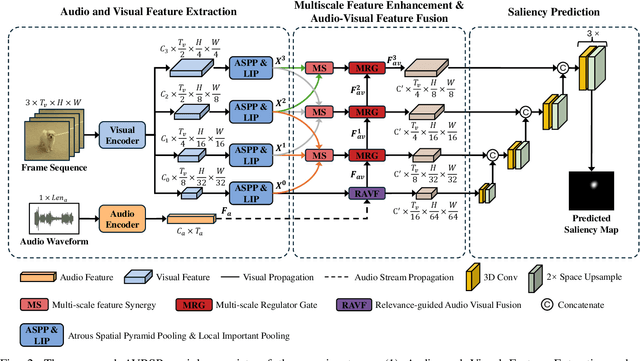
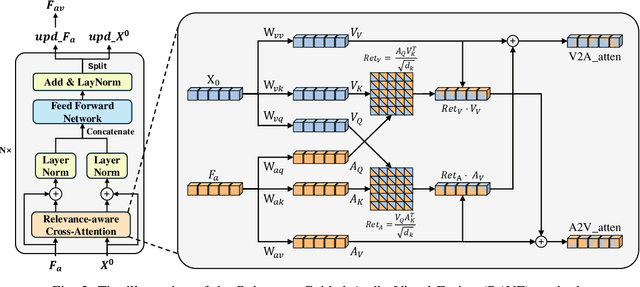
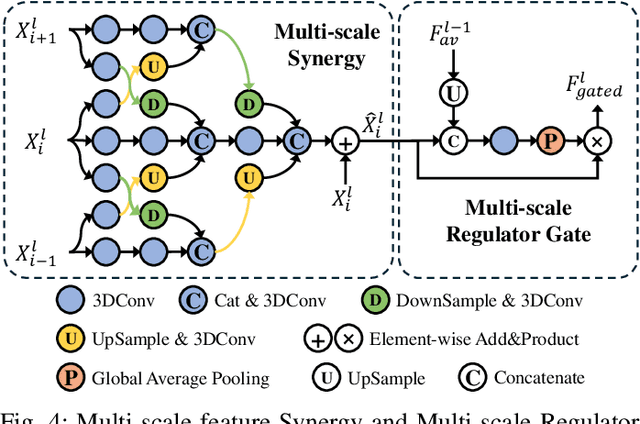
Audio data, often synchronized with video frames, plays a crucial role in guiding the audience's visual attention. Incorporating audio information into video saliency prediction tasks can enhance the prediction of human visual behavior. However, existing audio-visual saliency prediction methods often directly fuse audio and visual features, which ignore the possibility of inconsistency between the two modalities, such as when the audio serves as background music. To address this issue, we propose a novel relevance-guided audio-visual saliency prediction network dubbed AVRSP. Specifically, the Relevance-guided Audio-Visual feature Fusion module (RAVF) dynamically adjusts the retention of audio features based on the semantic relevance between audio and visual elements, thereby refining the integration process with visual features. Furthermore, the Multi-scale feature Synergy (MS) module integrates visual features from different encoding stages, enhancing the network's ability to represent objects at various scales. The Multi-scale Regulator Gate (MRG) could transfer crucial fusion information to visual features, thus optimizing the utilization of multi-scale visual features. Extensive experiments on six audio-visual eye movement datasets have demonstrated that our AVRSP network achieves competitive performance in audio-visual saliency prediction.
Att2CPC: Attention-Guided Lossy Attribute Compression of Point Clouds
Oct 23, 2024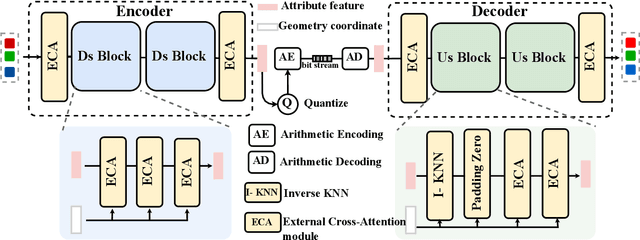

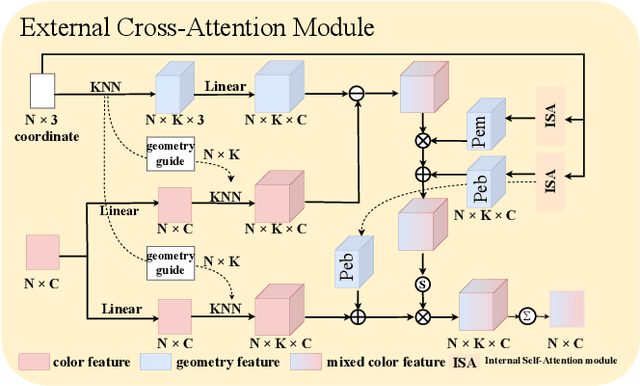
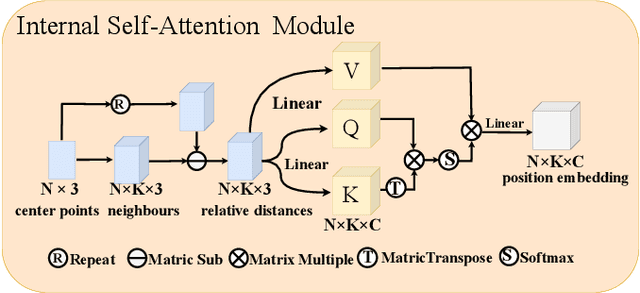
With the great progress of 3D sensing and acquisition technology, the volume of point cloud data has grown dramatically, which urges the development of efficient point cloud compression methods. In this paper, we focus on the task of learned lossy point cloud attribute compression (PCAC). We propose an efficient attention-based method for lossy compression of point cloud attributes leveraging on an autoencoder architecture. Specifically, at the encoding side, we conduct multiple downsampling to best exploit the local attribute patterns, in which effective External Cross Attention (ECA) is devised to hierarchically aggregate features by intergrating attributes and geometry contexts. At the decoding side, the attributes of the point cloud are progressively reconstructed based on the multi-scale representation and the zero-padding upsampling tactic. To the best of our knowledge, this is the first approach to introduce attention mechanism to point-based lossy PCAC task. We verify the compression efficiency of our model on various sequences, including human body frames, sparse objects, and large-scale point cloud scenes. Experiments show that our method achieves an average improvement of 1.15 dB and 2.13 dB in BD-PSNR of Y channel and YUV channel, respectively, when comparing with the state-of-the-art point-based method Deep-PCAC. Codes of this paper are available at https://github.com/I2-Multimedia-Lab/Att2CPC.
DiffuseST: Unleashing the Capability of the Diffusion Model for Style Transfer
Oct 19, 2024
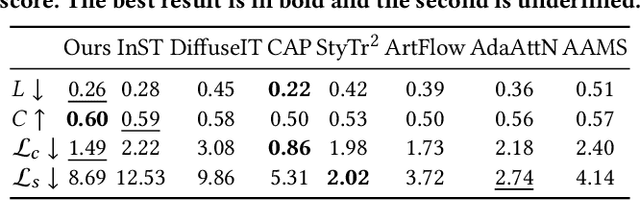
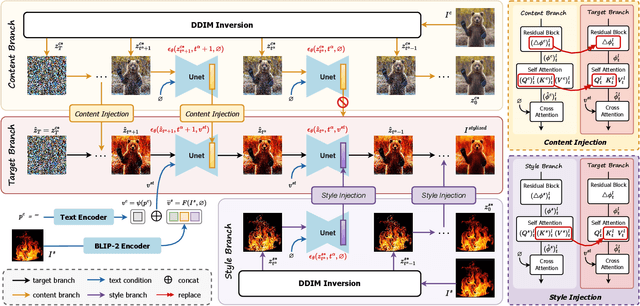

Style transfer aims to fuse the artistic representation of a style image with the structural information of a content image. Existing methods train specific networks or utilize pre-trained models to learn content and style features. However, they rely solely on textual or spatial representations that are inadequate to achieve the balance between content and style. In this work, we propose a novel and training-free approach for style transfer, combining textual embedding with spatial features and separating the injection of content or style. Specifically, we adopt the BLIP-2 encoder to extract the textual representation of the style image. We utilize the DDIM inversion technique to extract intermediate embeddings in content and style branches as spatial features. Finally, we harness the step-by-step property of diffusion models by separating the injection of content and style in the target branch, which improves the balance between content preservation and style fusion. Various experiments have demonstrated the effectiveness and robustness of our proposed DiffeseST for achieving balanced and controllable style transfer results, as well as the potential to extend to other tasks.
Magnet: We Never Know How Text-to-Image Diffusion Models Work, Until We Learn How Vision-Language Models Function
Sep 30, 2024



Text-to-image diffusion models particularly Stable Diffusion, have revolutionized the field of computer vision. However, the synthesis quality often deteriorates when asked to generate images that faithfully represent complex prompts involving multiple attributes and objects. While previous studies suggest that blended text embeddings lead to improper attribute binding, few have explored this in depth. In this work, we critically examine the limitations of the CLIP text encoder in understanding attributes and investigate how this affects diffusion models. We discern a phenomenon of attribute bias in the text space and highlight a contextual issue in padding embeddings that entangle different concepts. We propose \textbf{Magnet}, a novel training-free approach to tackle the attribute binding problem. We introduce positive and negative binding vectors to enhance disentanglement, further with a neighbor strategy to increase accuracy. Extensive experiments show that Magnet significantly improves synthesis quality and binding accuracy with negligible computational cost, enabling the generation of unconventional and unnatural concepts.
Bridging Domain Gap of Point Cloud Representations via Self-Supervised Geometric Augmentation
Sep 11, 2024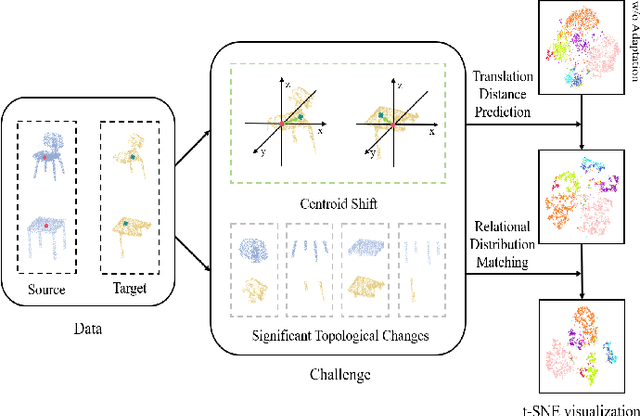
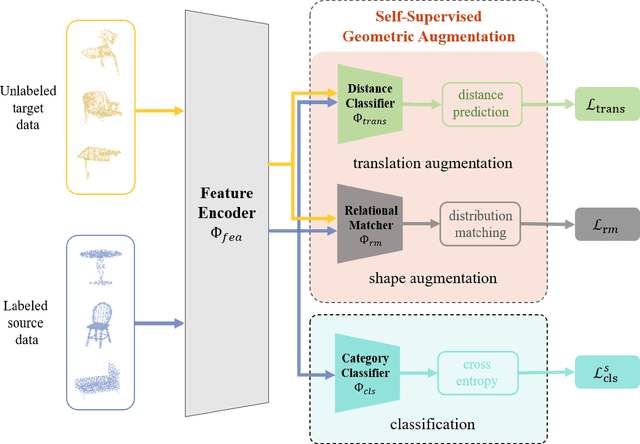
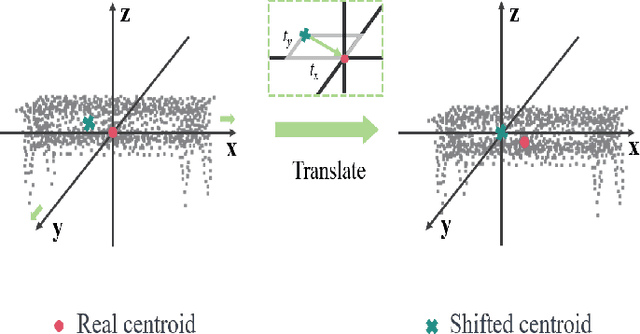
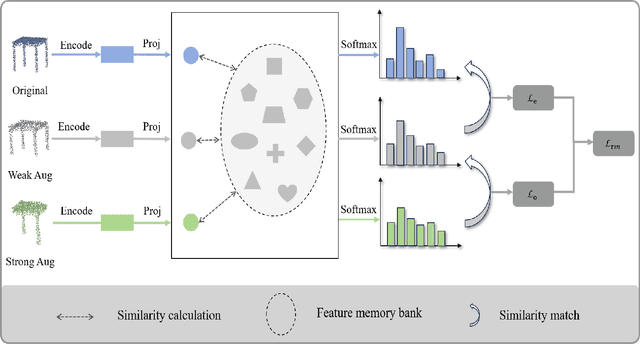
Recent progress of semantic point clouds analysis is largely driven by synthetic data (e.g., the ModelNet and the ShapeNet), which are typically complete, well-aligned and noisy free. Therefore, representations of those ideal synthetic point clouds have limited variations in the geometric perspective and can gain good performance on a number of 3D vision tasks such as point cloud classification. In the context of unsupervised domain adaptation (UDA), representation learning designed for synthetic point clouds can hardly capture domain invariant geometric patterns from incomplete and noisy point clouds. To address such a problem, we introduce a novel scheme for induced geometric invariance of point cloud representations across domains, via regularizing representation learning with two self-supervised geometric augmentation tasks. On one hand, a novel pretext task of predicting translation distances of augmented samples is proposed to alleviate centroid shift of point clouds due to occlusion and noises. On the other hand, we pioneer an integration of the relational self-supervised learning on geometrically-augmented point clouds in a cascade manner, utilizing the intrinsic relationship of augmented variants and other samples as extra constraints of cross-domain geometric features. Experiments on the PointDA-10 dataset demonstrate the effectiveness of the proposed method, achieving the state-of-the-art performance.