 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni4D: A Unified Self-Supervised Learning Framework for Point Cloud Videos
Apr 07, 2025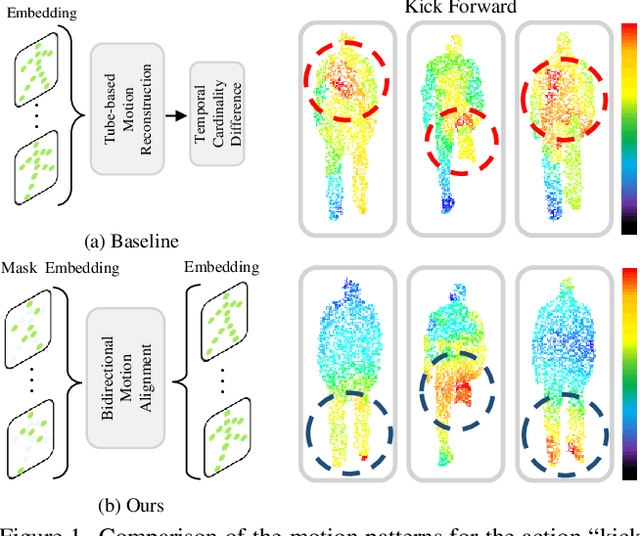
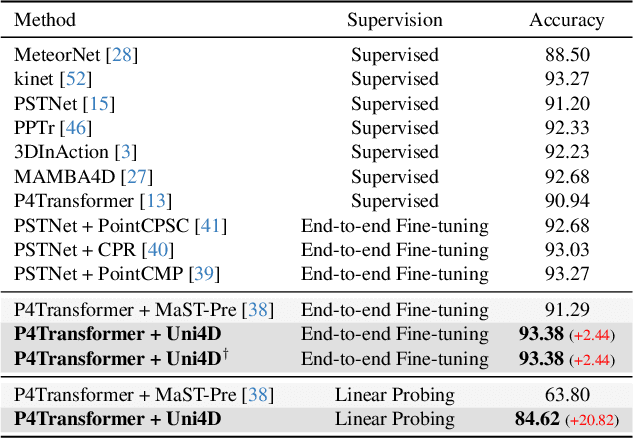
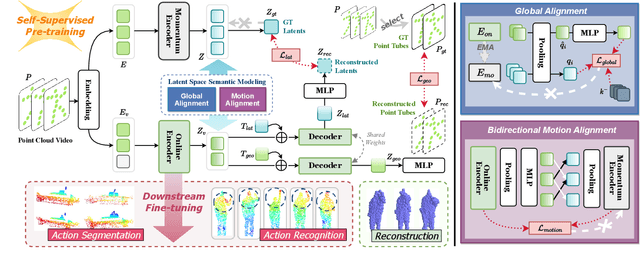

Point cloud video representation learning is primarily built upon the masking strategy in a self-supervised manner. However, the progress is slow due to several significant challenges: (1) existing methods learn the motion particularly with hand-crafted designs, leading to unsatisfactory motion patterns during pre-training which are non-transferable on fine-tuning scenarios. (2) previous Masked AutoEncoder (MAE) frameworks are limited in resolving the huge representation gap inherent in 4D data. In this study, we introduce the first self-disentangled MAE for learning discriminative 4D representations in the pre-training stage. To address the first challenge, we propose to model the motion representation in a latent space. The second issue is resolved by introducing the latent tokens along with the typical geometry tokens to disentangle high-level and low-level features during decoding. Extensive experiments on MSR-Action3D, NTU-RGBD, HOI4D, NvGesture, and SHREC'17 verify this self-disentangled learning framework. We demonstrate that it can boost the fine-tuning performance on all 4D tasks, which we term Uni4D. Our pre-trained model presents discriminative and meaningful 4D representations, particularly benefits processing long videos, as Uni4D gets $+3.8\%$ segmentation accuracy on HOI4D, significantly outperforming either self-supervised or fully-supervised methods after end-to-end fine-tuning.
WonderVerse: Extendable 3D Scene Generation with Video Generative Models
Mar 13, 2025We introduce \textit{WonderVerse}, a simple but effective framework for generating extendable 3D scenes. Unlike existing methods that rely on iterative depth estimation and image inpainting, often leading to geometric distortions and inconsistencies, WonderVerse leverages the powerful world-level priors embedded within video generative foundation models to create highly immersive and geometrically coherent 3D environments. Furthermore, we propose a new technique for controllable 3D scene extension to substantially increase the scale of the generated environments. Besides, we introduce a novel abnormal sequence detection module that utilizes camera trajectory to address geometric inconsistency in the generated videos. Finally, WonderVerse is compatible with various 3D reconstruction methods, allowing both efficient and high-quality generation. Extensive experiments on 3D scene generation demonstrate that our WonderVerse, with an elegant and simple pipeline, delivers extendable and highly-realistic 3D scenes, markedly outperforming existing works that rely on more complex architectures.