 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Generative Infrared and Visible Image Fusion Based on Human Cognitive Laws
Oct 30, 2025Existing infrared and visible image fusion methods often face the dilemma of balancing modal information. Generative fusion methods reconstruct fused images by learning from data distributions, but their generative capabilities remain limited. Moreover, the lack of interpretability in modal information selection further affects the reliability and consistency of fusion results in complex scenarios. This manuscript revisits the essence of generative image fusion under the inspiration of human cognitive laws and proposes a novel infrared and visible image fusion method, termed HCLFuse. First, HCLFuse investigates the quantification theory of information mapping in unsupervised fusion networks, which leads to the design of a multi-scale mask-regulated variational bottleneck encoder. This encoder applies posterior probability modeling and information decomposition to extract accurate and concise low-level modal information, thereby supporting the generation of high-fidelity structural details. Furthermore, the probabilistic generative capability of the diffusion model is integrated with physical laws, forming a time-varying physical guidance mechanism that adaptively regulates the generation process at different stages, thereby enhancing the ability of the model to perceive the intrinsic structure of data and reducing dependence on data quality. Experimental results show that the proposed method achieves state-of-the-art fusion performance in qualitative and quantitative evaluations across multiple datasets and significantly improves semantic segmentation metrics. This fully demonstrates the advantages of this generative image fusion method, drawing inspiration from human cognition, in enhancing structural consistency and detail quality.
LLM-Crowdsourced: A Benchmark-Free Paradigm for Mutual Evaluation of Large Language Models
Jul 30, 2025Although large language models (LLMs) demonstrate remarkable capabilities across various tasks, evaluating their capabilities remains a challenging task. Existing evaluation methods suffer from issues such as data contamination, black-box operation, and subjective preference. These issues make it difficult to evaluate the LLMs' true capabilities comprehensively. To tackle these challenges, we propose a novel benchmark-free evaluation paradigm, LLM-Crowdsourced. It utilizes LLMs to generate questions, answer independently, and evaluate mutually. This method integrates four key evaluation criteria: dynamic, transparent, objective, and professional, which existing evaluation methods cannot satisfy simultaneously. Experiments on eight mainstream LLMs across mathematics and programming verify the advantages of our method in distinguishing LLM performance. Furthermore, our study reveals several novel findings that are difficult for traditional methods to detect, including but not limited to: (1) Gemini demonstrates the highest original and professional question-design capabilities among others; (2) Some LLMs exhibit ''memorization-based answering'' by misrecognizing questions as familiar ones with a similar structure; (3) LLM evaluation results demonstrate high consistency (robustness).
DeepGo: Predictive Directed Greybox Fuzzing
Jul 29, 2025The state-of-the-art DGF techniques redefine and optimize the fitness metric to reach the target sites precisely and quickly. However, optimizations for fitness metrics are mainly based on heuristic algorithms, which usually rely on historical execution information and lack foresight on paths that have not been exercised yet. Thus, those hard-to-execute paths with complex constraints would hinder DGF from reaching the targets, making DGF less efficient. In this paper, we propose DeepGo, a predictive directed grey-box fuzzer that can combine historical and predicted information to steer DGF to reach the target site via an optimal path. We first propose the path transition model, which models DGF as a process of reaching the target site through specific path transition sequences. The new seed generated by mutation would cause the path transition, and the path corresponding to the high-reward path transition sequence indicates a high likelihood of reaching the target site through it. Then, to predict the path transitions and the corresponding rewards, we use deep neural networks to construct a Virtual Ensemble Environment (VEE), which gradually imitates the path transition model and predicts the rewards of path transitions that have not been taken yet. To determine the optimal path, we develop a Reinforcement Learning for Fuzzing (RLF) model to generate the transition sequences with the highest sequence rewards. The RLF model can combine historical and predicted path transitions to generate the optimal path transition sequences, along with the policy to guide the mutation strategy of fuzzing. Finally, to exercise the high-reward path transition sequence, we propose the concept of an action group, which comprehensively optimizes the critical steps of fuzzing to realize the optimal path to reach the target efficiently.
MARS: Radio Map Super-resolution and Reconstruction Method under Sparse Channel Measurements
Jun 06, 2025Radio maps reflect the spatial distribution of signal strength and are essential for applications like smart cities, IoT, and wireless network planning. However, reconstructing accurate radio maps from sparse measurements remains challenging. Traditional interpolation and inpainting methods lack environmental awareness, while many deep learning approaches depend on detailed scene data, limiting generalization. To address this, we propose MARS, a Multi-scale Aware Radiomap Super-resolution method that combines CNNs and Transformers with multi-scale feature fusion and residual connections. MARS focuses on both global and local feature extraction, enhancing feature representation across different receptive fields and improving reconstruction accuracy. Experiments across different scenes and antenna locations show that MARS outperforms baseline models in both MSE and SSIM, while maintaining low computational cost, demonstrating strong practical potential.
A Symbolic and Statistical Learning Framework to Discover Bioprocessing Regulatory Mechanism: Cell Culture Example
May 06, 2025

Bioprocess mechanistic modeling is essential for advancing intelligent digital twin representation of biomanufacturing, yet challenges persist due to complex intracellular regulation, stochastic system behavior, and limited experimental data. This paper introduces a symbolic and statistical learning framework to identify key regulatory mechanisms and quantify model uncertainty. Bioprocess dynamics is formulated with stochastic differential equations characterizing intrinsic process variability, with a predefined set of candidate regulatory mechanisms constructed from biological knowledge. A Bayesian learning approach is developed, which is based on a joint learning of kinetic parameters and regulatory structure through a formulation of the mixture model. To enhance computational efficiency, a Metropolis-adjusted Langevin algorithm with adjoint sensitivity analysis is developed for posterior exploration. Compared to state-of-the-art Bayesian inference approaches, the proposed framework achieves improved sample efficiency and robust model selection. An empirical study demonstrates its ability to recover missing regulatory mechanisms and improve model fidelity under data-limited conditions.
Disentangled 4D Gaussian Splatting: Towards Faster and More Efficient Dynamic Scene Rendering
Mar 31, 2025


Novel-view synthesis (NVS) for dynamic scenes from 2D images presents significant challenges due to the spatial complexity and temporal variability of such scenes. Recently, inspired by the remarkable success of NVS using 3D Gaussian Splatting (3DGS), researchers have sought to extend 3D Gaussian models to four dimensions (4D) for dynamic novel-view synthesis. However, methods based on 4D rotation and scaling introduce spatiotemporal deformation into the 4D covariance matrix, necessitating the slicing of 4D Gaussians into 3D Gaussians. This process increases redundant computations as timestamps change-an inherent characteristic of dynamic scene rendering. Additionally, performing calculations on a four-dimensional matrix is computationally intensive. In this paper, we introduce Disentangled 4D Gaussian Splatting (Disentangled4DGS), a novel representation and rendering approach that disentangles temporal and spatial deformations, thereby eliminating the reliance on 4D matrix computations. We extend the 3DGS rendering process to 4D, enabling the projection of temporal and spatial deformations into dynamic 2D Gaussians in ray space. Consequently, our method facilitates faster dynamic scene synthesis. Moreover, it reduces storage requirements by at least 4.5\% due to our efficient presentation method. Our approach achieves an unprecedented average rendering speed of 343 FPS at a resolution of $1352\times1014$ on an RTX 3090 GPU, with experiments across multiple benchmarks demonstrating its competitive performance in both monocular and multi-view scenarios.
WonderVerse: Extendable 3D Scene Generation with Video Generative Models
Mar 13, 2025We introduce \textit{WonderVerse}, a simple but effective framework for generating extendable 3D scenes. Unlike existing methods that rely on iterative depth estimation and image inpainting, often leading to geometric distortions and inconsistencies, WonderVerse leverages the powerful world-level priors embedded within video generative foundation models to create highly immersive and geometrically coherent 3D environments. Furthermore, we propose a new technique for controllable 3D scene extension to substantially increase the scale of the generated environments. Besides, we introduce a novel abnormal sequence detection module that utilizes camera trajectory to address geometric inconsistency in the generated videos. Finally, WonderVerse is compatible with various 3D reconstruction methods, allowing both efficient and high-quality generation. Extensive experiments on 3D scene generation demonstrate that our WonderVerse, with an elegant and simple pipeline, delivers extendable and highly-realistic 3D scenes, markedly outperforming existing works that rely on more complex architectures.
Purest Quantum State Identification
Feb 20, 2025
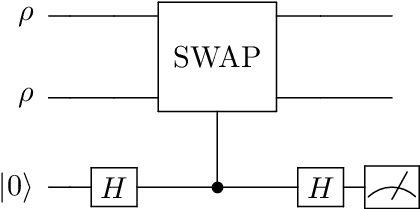
Precise identification of quantum states under noise constraints is essential for quantum information processing. In this study, we generalize the classical best arm identification problem to quantum domains, designing methods for identifying the purest one within $K$ unknown $n$-qubit quantum states using $N$ samples. %, with direct applications in quantum computation and quantum communication. We propose two distinct algorithms: (1) an algorithm employing incoherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_1}{\log(K) 2^n }\right) \right)$, and (2) an algorithm utilizing coherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_2}{\log(K) }\right) \right)$, highlighting the power of quantum memory. Furthermore, we establish a lower bound by proving that all strategies with fixed two-outcome incoherent POVM must suffer error probability exceeding $ \exp\left( - O\left(\frac{NH_1}{2^n}\right)\right)$. This framework provides concrete design principles for overcoming sampling bottlenecks in quantum technologies.
Digital Twin Calibration with Model-Based Reinforcement Learning
Jan 04, 2025This paper presents a novel methodological framework, called the Actor-Simulator, that incorporates the calibration of digital twins into model-based reinforcement learning for more effective control of stochastic systems with complex nonlinear dynamics. Traditional model-based control often relies on restrictive structural assumptions (such as linear state transitions) and fails to account for parameter uncertainty in the model. These issues become particularly critical in industries such as biopharmaceutical manufacturing, where process dynamics are complex and not fully known, and only a limited amount of data is available. Our approach jointly calibrates the digital twin and searches for an optimal control policy, thus accounting for and reducing model error. We balance exploration and exploitation by using policy performance as a guide for data collection. This dual-component approach provably converges to the optimal policy, and outperforms existing methods in extensive numerical experiments based on the biopharmaceutical manufacturing domain.
Active Learning with Variational Quantum Circuits for Quantum Process Tomography
Dec 30, 2024



Quantum process tomography (QPT), used for reconstruction of an unknown quantum process from measurement data, is a fundamental tool for the diagnostic and full characterization of quantum systems. It relies on querying a set of quantum states as input to the quantum process. Previous works commonly use a straightforward strategy to select a set of quantum states randomly, overlooking differences in informativeness among quantum states. Since querying the quantum system requires multiple experiments that can be prohibitively costly, it is always the case that there are not enough quantum states for high-quality reconstruction. In this paper, we propose a general framework for active learning (AL) to adaptively select a set of informative quantum states that improves the reconstruction most efficiently. In particular, we introduce a learning framework that leverages the widely-used variational quantum circuits (VQCs) to perform the QPT task and integrate our AL algorithms into the query step. We design and evaluate three various types of AL algorithms: committee-based, uncertainty-based, and diversity-based, each exhibiting distinct advantages in terms of performance and computational cost. Additionally, we provide a guideline for selecting algorithms suitable for different scenarios. Numerical results demonstrate that our algorithms achieve significantly improved reconstruction compared to the baseline method that selects a set of quantum states randomly. Moreover, these results suggest that active learning based approaches are applicable to other complicated learning tasks in large-scale quantum information processing.