 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnzyPGM: Pocket-conditioned Generative Model for Substrate-specific Enzyme Design
Jan 27, 2026Designing enzymes with substrate-binding pockets is a critical challenge in protein engineering, as catalytic activity depends on the precise interaction between pockets and substrates. Currently, generative models dominate functional protein design but cannot model pocket-substrate interactions, which limits the generation of enzymes with precise catalytic environments. To address this issue, we propose EnzyPGM, a unified framework that jointly generates enzymes and substrate-binding pockets conditioned on functional priors and substrates, with a particular focus on learning accurate pocket-substrate interactions. At its core, EnzyPGM includes two main modules: a Residue-atom Bi-scale Attention (RBA) that jointly models intra-residue dependencies and fine-grained interactions between pocket residues and substrate atoms, and a Residue Function Fusion (RFF) that incorporates enzyme function priors into residue representations. Also, we curate EnzyPock, an enzyme-pocket dataset comprising 83,062 enzyme-substrate pairs across 1,036 four-level enzyme families. Extensive experiments demonstrate that EnzyPGM achieves state-of-the-art performance on EnzyPock. Notably, EnzyPGM reduces the average binding energy of 0.47 kcal/mol over EnzyGen, showing its superior performance on substrate-specific enzyme design. The code and dataset will be released later.
Mitigating Cultural Bias in LLMs via Multi-Agent Cultural Debate
Jan 17, 2026Large language models (LLMs) exhibit systematic Western-centric bias, yet whether prompting in non-Western languages (e.g., Chinese) can mitigate this remains understudied. Answering this question requires rigorous evaluation and effective mitigation, but existing approaches fall short on both fronts: evaluation methods force outputs into predefined cultural categories without a neutral option, while mitigation relies on expensive multi-cultural corpora or agent frameworks that use functional roles (e.g., Planner--Critique) lacking explicit cultural representation. To address these gaps, we introduce CEBiasBench, a Chinese--English bilingual benchmark, and Multi-Agent Vote (MAV), which enables explicit ``no bias'' judgments. Using this framework, we find that Chinese prompting merely shifts bias toward East Asian perspectives rather than eliminating it. To mitigate such persistent bias, we propose Multi-Agent Cultural Debate (MACD), a training-free framework that assigns agents distinct cultural personas and orchestrates deliberation via a "Seeking Common Ground while Reserving Differences" strategy. Experiments demonstrate that MACD achieves 57.6% average No Bias Rate evaluated by LLM-as-judge and 86.0% evaluated by MAV (vs. 47.6% and 69.0% baseline using GPT-4o as backbone) on CEBiasBench and generalizes to the Arabic CAMeL benchmark, confirming that explicit cultural representation in agent frameworks is essential for cross-cultural fairness.
TARAC: Mitigating Hallucination in LVLMs via Temporal Attention Real-time Accumulative Connection
Apr 05, 2025



Large Vision-Language Models have demonstrated remarkable performance across various tasks; however, the challenge of hallucinations constrains their practical applications. The hallucination problem arises from multiple factors, including the inherent hallucinations in language models, the limitations of visual encoders in perception, and biases introduced by multimodal data. Extensive research has explored ways to mitigate hallucinations. For instance, OPERA prevents the model from overly focusing on "anchor tokens", thereby reducing hallucinations, whereas VCD mitigates hallucinations by employing a contrastive decoding approach. In this paper, we investigate the correlation between the decay of attention to image tokens and the occurrence of hallucinations. Based on this finding, we propose Temporal Attention Real-time Accumulative Connection (TARAC), a novel training-free method that dynamically accumulates and updates LVLMs' attention on image tokens during generation. By enhancing the model's attention to image tokens, TARAC mitigates hallucinations caused by the decay of attention on image tokens. We validate the effectiveness of TARAC across multiple models and datasets, demonstrating that our approach substantially mitigates hallucinations. In particular, TARAC reduces $C_S$ by 25.2 and $C_I$ by 8.7 compared to VCD on the CHAIR benchmark.
R$^2$: A LLM Based Novel-to-Screenplay Generation Framework with Causal Plot Graphs
Mar 19, 2025



Automatically adapting novels into screenplays is important for the TV, film, or opera industries to promote products with low costs. The strong performances of large language models (LLMs) in long-text generation call us to propose a LLM based framework Reader-Rewriter (R$^2$) for this task. However, there are two fundamental challenges here. First, the LLM hallucinations may cause inconsistent plot extraction and screenplay generation. Second, the causality-embedded plot lines should be effectively extracted for coherent rewriting. Therefore, two corresponding tactics are proposed: 1) A hallucination-aware refinement method (HAR) to iteratively discover and eliminate the affections of hallucinations; and 2) a causal plot-graph construction method (CPC) based on a greedy cycle-breaking algorithm to efficiently construct plot lines with event causalities. Recruiting those efficient techniques, R$^2$ utilizes two modules to mimic the human screenplay rewriting process: The Reader module adopts a sliding window and CPC to build the causal plot graphs, while the Rewriter module generates first the scene outlines based on the graphs and then the screenplays. HAR is integrated into both modules for accurate inferences of LLMs. Experimental results demonstrate the superiority of R$^2$, which substantially outperforms three existing approaches (51.3%, 22.6%, and 57.1% absolute increases) in pairwise comparison at the overall win rate for GPT-4o.
S$^2$-MAD: Breaking the Token Barrier to Enhance Multi-Agent Debate Efficiency
Feb 07, 2025



Large language models (LLMs) have demonstrated remarkable capabilities across various natural language processing (NLP) scenarios, but they still face challenges when handling complex arithmetic and logical reasoning tasks. While Chain-Of-Thought (CoT) reasoning, self-consistency (SC) and self-correction strategies have attempted to guide models in sequential, multi-step reasoning, Multi-agent Debate (MAD) has emerged as a viable approach for enhancing the reasoning capabilities of LLMs. By increasing both the number of agents and the frequency of debates, the performance of LLMs improves significantly. However, this strategy results in a significant increase in token costs, presenting a barrier to scalability. To address this challenge, we introduce a novel sparsification strategy designed to reduce token costs within MAD. This approach minimizes ineffective exchanges of information and unproductive discussions among agents, thereby enhancing the overall efficiency of the debate process. We conduct comparative experiments on multiple datasets across various models, demonstrating that our approach significantly reduces the token costs in MAD to a considerable extent. Specifically, compared to MAD, our approach achieves an impressive reduction of up to 94.5\% in token costs while maintaining performance degradation below 2.0\%.
Active Learning with Variational Quantum Circuits for Quantum Process Tomography
Dec 30, 2024



Quantum process tomography (QPT), used for reconstruction of an unknown quantum process from measurement data, is a fundamental tool for the diagnostic and full characterization of quantum systems. It relies on querying a set of quantum states as input to the quantum process. Previous works commonly use a straightforward strategy to select a set of quantum states randomly, overlooking differences in informativeness among quantum states. Since querying the quantum system requires multiple experiments that can be prohibitively costly, it is always the case that there are not enough quantum states for high-quality reconstruction. In this paper, we propose a general framework for active learning (AL) to adaptively select a set of informative quantum states that improves the reconstruction most efficiently. In particular, we introduce a learning framework that leverages the widely-used variational quantum circuits (VQCs) to perform the QPT task and integrate our AL algorithms into the query step. We design and evaluate three various types of AL algorithms: committee-based, uncertainty-based, and diversity-based, each exhibiting distinct advantages in terms of performance and computational cost. Additionally, we provide a guideline for selecting algorithms suitable for different scenarios. Numerical results demonstrate that our algorithms achieve significantly improved reconstruction compared to the baseline method that selects a set of quantum states randomly. Moreover, these results suggest that active learning based approaches are applicable to other complicated learning tasks in large-scale quantum information processing.
TrojFlow: Flow Models are Natural Targets for Trojan Attacks
Dec 21, 2024



Flow-based generative models (FMs) have rapidly advanced as a method for mapping noise to data, its efficient training and sampling process makes it widely applicable in various fields. FMs can be viewed as a variant of diffusion models (DMs). At the same time, previous studies have shown that DMs are vulnerable to Trojan/Backdoor attacks, a type of output manipulation attack triggered by a maliciously embedded pattern at model input. We found that Trojan attacks on generative models are essentially equivalent to image transfer tasks from the backdoor distribution to the target distribution, the unique ability of FMs to fit any two arbitrary distributions significantly simplifies the training and sampling setups for attacking FMs, making them inherently natural targets for backdoor attacks. In this paper, we propose TrojFlow, exploring the vulnerabilities of FMs through Trojan attacks. In particular, we consider various attack settings and their combinations and thoroughly explore whether existing defense methods for DMs can effectively defend against our proposed attack scenarios. We evaluate TrojFlow on CIFAR-10 and CelebA datasets, our experiments show that our method can compromise FMs with high utility and specificity, and can easily break through existing defense mechanisms.
Modality Alignment Meets Federated Broadcasting
Nov 24, 2024Federated learning (FL) has emerged as a powerful approach to safeguard data privacy by training models across distributed edge devices without centralizing local data. Despite advancements in homogeneous data scenarios, maintaining performance between the global and local clients in FL over heterogeneous data remains challenging due to data distribution variations that degrade model convergence and increase computational costs. This paper introduces a novel FL framework leveraging modality alignment, where a text encoder resides on the server, and image encoders operate on local devices. Inspired by multi-modal learning paradigms like CLIP, this design aligns cross-client learning by treating server-client communications akin to multi-modal broadcasting. We initialize with a pre-trained model to mitigate overfitting, updating select parameters through low-rank adaptation (LoRA) to meet computational demand and performance efficiency. Local models train independently and communicate updates to the server, which aggregates parameters via a query-based method, facilitating cross-client knowledge sharing and performance improvement under extreme heterogeneity. Extensive experiments on benchmark datasets demonstrate the efficacy in maintaining generalization and robustness, even in highly heterogeneous settings.
FoPru: Focal Pruning for Efficient Large Vision-Language Models
Nov 21, 2024



Large Vision-Language Models (LVLMs) represent a significant advancement toward achieving superior multimodal capabilities by enabling powerful Large Language Models (LLMs) to understand visual input. Typically, LVLMs utilize visual encoders, such as CLIP, to transform images into visual tokens, which are then aligned with textual tokens through projection layers before being input into the LLM for inference. Although existing LVLMs have achieved significant success, their inference efficiency is still limited by the substantial number of visual tokens and the potential redundancy among them. To mitigate this issue, we propose Focal Pruning (FoPru), a training-free method that prunes visual tokens based on the attention-based token significance derived from the vision encoder. Specifically, we introduce two alternative pruning strategies: 1) the rank strategy, which leverages all token significance scores to retain more critical tokens in a global view; 2) the row strategy, which focuses on preserving continuous key information in images from a local perspective. Finally, the selected tokens are reordered to maintain their original positional relationships. Extensive experiments across various LVLMs and multimodal datasets demonstrate that our method can prune a large number of redundant tokens while maintaining high accuracy, leading to significant improvements in inference efficiency.
Symbolic Learning Enables Self-Evolving Agents
Jun 26, 2024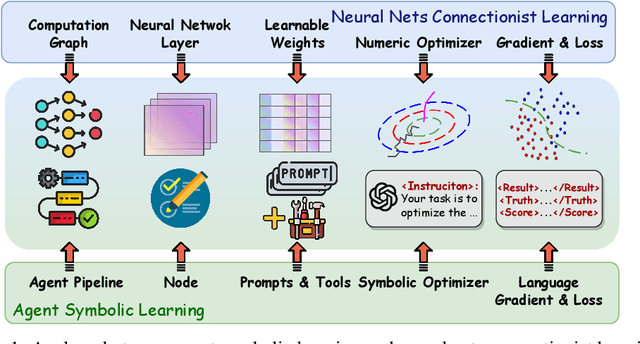
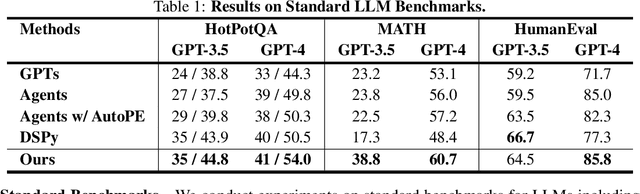
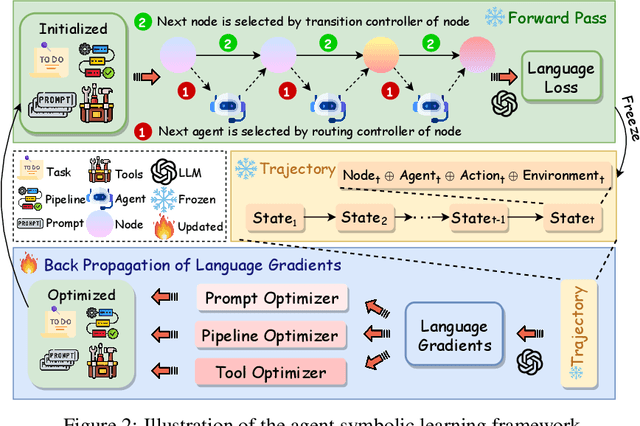
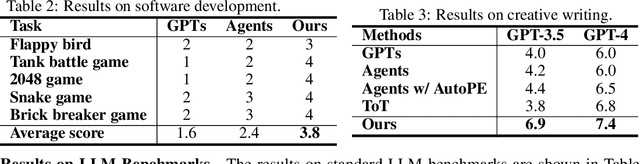
The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".