 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Conflict-Oriented Reasoning for General Multimodal Manipulation Detection
Jun 02, 2026The rapid rise of generative AI has made multimodal fake news increasingly realistic and pervasive, posing severe threats to public trust and social stability. Existing detection methods rely heavily on manipulation-specific models and large-scale labeled data, resulting in poor generalization to emerging manipulation types. We observed that the essence of manipulated misinformation lies in its intrinsic conflicts, \textbf{i.e.,} semantic or physical inconsistencies either across modalities or with common world knowledge. Inspired by this observation, we propose \textbf{C}onflict-\textbf{O}riented \textbf{RE}asoning (\textbf{CORE}) framework, an effective paradigm that learns to endows multimodal large language models (MLLMs) with explicit conflict-capturing capability. To this end, CORE first constructs the Conflict Attribution Corpus (CAC) with fine-grained annotations of conflict factors and sources, providing essential data support for subsequent conflict perception training. By performing conflict-oriented representation enhancement and reasoning based on CAC, CORE achieves robust and generalizable conflict detection, effectively and rapidly adapting to unseen manipulation types with a few samples or in even zero-shot settings. Extensive experiments demonstrate that CORE surpasses state-of-the-art models. The dataset and code are publicly available at https://github.com/shen8424/CORE.
Decoupled Training with Local Reinforcement Fine-Tuning in Federated Learning
May 27, 2026Federated Learning (FL) with pre-trained Vision-Language Models (VLMs) has emerged as a promising paradigm for various downstream tasks. By leveraging its strong representations, recent studies improve task adaptation under insufficient local data while preserving generalization. However, these methods emphasize fully local optimization with simple parameter aggregation,which can amplify inter-client optimization inconsistency and intra-client over-specialization under heterogeneous and full-data FL settings, making it difficult to balance global task adaptation and generalization. To address these challenges, we propose FedDTL, a novel federated VLM framework that decouples the image encoder and text encoder across clients and the server. Through decoupled encoder training with server-client modality alignment, FedDTL promotes coherent global semantic update and reduces inter-client optimization inconsistency, improving global task adaptation.To further mitigate intra-client over-specialization,we introduce a two-stage local fine-tuning, where a supervised fine-tuning stage enables rapid and reliable warm-start, followed by a reinforcement learning stage that enhances generalization. Extensive experiments on multiple benchmarks, including label skew and feature shift, demonstrate that FedDTL achieves an effective balance between global task adaptation and generalization under various FL data distributions in both few-shot and full-data regimes.
CanonSLR: Canonical-View Guided Multi-View Continuous Sign Language Recognition
Apr 20, 2026Continuous Sign Language Recognition (CSLR) has achieved remarkable progress in recent years; however, most existing methods are developed under single-view settings and thus remain insufficiently robust to viewpoint variations in real-world scenarios. To address this limitation, we propose CanonSLR, a canonical-view guided framework for multi-view CSLR. Specifically, we introduce a frontal-view-anchored teacher-student learning strategy, in which a teacher network trained on frontal-view data provides canonical temporal supervision for a student network trained on all viewpoints. To further reduce cross-view semantic discrepancy, we propose Sequence-Level Soft-Target Distillation, which transfers structured temporal knowledge from the frontal view to non-frontal samples, thereby alleviating gloss boundary ambiguity and category confusion caused by occlusion and projection variation. In addition, we introduce Temporal Motion Relational Enhancement to explicitly model motion-aware temporal relations in high-level visual features, strengthening stable dynamic representations while suppressing viewpoint-sensitive appearance disturbances. To support multi-view CSLR research, we further develop a universal multi-view sign language data construction pipeline that transforms original single-view RGB videos into semantically consistent, temporally coherent, and viewpoint-controllable multi-view sign language videos. Based on this pipeline, we extend PHOENIX-2014T and CSL-Daily into two seven-view benchmarks, namely PT14-MV and CSL-MV, providing a new experimental foundation for multi-view CSLR. Extensive experiments on PT14-MV and CSL-MV demonstrate that CanonSLR consistently outperforms existing approaches under multi-view settings and exhibits stronger robustness, especially on challenging non-frontal views.
OmniVL-Guard: Towards Unified Vision-Language Forgery Detection and Grounding via Balanced RL
Feb 12, 2026Existing forgery detection methods are often limited to uni-modal or bi-modal settings, failing to handle the interleaved text, images, and videos prevalent in real-world misinformation. To bridge this gap, this paper targets to develop a unified framework for omnibus vision-language forgery detection and grounding. In this unified setting, the {interplay} between diverse modalities and the dual requirements of simultaneous detection and localization pose a critical ``difficulty bias`` problem: the simpler veracity classification task tends to dominate the gradients, leading to suboptimal performance in fine-grained grounding during multi-task optimization. To address this challenge, we propose \textbf{OmniVL-Guard}, a balanced reinforcement learning framework for omnibus vision-language forgery detection and grounding. Particularly, OmniVL-Guard comprises two core designs: Self-Evolving CoT Generatio and Adaptive Reward Scaling Policy Optimization (ARSPO). {Self-Evolving CoT Generation} synthesizes high-quality reasoning paths, effectively overcoming the cold-start challenge. Building upon this, {Adaptive Reward Scaling Policy Optimization (ARSPO)} dynamically modulates reward scales and task weights, ensuring a balanced joint optimization. Extensive experiments demonstrate that OmniVL-Guard significantly outperforms state-of-the-art methods and exhibits zero-shot robust generalization across out-of-domain scenarios.
Data-Free Privacy-Preserving for LLMs via Model Inversion and Selective Unlearning
Jan 22, 2026Large language models (LLMs) exhibit powerful capabilities but risk memorizing sensitive personally identifiable information (PII) from their training data, posing significant privacy concerns. While machine unlearning techniques aim to remove such data, they predominantly depend on access to the training data. This requirement is often impractical, as training data in real-world deployments is commonly proprietary or inaccessible. To address this limitation, we propose Data-Free Selective Unlearning (DFSU), a novel privacy-preserving framework that removes sensitive PII from an LLM without requiring its training data. Our approach first synthesizes pseudo-PII through language model inversion, then constructs token-level privacy masks for these synthetic samples, and finally performs token-level selective unlearning via a contrastive mask loss within a low-rank adaptation (LoRA) subspace. Extensive experiments on the AI4Privacy PII-Masking dataset using Pythia models demonstrate that our method effectively removes target PII while maintaining model utility.
VDNeRF: Vision-only Dynamic Neural Radiance Field for Urban Scenes
Nov 09, 2025Neural Radiance Fields (NeRFs) implicitly model continuous three-dimensional scenes using a set of images with known camera poses, enabling the rendering of photorealistic novel views. However, existing NeRF-based methods encounter challenges in applications such as autonomous driving and robotic perception, primarily due to the difficulty of capturing accurate camera poses and limitations in handling large-scale dynamic environments. To address these issues, we propose Vision-only Dynamic NeRF (VDNeRF), a method that accurately recovers camera trajectories and learns spatiotemporal representations for dynamic urban scenes without requiring additional camera pose information or expensive sensor data. VDNeRF employs two separate NeRF models to jointly reconstruct the scene. The static NeRF model optimizes camera poses and static background, while the dynamic NeRF model incorporates the 3D scene flow to ensure accurate and consistent reconstruction of dynamic objects. To address the ambiguity between camera motion and independent object motion, we design an effective and powerful training framework to achieve robust camera pose estimation and self-supervised decomposition of static and dynamic elements in a scene. Extensive evaluations on mainstream urban driving datasets demonstrate that VDNeRF surpasses state-of-the-art NeRF-based pose-free methods in both camera pose estimation and dynamic novel view synthesis.
Open-World 3D Scene Graph Generation for Retrieval-Augmented Reasoning
Nov 08, 2025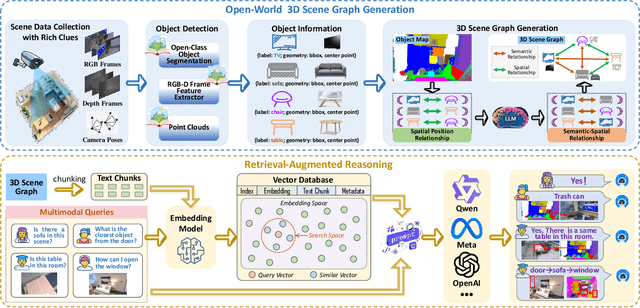

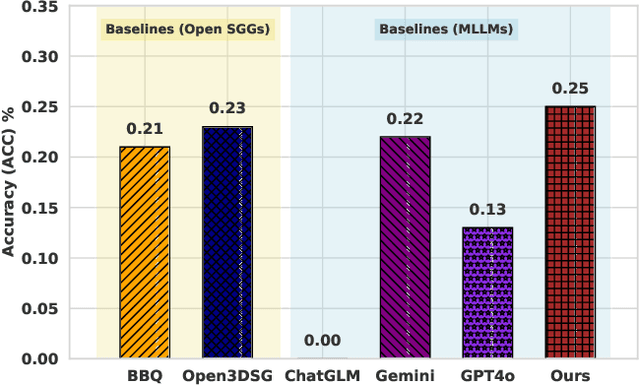
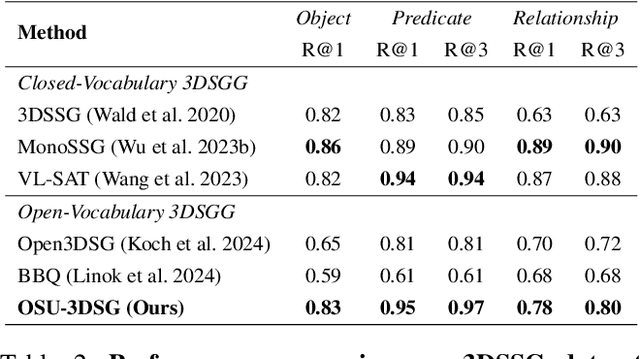
Understanding 3D scenes in open-world settings poses fundamental challenges for vision and robotics, particularly due to the limitations of closed-vocabulary supervision and static annotations. To address this, we propose a unified framework for Open-World 3D Scene Graph Generation with Retrieval-Augmented Reasoning, which enables generalizable and interactive 3D scene understanding. Our method integrates Vision-Language Models (VLMs) with retrieval-based reasoning to support multimodal exploration and language-guided interaction. The framework comprises two key components: (1) a dynamic scene graph generation module that detects objects and infers semantic relationships without fixed label sets, and (2) a retrieval-augmented reasoning pipeline that encodes scene graphs into a vector database to support text/image-conditioned queries. We evaluate our method on 3DSSG and Replica benchmarks across four tasks-scene question answering, visual grounding, instance retrieval, and task planning-demonstrating robust generalization and superior performance in diverse environments. Our results highlight the effectiveness of combining open-vocabulary perception with retrieval-based reasoning for scalable 3D scene understanding.
TDEdit: A Unified Diffusion Framework for Text-Drag Guided Image Manipulation
Sep 26, 2025This paper explores image editing under the joint control of text and drag interactions. While recent advances in text-driven and drag-driven editing have achieved remarkable progress, they suffer from complementary limitations: text-driven methods excel in texture manipulation but lack precise spatial control, whereas drag-driven approaches primarily modify shape and structure without fine-grained texture guidance. To address these limitations, we propose a unified diffusion-based framework for joint drag-text image editing, integrating the strengths of both paradigms. Our framework introduces two key innovations: (1) Point-Cloud Deterministic Drag, which enhances latent-space layout control through 3D feature mapping, and (2) Drag-Text Guided Denoising, dynamically balancing the influence of drag and text conditions during denoising. Notably, our model supports flexible editing modes - operating with text-only, drag-only, or combined conditions - while maintaining strong performance in each setting. Extensive quantitative and qualitative experiments demonstrate that our method not only achieves high-fidelity joint editing but also matches or surpasses the performance of specialized text-only or drag-only approaches, establishing a versatile and generalizable solution for controllable image manipulation. Code will be made publicly available to reproduce all results presented in this work.
Beyond Artificial Misalignment: Detecting and Grounding Semantic-Coordinated Multimodal Manipulations
Sep 16, 2025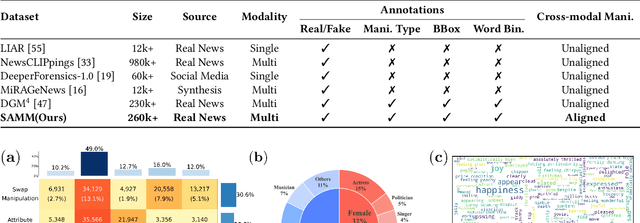
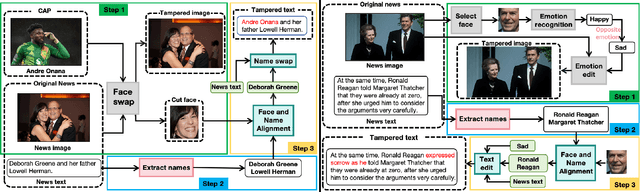
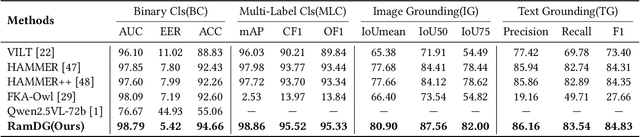
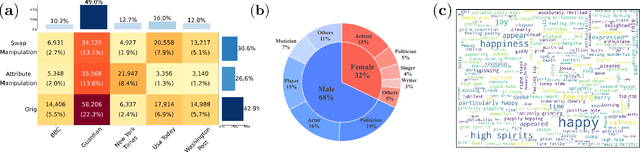
The detection and grounding of manipulated content in multimodal data has emerged as a critical challenge in media forensics. While existing benchmarks demonstrate technical progress, they suffer from misalignment artifacts that poorly reflect real-world manipulation patterns: practical attacks typically maintain semantic consistency across modalities, whereas current datasets artificially disrupt cross-modal alignment, creating easily detectable anomalies. To bridge this gap, we pioneer the detection of semantically-coordinated manipulations where visual edits are systematically paired with semantically consistent textual descriptions. Our approach begins with constructing the first Semantic-Aligned Multimodal Manipulation (SAMM) dataset, generated through a two-stage pipeline: 1) applying state-of-the-art image manipulations, followed by 2) generation of contextually-plausible textual narratives that reinforce the visual deception. Building on this foundation, we propose a Retrieval-Augmented Manipulation Detection and Grounding (RamDG) framework. RamDG commences by harnessing external knowledge repositories to retrieve contextual evidence, which serves as the auxiliary texts and encoded together with the inputs through our image forgery grounding and deep manipulation detection modules to trace all manipulations. Extensive experiments demonstrate our framework significantly outperforms existing methods, achieving 2.06\% higher detection accuracy on SAMM compared to state-of-the-art approaches. The dataset and code are publicly available at https://github.com/shen8424/SAMM-RamDG-CAP.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.