 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookNet: Book Image Rectification via Cross-Page Attention Network
Jan 29, 2026Book image rectification presents unique challenges in document image processing due to complex geometric distortions from binding constraints, where left and right pages exhibit distinctly asymmetric curvature patterns. However, existing single-page document image rectification methods fail to capture the coupled geometric relationships between adjacent pages in books. In this work, we introduce BookNet, the first end-to-end deep learning framework specifically designed for dual-page book image rectification. BookNet adopts a dual-branch architecture with cross-page attention mechanisms, enabling it to estimate warping flows for both individual pages and the complete book spread, explicitly modeling how left and right pages influence each other. Moreover, to address the absence of specialized datasets, we present Book3D, a large-scale synthetic dataset for training, and Book100, a comprehensive real-world benchmark for evaluation. Extensive experiments demonstrate that BookNet outperforms existing state-of-the-art methods on book image rectification. Code and dataset will be made publicly available.
Make-It-Poseable: Feed-forward Latent Posing Model for 3D Humanoid Character Animation
Dec 18, 2025



Posing 3D characters is a fundamental task in computer graphics and vision. However, existing methods like auto-rigging and pose-conditioned generation often struggle with challenges such as inaccurate skinning weight prediction, topological imperfections, and poor pose conformance, limiting their robustness and generalizability. To overcome these limitations, we introduce Make-It-Poseable, a novel feed-forward framework that reformulates character posing as a latent-space transformation problem. Instead of deforming mesh vertices as in traditional pipelines, our method reconstructs the character in new poses by directly manipulating its latent representation. At the core of our method is a latent posing transformer that manipulates shape tokens based on skeletal motion. This process is facilitated by a dense pose representation for precise control. To ensure high-fidelity geometry and accommodate topological changes, we also introduce a latent-space supervision strategy and an adaptive completion module. Our method demonstrates superior performance in posing quality. It also naturally extends to 3D editing applications like part replacement and refinement.
Gait-Adaptive Perceptive Humanoid Locomotion with Real-Time Under-Base Terrain Reconstruction
Dec 08, 2025For full-size humanoid robots, even with recent advances in reinforcement learning-based control, achieving reliable locomotion on complex terrains, such as long staircases, remains challenging. In such settings, limited perception, ambiguous terrain cues, and insufficient adaptation of gait timing can cause even a single misplaced or mistimed step to result in rapid loss of balance. We introduce a perceptive locomotion framework that merges terrain sensing, gait regulation, and whole-body control into a single reinforcement learning policy. A downward-facing depth camera mounted under the base observes the support region around the feet, and a compact U-Net reconstructs a dense egocentric height map from each frame in real time, operating at the same frequency as the control loop. The perceptual height map, together with proprioceptive observations, is processed by a unified policy that produces joint commands and a global stepping-phase signal, allowing gait timing and whole-body posture to be adapted jointly to the commanded motion and local terrain geometry. We further adopt a single-stage successive teacher-student training scheme for efficient policy learning and knowledge transfer. Experiments conducted on a 31-DoF, 1.65 m humanoid robot demonstrate robust locomotion in both simulation and real-world settings, including forward and backward stair ascent and descent, as well as crossing a 46 cm gap. Project Page:https://ga-phl.github.io/
Enhancing the Outcome Reward-based RL Training of MLLMs with Self-Consistency Sampling
Nov 13, 2025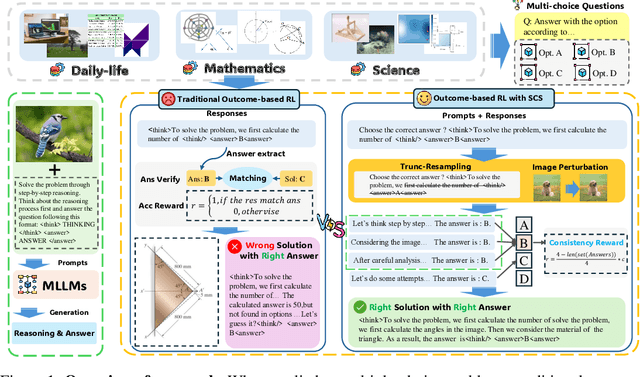
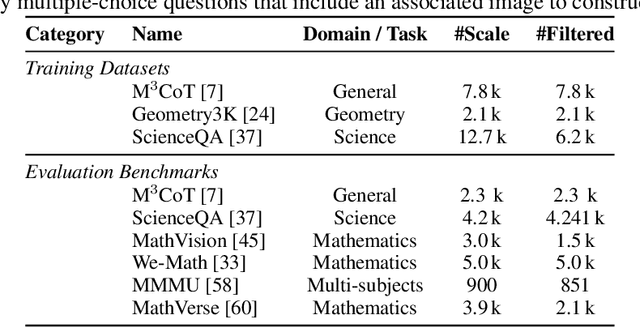
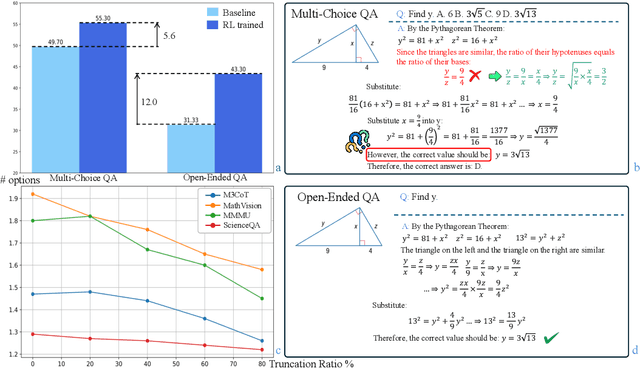
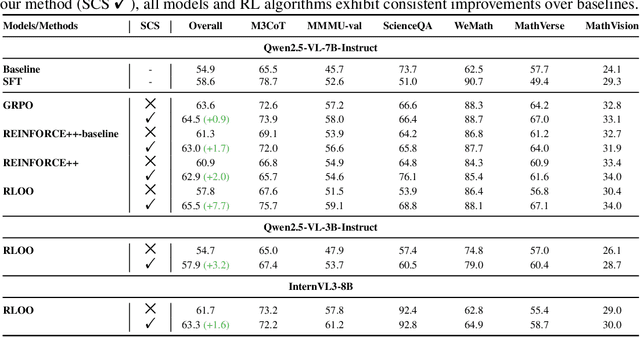
Outcome-reward reinforcement learning (RL) is a common and increasingly significant way to refine the step-by-step reasoning of multimodal large language models (MLLMs). In the multiple-choice setting - a dominant format for multimodal reasoning benchmarks - the paradigm faces a significant yet often overlooked obstacle: unfaithful trajectories that guess the correct option after a faulty chain of thought receive the same reward as genuine reasoning, which is a flaw that cannot be ignored. We propose Self-Consistency Sampling (SCS) to correct this issue. For each question, SCS (i) introduces small visual perturbations and (ii) performs repeated truncation and resampling of an initial trajectory; agreement among the resulting trajectories yields a differentiable consistency score that down-weights unreliable traces during policy updates. Based on Qwen2.5-VL-7B-Instruct, plugging SCS into RLOO, GRPO, and REINFORCE++ series improves accuracy by up to 7.7 percentage points on six multimodal benchmarks with negligible extra computation. SCS also yields notable gains on both Qwen2.5-VL-3B-Instruct and InternVL3-8B, offering a simple, general remedy for outcome-reward RL in MLLMs.
DocR1: Evidence Page-Guided GRPO for Multi-Page Document Understanding
Aug 10, 2025Understanding multi-page documents poses a significant challenge for multimodal large language models (MLLMs), as it requires fine-grained visual comprehension and multi-hop reasoning across pages. While prior work has explored reinforcement learning (RL) for enhancing advanced reasoning in MLLMs, its application to multi-page document understanding remains underexplored. In this paper, we introduce DocR1, an MLLM trained with a novel RL framework, Evidence Page-Guided GRPO (EviGRPO). EviGRPO incorporates an evidence-aware reward mechanism that promotes a coarse-to-fine reasoning strategy, guiding the model to first retrieve relevant pages before generating answers. This training paradigm enables us to build high-quality models with limited supervision. To support this, we design a two-stage annotation pipeline and a curriculum learning strategy, based on which we construct two datasets: EviBench, a high-quality training set with 4.8k examples, and ArxivFullQA, an evaluation benchmark with 8.6k QA pairs based on scientific papers. Extensive experiments across a wide range of benchmarks demonstrate that DocR1 achieves state-of-the-art performance on multi-page tasks, while consistently maintaining strong results on single-page benchmarks.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Self-Classification Enhancement and Correction for Weakly Supervised Object Detection
May 22, 2025In recent years, weakly supervised object detection (WSOD) has attracted much attention due to its low labeling cost. The success of recent WSOD models is often ascribed to the two-stage multi-class classification (MCC) task, i.e., multiple instance learning and online classification refinement. Despite achieving non-trivial progresses, these methods overlook potential classification ambiguities between these two MCC tasks and fail to leverage their unique strengths. In this work, we introduce a novel WSOD framework to ameliorate these two issues. For one thing, we propose a self-classification enhancement module that integrates intra-class binary classification (ICBC) to bridge the gap between the two distinct MCC tasks. The ICBC task enhances the network's discrimination between positive and mis-located samples in a class-wise manner and forges a mutually reinforcing relationship with the MCC task. For another, we propose a self-classification correction algorithm during inference, which combines the results of both MCC tasks to effectively reduce the mis-classified predictions. Extensive experiments on the prevalent VOC 2007 & 2012 datasets demonstrate the superior performance of our framework.
Mitigating Hallucination in VideoLLMs via Temporal-Aware Activation Engineering
May 19, 2025Multimodal large language models (MLLMs) have achieved remarkable progress in video understanding.However, hallucination, where the model generates plausible yet incorrect outputs, persists as a significant and under-addressed challenge in the video domain. Among existing solutions, activation engineering has proven successful in mitigating hallucinations in LLMs and ImageLLMs, yet its applicability to VideoLLMs remains largely unexplored. In this work, we are the first to systematically investigate the effectiveness and underlying mechanisms of activation engineering for mitigating hallucinations in VideoLLMs. We initially conduct an investigation of the key factors affecting the performance of activation engineering and find that a model's sensitivity to hallucination depends on $\textbf{temporal variation}$ rather than task type. Moreover, selecting appropriate internal modules and dataset for activation engineering is critical for reducing hallucination. Guided by these findings, we propose a temporal-aware activation engineering framework for VideoLLMs, which adaptively identifies and manipulates hallucination-sensitive modules based on the temporal variation characteristic, substantially mitigating hallucinations without additional LLM fine-tuning. Experiments across multiple models and benchmarks demonstrate that our method markedly reduces hallucination in VideoLLMs, thereby validating the robustness of our findings.
Multi-Level Aware Preference Learning: Enhancing RLHF for Complex Multi-Instruction Tasks
May 19, 2025



RLHF has emerged as a predominant approach for aligning artificial intelligence systems with human preferences, demonstrating exceptional and measurable efficacy in instruction following tasks; however, it exhibits insufficient compliance capabilities when confronted with complex multi-instruction tasks. Conventional approaches rely heavily on human annotation or more sophisticated large language models, thereby introducing substantial resource expenditure or potential bias concerns. Meanwhile, alternative synthetic methods that augment standard preference datasets often compromise the model's semantic quality. Our research identifies a critical oversight in existing techniques, which predominantly focus on comparing responses while neglecting valuable latent signals embedded within prompt inputs, and which only focus on preference disparities at the intra-sample level, while neglecting to account for the inter-sample level preference differentials that exist among preference data. To leverage these previously neglected indicators, we propose a novel Multi-level Aware Preference Learning (MAPL) framework, capable of enhancing multi-instruction capabilities. Specifically, for any given response in original preference data pairs, we construct varied prompts with a preference relation under different conditions, in order to learn intra-sample level preference disparities. Furthermore, for any given original preference pair, we synthesize multi-instruction preference pairs to capture preference discrepancies at the inter-sample level. Building on the two datasets constructed above, we consequently devise two sophisticated training objective functions. Subsequently, our framework integrates seamlessly into both Reward Modeling and Direct Preference Optimization paradigms. Through rigorous evaluation across multiple benchmarks, we empirically validate the efficacy of our framework.
Bias Fitting to Mitigate Length Bias of Reward Model in RLHF
May 19, 2025



Reinforcement Learning from Human Feedback relies on reward models to align large language models with human preferences. However, RLHF often suffers from reward hacking, wherein policy learning exploits flaws in the trained reward model to maximize reward scores without genuinely aligning with human preferences. A significant example of such reward hacking is length bias, where reward models usually favor longer responses irrespective of actual response quality. Previous works on length bias have notable limitations, these approaches either mitigate bias without characterizing the bias form, or simply assume a linear length-reward relation. To accurately model the intricate nature of length bias and facilitate more effective bias mitigation, we propose FiMi-RM (Bias Fitting to Mitigate Length Bias of Reward Model in RLHF), a framework that autonomously learns and corrects underlying bias patterns. Our approach consists of three stages: First, we train a standard reward model which inherently contains length bias. Next, we deploy a lightweight fitting model to explicitly capture the non-linear relation between length and reward. Finally, we incorporate this learned relation into the reward model to debias. Experimental results demonstrate that FiMi-RM achieves a more balanced length-reward distribution. Furthermore, when applied to alignment algorithms, our debiased reward model improves length-controlled win rate and reduces verbosity without compromising its performance.