 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryoCCD: Conditional Cycle-consistent Diffusion with Biophysical Modeling for Cryo-EM Synthesis
May 29, 2025Cryo-electron microscopy (cryo-EM) offers near-atomic resolution imaging of macromolecules, but developing robust models for downstream analysis is hindered by the scarcity of high-quality annotated data. While synthetic data generation has emerged as a potential solution, existing methods often fail to capture both the structural diversity of biological specimens and the complex, spatially varying noise inherent in cryo-EM imaging. To overcome these limitations, we propose CryoCCD, a synthesis framework that integrates biophysical modeling with generative techniques. Specifically, CryoCCD produces multi-scale cryo-EM micrographs that reflect realistic biophysical variability through compositional heterogeneity, cellular context, and physics-informed imaging. To generate realistic noise, we employ a conditional diffusion model, enhanced by cycle consistency to preserve structural fidelity and mask-aware contrastive learning to capture spatially adaptive noise patterns. Extensive experiments show that CryoCCD generates structurally accurate micrographs and enhances performance in downstream tasks, outperforming state-of-the-art baselines in both particle picking and reconstruction.
Preliminary Explorations with GPT-4o(mni) Native Image Generation
May 06, 2025



Recently, the visual generation ability by GPT-4o(mni) has been unlocked by OpenAI. It demonstrates a very remarkable generation capability with excellent multimodal condition understanding and varied task instructions. In this paper, we aim to explore the capabilities of GPT-4o across various tasks. Inspired by previous study, we constructed a task taxonomy along with a carefully curated set of test samples to conduct a comprehensive qualitative test. Benefiting from GPT-4o's powerful multimodal comprehension, its image-generation process demonstrates abilities surpassing those of traditional image-generation tasks. Thus, regarding the dimensions of model capabilities, we evaluate its performance across six task categories: traditional image generation tasks, discriminative tasks, knowledge-based generation, commonsense-based generation, spatially-aware image generation, and temporally-aware image generation. These tasks not only assess the quality and conditional alignment of the model's outputs but also probe deeper into GPT-4o's understanding of real-world concepts. Our results reveal that GPT-4o performs impressively well in general-purpose synthesis tasks, showing strong capabilities in text-to-image generation, visual stylization, and low-level image processing. However, significant limitations remain in its ability to perform precise spatial reasoning, instruction-grounded generation, and consistent temporal prediction. Furthermore, when faced with knowledge-intensive or domain-specific scenarios, such as scientific illustrations or mathematical plots, the model often exhibits hallucinations, factual errors, or structural inconsistencies. These findings suggest that while GPT-4o marks a substantial advancement in unified multimodal generation, there is still a long way to go before it can be reliably applied to professional or safety-critical domains.
Multi-Scale Invertible Neural Network for Wide-Range Variable-Rate Learned Image Compression
Mar 27, 2025



Autoencoder-based structures have dominated recent learned image compression methods. However, the inherent information loss associated with autoencoders limits their rate-distortion performance at high bit rates and restricts their flexibility of rate adaptation. In this paper, we present a variable-rate image compression model based on invertible transform to overcome these limitations. Specifically, we design a lightweight multi-scale invertible neural network, which bijectively maps the input image into multi-scale latent representations. To improve the compression efficiency, a multi-scale spatial-channel context model with extended gain units is devised to estimate the entropy of the latent representation from high to low levels. Experimental results demonstrate that the proposed method achieves state-of-the-art performance compared to existing variable-rate methods, and remains competitive with recent multi-model approaches. Notably, our method is the first learned image compression solution that outperforms VVC across a very wide range of bit rates using a single model, especially at high bit rates.The source code is available at \href{https://github.com/hytu99/MSINN-VRLIC}{https://github.com/hytu99/MSINN-VRLIC}.
Conceptual Codebook Learning for Vision-Language Models
Jul 02, 2024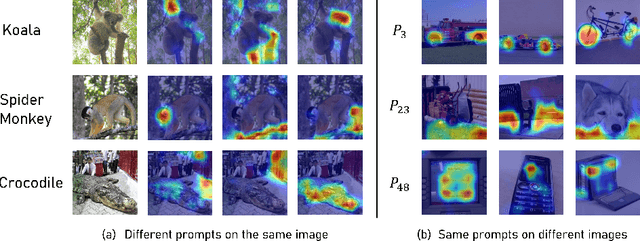
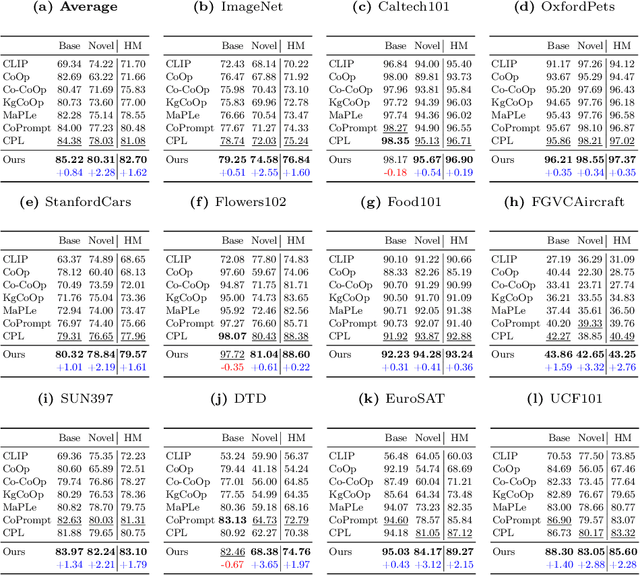
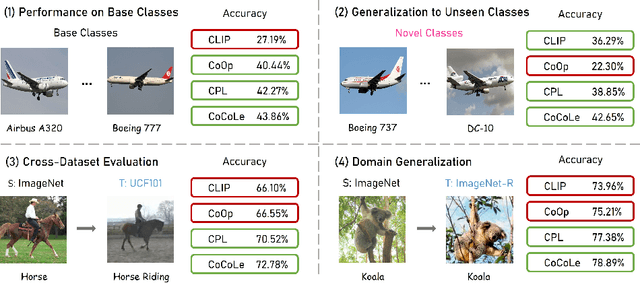
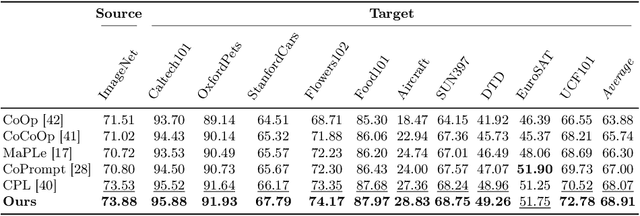
In this paper, we propose Conceptual Codebook Learning (CoCoLe), a novel fine-tuning method for vision-language models (VLMs) to address the challenge of improving the generalization capability of VLMs while fine-tuning them on downstream tasks in a few-shot setting. We recognize that visual concepts, such as textures, shapes, and colors are naturally transferable across domains and play a crucial role in generalization tasks. Motivated by this interesting finding, we learn a conceptual codebook consisting of visual concepts as keys and conceptual prompts as values, which serves as a link between the image encoder's outputs and the text encoder's inputs. Specifically, for a given image, we leverage the codebook to identify the most relevant conceptual prompts associated with the class embeddings to perform the classification. Additionally, we incorporate a handcrafted concept cache as a regularization to alleviate the overfitting issues in low-shot scenarios. We observe that this conceptual codebook learning method is able to achieve enhanced alignment between visual and linguistic modalities. Extensive experimental results demonstrate that our CoCoLe method remarkably outperforms the existing state-of-the-art methods across various evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization tasks. Detailed ablation studies further confirm the efficacy of each component in CoCoLe.
HiGraphDTI: Hierarchical Graph Representation Learning for Drug-Target Interaction Prediction
Apr 16, 2024The discovery of drug-target interactions (DTIs) plays a crucial role in pharmaceutical development. The deep learning model achieves more accurate results in DTI prediction due to its ability to extract robust and expressive features from drug and target chemical structures. However, existing deep learning methods typically generate drug features via aggregating molecular atom representations, ignoring the chemical properties carried by motifs, i.e., substructures of the molecular graph. The atom-drug double-level molecular representation learning can not fully exploit structure information and fails to interpret the DTI mechanism from the motif perspective. In addition, sequential model-based target feature extraction either fuses limited contextual information or requires expensive computational resources. To tackle the above issues, we propose a hierarchical graph representation learning-based DTI prediction method (HiGraphDTI). Specifically, HiGraphDTI learns hierarchical drug representations from triple-level molecular graphs to thoroughly exploit chemical information embedded in atoms, motifs, and molecules. Then, an attentional feature fusion module incorporates information from different receptive fields to extract expressive target features.Last, the hierarchical attention mechanism identifies crucial molecular segments, which offers complementary views for interpreting interaction mechanisms. The experiment results not only demonstrate the superiority of HiGraphDTI to the state-of-the-art methods, but also confirm the practical ability of our model in interaction interpretation and new DTI discovery.
How We Define Harm Impacts Data Annotations: Explaining How Annotators Distinguish Hateful, Offensive, and Toxic Comments
Sep 12, 2023



Computational social science research has made advances in machine learning and natural language processing that support content moderators in detecting harmful content. These advances often rely on training datasets annotated by crowdworkers for harmful content. In designing instructions for annotation tasks to generate training data for these algorithms, researchers often treat the harm concepts that we train algorithms to detect - 'hateful', 'offensive', 'toxic', 'racist', 'sexist', etc. - as interchangeable. In this work, we studied whether the way that researchers define 'harm' affects annotation outcomes. Using Venn diagrams, information gain comparisons, and content analyses, we reveal that annotators do not use the concepts 'hateful', 'offensive', and 'toxic' interchangeably. We identify that features of harm definitions and annotators' individual characteristics explain much of how annotators use these terms differently. Our results offer empirical evidence discouraging the common practice of using harm concepts interchangeably in content moderation research. Instead, researchers should make specific choices about which harm concepts to analyze based on their research goals. Recognizing that researchers are often resource constrained, we also encourage researchers to provide information to bound their findings when their concepts of interest differ from concepts that off-the-shelf harmful content detection algorithms identify. Finally, we encourage algorithm providers to ensure their instruments can adapt to contextually-specific content detection goals (e.g., soliciting instrument users' feedback).
AttentionFlow: Visualising Influence in Networks of Time Series
Feb 03, 2021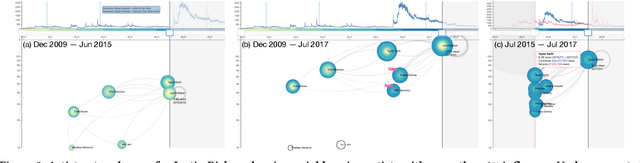
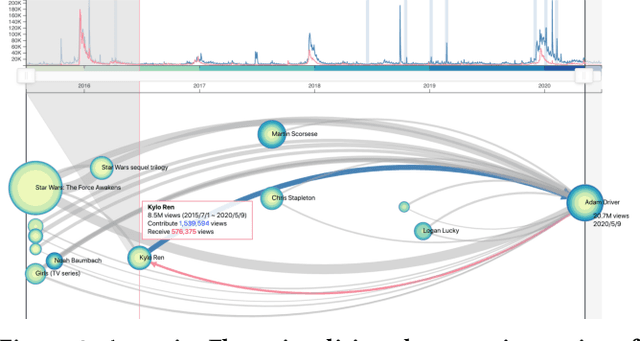
The collective attention on online items such as web pages, search terms, and videos reflects trends that are of social, cultural, and economic interest. Moreover, attention trends of different items exhibit mutual influence via mechanisms such as hyperlinks or recommendations. Many visualisation tools exist for time series, network evolution, or network influence; however, few systems connect all three. In this work, we present AttentionFlow, a new system to visualise networks of time series and the dynamic influence they have on one another. Centred around an ego node, our system simultaneously presents the time series on each node using two visual encodings: a tree ring for an overview and a line chart for details. AttentionFlow supports interactions such as overlaying time series of influence and filtering neighbours by time or flux. We demonstrate AttentionFlow using two real-world datasets, VevoMusic and WikiTraffic. We show that attention spikes in songs can be explained by external events such as major awards, or changes in the network such as the release of a new song. Separate case studies also demonstrate how an artist's influence changes over their career, and that correlated Wikipedia traffic is driven by cultural interests. More broadly, AttentionFlow can be generalised to visualise networks of time series on physical infrastructures such as road networks, or natural phenomena such as weather and geological measurements.
* Published in WSDM 2021. The demo is available at https://attentionflow.ml and code is available at https://github.com/alasdairtran/attentionflow
Unique Sharp Local Minimum in $\ell_1$-minimization Complete Dictionary Learning
Feb 22, 2019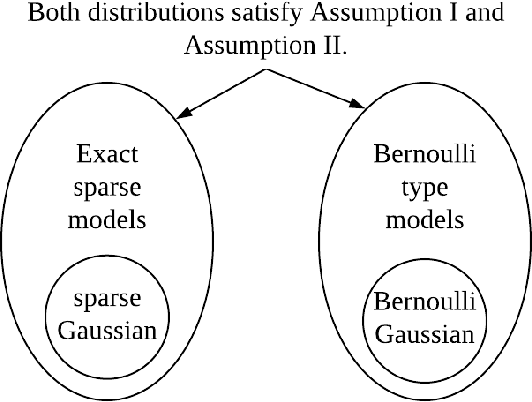
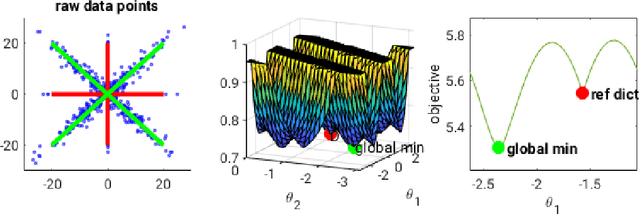
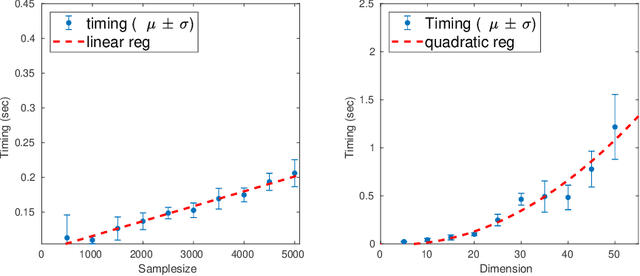
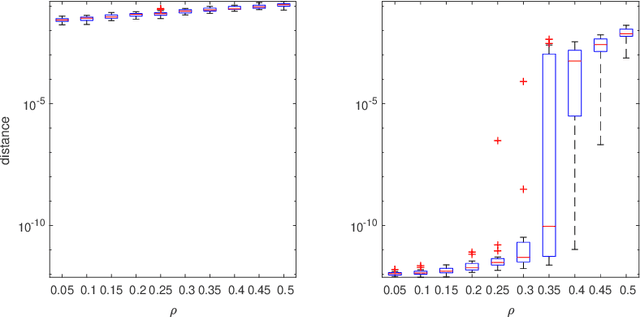
We study the problem of globally recovering a dictionary from a set of signals via $\ell_1$-minimization. We assume that the signals are generated as i.i.d. random linear combinations of the $K$ atoms from a complete reference dictionary $D^*\in \mathbb R^{K\times K}$, where the linear combination coefficients are from either a Bernoulli type model or exact sparse model. First, we obtain a necessary and sufficient norm condition for the reference dictionary $D^*$ to be a sharp local minimum of the expected $\ell_1$ objective function. Our result substantially extends that of Wu and Yu (2015) and allows the combination coefficient to be non-negative. Secondly, we obtain an explicit bound on the region within which the objective value of the reference dictionary is minimal. Thirdly, we show that the reference dictionary is the unique sharp local minimum, thus establishing the first known global property of $\ell_1$-minimization dictionary learning. Motivated by the theoretical results, we introduce a perturbation-based test to determine whether a dictionary is a sharp local minimum of the objective function. In addition, we also propose a new dictionary learning algorithm based on Block Coordinate Descent, called DL-BCD, which is guaranteed to have monotonic convergence. Simulation studies show that DL-BCD has competitive performance in terms of recovery rate compared to many state-of-the-art dictionary learning algorithms.
Local identifiability of $l_1$-minimization dictionary learning: a sufficient and almost necessary condition
Jul 12, 2016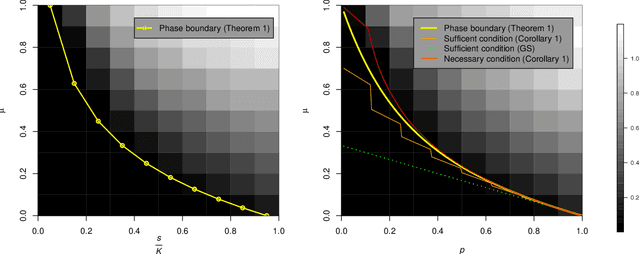
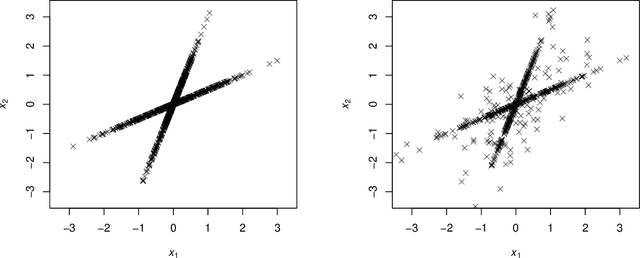
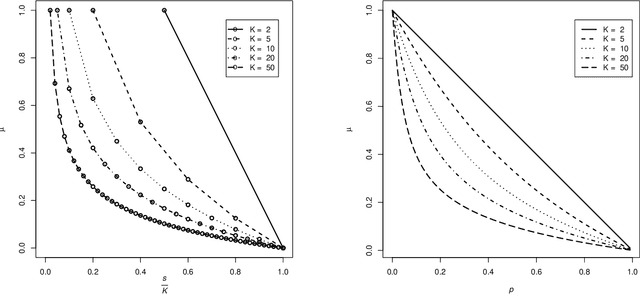
We study the theoretical properties of learning a dictionary from $N$ signals $\mathbf x_i\in \mathbb R^K$ for $i=1,...,N$ via $l_1$-minimization. We assume that $\mathbf x_i$'s are $i.i.d.$ random linear combinations of the $K$ columns from a complete (i.e., square and invertible) reference dictionary $\mathbf D_0 \in \mathbb R^{K\times K}$. Here, the random linear coefficients are generated from either the $s$-sparse Gaussian model or the Bernoulli-Gaussian model. First, for the population case, we establish a sufficient and almost necessary condition for the reference dictionary $\mathbf D_0$ to be locally identifiable, i.e., a local minimum of the expected $l_1$-norm objective function. Our condition covers both sparse and dense cases of the random linear coefficients and significantly improves the sufficient condition by Gribonval and Schnass (2010). In addition, we show that for a complete $\mu$-coherent reference dictionary, i.e., a dictionary with absolute pairwise column inner-product at most $\mu\in[0,1)$, local identifiability holds even when the random linear coefficient vector has up to $O(\mu^{-2})$ nonzeros on average. Moreover, our local identifiability results also translate to the finite sample case with high probability provided that the number of signals $N$ scales as $O(K\log K)$.