 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliGS: Holistic Gaussian Splatting for Embodied View Synthesis
Jun 24, 2025We propose HoliGS, a novel deformable Gaussian splatting framework that addresses embodied view synthesis from long monocular RGB videos. Unlike prior 4D Gaussian splatting and dynamic NeRF pipelines, which struggle with training overhead in minute-long captures, our method leverages invertible Gaussian Splatting deformation networks to reconstruct large-scale, dynamic environments accurately. Specifically, we decompose each scene into a static background plus time-varying objects, each represented by learned Gaussian primitives undergoing global rigid transformations, skeleton-driven articulation, and subtle non-rigid deformations via an invertible neural flow. This hierarchical warping strategy enables robust free-viewpoint novel-view rendering from various embodied camera trajectories by attaching Gaussians to a complete canonical foreground shape (\eg, egocentric or third-person follow), which may involve substantial viewpoint changes and interactions between multiple actors. Our experiments demonstrate that \ourmethod~ achieves superior reconstruction quality on challenging datasets while significantly reducing both training and rendering time compared to state-of-the-art monocular deformable NeRFs. These results highlight a practical and scalable solution for EVS in real-world scenarios. The source code will be released.
CryoCCD: Conditional Cycle-consistent Diffusion with Biophysical Modeling for Cryo-EM Synthesis
May 29, 2025Cryo-electron microscopy (cryo-EM) offers near-atomic resolution imaging of macromolecules, but developing robust models for downstream analysis is hindered by the scarcity of high-quality annotated data. While synthetic data generation has emerged as a potential solution, existing methods often fail to capture both the structural diversity of biological specimens and the complex, spatially varying noise inherent in cryo-EM imaging. To overcome these limitations, we propose CryoCCD, a synthesis framework that integrates biophysical modeling with generative techniques. Specifically, CryoCCD produces multi-scale cryo-EM micrographs that reflect realistic biophysical variability through compositional heterogeneity, cellular context, and physics-informed imaging. To generate realistic noise, we employ a conditional diffusion model, enhanced by cycle consistency to preserve structural fidelity and mask-aware contrastive learning to capture spatially adaptive noise patterns. Extensive experiments show that CryoCCD generates structurally accurate micrographs and enhances performance in downstream tasks, outperforming state-of-the-art baselines in both particle picking and reconstruction.
Total-Editing: Head Avatar with Editable Appearance, Motion, and Lighting
May 26, 2025Face reenactment and portrait relighting are essential tasks in portrait editing, yet they are typically addressed independently, without much synergy. Most face reenactment methods prioritize motion control and multiview consistency, while portrait relighting focuses on adjusting shading effects. To take advantage of both geometric consistency and illumination awareness, we introduce Total-Editing, a unified portrait editing framework that enables precise control over appearance, motion, and lighting. Specifically, we design a neural radiance field decoder with intrinsic decomposition capabilities. This allows seamless integration of lighting information from portrait images or HDR environment maps into synthesized portraits. We also incorporate a moving least squares based deformation field to enhance the spatiotemporal coherence of avatar motion and shading effects. With these innovations, our unified framework significantly improves the quality and realism of portrait editing results. Further, the multi-source nature of Total-Editing supports more flexible applications, such as illumination transfer from one portrait to another, or portrait animation with customized backgrounds.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
Quantifying Preferences of Vision-Language Models via Value Decomposition in Social Media Contexts
Nov 18, 2024The rapid advancement of Vision-Language Models (VLMs) has expanded multimodal applications, yet evaluations often focus on basic tasks like object recognition, overlooking abstract aspects such as personalities and values. To address this gap, we introduce Value-Spectrum, a visual question-answering benchmark aimed at assessing VLMs based on Schwartz's value dimensions, which capture core values guiding people's beliefs and actions across cultures. We constructed a vectorized database of over 50,000 short videos sourced from TikTok, YouTube Shorts, and Instagram Reels, covering multiple months and a wide array of topics such as family, health, hobbies, society, and technology. We also developed a VLM agent pipeline to automate video browsing and analysis. Benchmarking representative VLMs on Value-Spectrum reveals significant differences in their responses to value-oriented content, with most models exhibiting a preference for hedonistic topics. Beyond identifying natural preferences, we explored the ability of VLM agents to adopt specific personas when explicitly prompted, revealing insights into the models' adaptability in role-playing scenarios. These findings highlight the potential of Value-Spectrum as a comprehensive evaluation set for tracking VLM advancements in value-based tasks and for developing more sophisticated role-playing AI agents.
Training-free CryoET Tomogram Segmentation
Jul 08, 2024



Cryogenic Electron Tomography (CryoET) is a useful imaging technology in structural biology that is hindered by its need for manual annotations, especially in particle picking. Recent works have endeavored to remedy this issue with few-shot learning or contrastive learning techniques. However, supervised training is still inevitable for them. We instead choose to leverage the power of existing 2D foundation models and present a novel, training-free framework, CryoSAM. In addition to prompt-based single-particle instance segmentation, our approach can automatically search for similar features, facilitating full tomogram semantic segmentation with only one prompt. CryoSAM is composed of two major parts: 1) a prompt-based 3D segmentation system that uses prompts to complete single-particle instance segmentation recursively with Cross-Plane Self-Prompting, and 2) a Hierarchical Feature Matching mechanism that efficiently matches relevant features with extracted tomogram features. They collaborate to enable the segmentation of all particles of one category with just one particle-specific prompt. Our experiments show that CryoSAM outperforms existing works by a significant margin and requires even fewer annotations in particle picking. Further visualizations demonstrate its ability when dealing with full tomogram segmentation for various subcellular structures. Our code is available at: https://github.com/xulabs/aitom
Synergistic Global-space Camera and Human Reconstruction from Videos
May 23, 2024



Remarkable strides have been made in reconstructing static scenes or human bodies from monocular videos. Yet, the two problems have largely been approached independently, without much synergy. Most visual SLAM methods can only reconstruct camera trajectories and scene structures up to scale, while most HMR methods reconstruct human meshes in metric scale but fall short in reasoning with cameras and scenes. This work introduces Synergistic Camera and Human Reconstruction (SynCHMR) to marry the best of both worlds. Specifically, we design Human-aware Metric SLAM to reconstruct metric-scale camera poses and scene point clouds using camera-frame HMR as a strong prior, addressing depth, scale, and dynamic ambiguities. Conditioning on the dense scene recovered, we further learn a Scene-aware SMPL Denoiser to enhance world-frame HMR by incorporating spatio-temporal coherency and dynamic scene constraints. Together, they lead to consistent reconstructions of camera trajectories, human meshes, and dense scene point clouds in a common world frame. Project page: https://paulchhuang.github.io/synchmr
Point Resampling and Ray Transformation Aid to Editable NeRF Models
May 12, 2024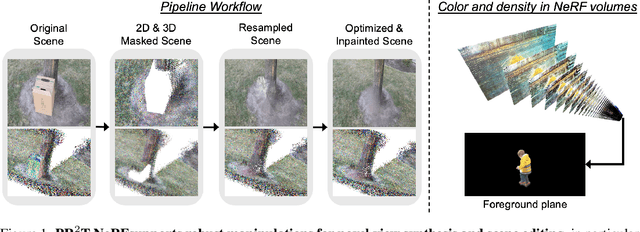

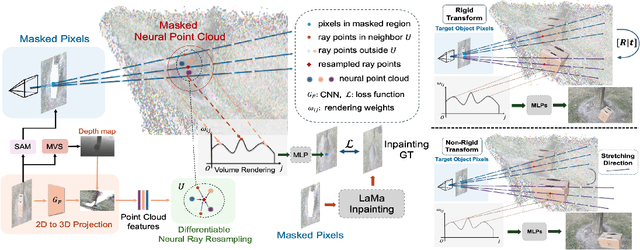

In NeRF-aided editing tasks, object movement presents difficulties in supervision generation due to the introduction of variability in object positions. Moreover, the removal operations of certain scene objects often lead to empty regions, presenting challenges for NeRF models in inpainting them effectively. We propose an implicit ray transformation strategy, allowing for direct manipulation of the 3D object's pose by operating on the neural-point in NeRF rays. To address the challenge of inpainting potential empty regions, we present a plug-and-play inpainting module, dubbed differentiable neural-point resampling (DNR), which interpolates those regions in 3D space at the original ray locations within the implicit space, thereby facilitating object removal & scene inpainting tasks. Importantly, employing DNR effectively narrows the gap between ground truth and predicted implicit features, potentially increasing the mutual information (MI) of the features across rays. Then, we leverage DNR and ray transformation to construct a point-based editable NeRF pipeline PR^2T-NeRF. Results primarily evaluated on 3D object removal & inpainting tasks indicate that our pipeline achieves state-of-the-art performance. In addition, our pipeline supports high-quality rendering visualization for diverse editing operations without necessitating extra supervision.
Triple Regression for Camera Agnostic Sim2Real Robot Grasping and Manipulation Tasks
Sep 16, 2023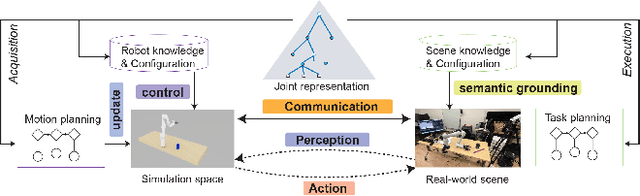
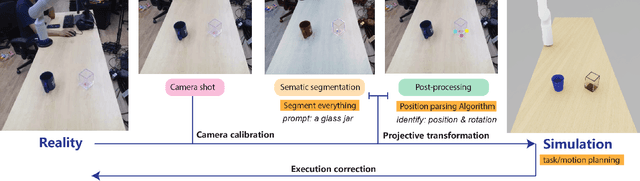

Sim2Real (Simulation to Reality) techniques have gained prominence in robotic manipulation and motion planning due to their ability to enhance success rates by enabling agents to test and evaluate various policies and trajectories. In this paper, we investigate the advantages of integrating Sim2Real into robotic frameworks. We introduce the Triple Regression Sim2Real framework, which constructs a real-time digital twin. This twin serves as a replica of reality to simulate and evaluate multiple plans before their execution in real-world scenarios. Our triple regression approach addresses the reality gap by: (1) mitigating projection errors between real and simulated camera perspectives through the first two regression models, and (2) detecting discrepancies in robot control using the third regression model. Experiments on 6-DoF grasp and manipulation tasks (where the gripper can approach from any direction) highlight the effectiveness of our framework. Remarkably, with only RGB input images, our method achieves state-of-the-art success rates. This research advances efficient robot training methods and sets the stage for rapid advancements in robotics and automation.
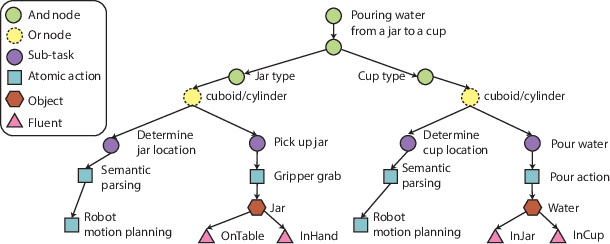
Sim2Plan: Robot Motion Planning via Message Passing between Simulation and Reality
Jul 15, 2023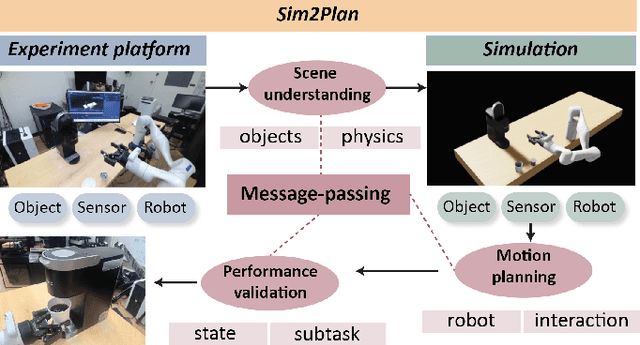
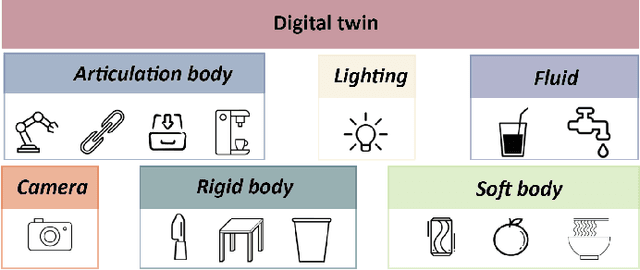

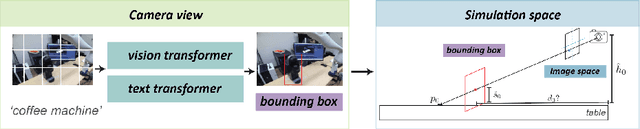
Simulation-to-real is the task of training and developing machine learning models and deploying them in real settings with minimal additional training. This approach is becoming increasingly popular in fields such as robotics. However, there is often a gap between the simulated environment and the real world, and machine learning models trained in simulation may not perform as well in the real world. We propose a framework that utilizes a message-passing pipeline to minimize the information gap between simulation and reality. The message-passing pipeline is comprised of three modules: scene understanding, robot planning, and performance validation. First, the scene understanding module aims to match the scene layout between the real environment set-up and its digital twin. Then, the robot planning module solves a robotic task through trial and error in the simulation. Finally, the performance validation module varies the planning results by constantly checking the status difference of the robot and object status between the real set-up and the simulation. In the experiment, we perform a case study that requires a robot to make a cup of coffee. Results show that the robot is able to complete the task under our framework successfully. The robot follows the steps programmed into its system and utilizes its actuators to interact with the coffee machine and other tools required for the task. The results of this case study demonstrate the potential benefits of our method that drive robots for tasks that require precision and efficiency. Further research in this area could lead to the development of even more versatile and adaptable robots, opening up new possibilities for automation in various industries.