 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatternGSL: A Structured Specification Language for Template-Free and Simulation-Ready 3D Garments
Jun 24, 2026Reconstructing realistic, physically plausible garments from a single image remains a fundamental challenge. Template-free methods capture surface geometry but lack explicit sewing structure for simulation; while programmatic systems are simulation-ready but constrained by predefined templates. This reveals a fundamental representation gap between geometric reconstruction and structured garment construction. We present PatternGSL, a structured garment representation in the form of a template-free and learnable specification language that encodes complete sewing patterns, including panel boundaries, parameterized seams, and explicit stitch topology, in a compact and standardized form. PatternGSL preserves the physical rigor of pattern-based models while removing template dependence, elevating sewing structure as a first-class target for generative modeling. We further propose a vision-language framework that predicts PatternGSL specifications directly from a single image and decodes them into garments using lightweight deterministic validity handling, without optimization-based refinement or manual cleanup. In addition, we introduce PatternGSLData, the first large-scale image-to-GSL paired dataset comprising 300K samples with complete sewing pattern annotations, enabling supervised VLM training for structured garment reconstruction. Experiments demonstrate improved pattern accuracy over prior baselines, explicit sewing-structure recovery, reliable cloth simulation, and pattern-level editing through the same deterministic decoding pipeline. Code and data-processing scripts will be released at https://github.com/PatternGSL/PatternGSL.
StainFlow: Entity-Stain Tracking and Evidence Linking for Process Rewards in GUI Agents
Jun 05, 2026Reinforcement Learning (RL) has become a promising approach for improving GUI Agents in long-horizon, stochastic digital environments, but trajectory-level success feedback is too sparse to provide reliable credit assignment for intermediate exploration steps. To mitigate this issue, recent studies introduce Process Reward Models (PRMs), which provide finer-grained training feedback through global milestone verification or local step-level evaluation. However, these methods still suffer from two level-specific limitations: global milestone decomposition is subjective and singular, making it difficult to accommodate the multiple valid execution paths in real GUI tasks, while fixed local judging windows may miss long-range key evidence or dilute the decision signal with irrelevant frames. Inspired by stain-tracing mechanisms in network flow analysis, we propose StainFlow, an entity-stain-flow process reward model for GUI Agents. To reduce the subjectivity of global partitioning, we introduce the Global Entity Stain Tracking module, which extracts visually verifiable task entities and tracks how their stain concentrations and states evolve along the trajectory, allowing task phases to be objectively separated by changes in the entity evidence flow. To improve the accuracy of local verification, we introduce the Local Stain Evidence Linking module. Centered on the triggering entities of each candidate key node, it retrieves relevant steps based on their stain concentrations and state changes, and dynamically constructs high-density evidence windows for verifying true key nodes. Extensive experiments on AndroidWorld and OGRBench show that StainFlow relatively improves online RL success by 3.2% and trajectory completion judgment accuracy by 1.8%.
ConsistNav: Closing the Action Consistency Gap in Zero-Shot Object Navigation with Semantic Executive Control
May 11, 2026Zero-shot object navigation has advanced rapidly with open-vocabulary detectors, image--text models, and language-guided exploration. However, even after current methods detect a plausible target hypothesis, the agent may still oscillate between exploration and pursuit, or abandon the object near success. We identify this failure mode as an action consistency gap: semantic evidence is repeatedly reinterpreted at each step without persistent commitment across the episode. We introduce ConsistNav, a training-free zero-shot ObjectNav framework built around a semantic executive composed of three coordinated modules: Finite-State Executive Controller stages target pursuit through guarded semantic phases; Persistent Candidate Memory accumulates cross-frame target evidence into stable object hypotheses; and Stability-Aware Action Control suppresses rotational stagnation, ineffective pursuit, and unverified stopping. This design changes neither the detector nor the low-level planner; instead, it controls when semantic evidence should influence navigation and when it should be suppressed or revisited. We conduct extensive experiments on HM3D and MP3D, where ConsistNav achieves state-of-the-art results among compared zero-shot ObjectNav methods and improves SR by 11.4% and SPL by 7.9% over the controlled baseline on MP3D. Ablation studies and real-world deployment experiments further demonstrate the effectiveness and robustness of the proposed executive mechanism.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
ES-Mem: Event Segmentation-Based Memory for Long-Term Dialogue Agents
Jan 13, 2026Memory is critical for dialogue agents to maintain coherence and enable continuous adaptation in long-term interactions. While existing memory mechanisms offer basic storage and retrieval capabilities, they are hindered by two primary limitations: (1) rigid memory granularity often disrupts semantic integrity, resulting in fragmented and incoherent memory units; (2) prevalent flat retrieval paradigms rely solely on surface-level semantic similarity, neglecting the structural cues of discourse required to navigate and locate specific episodic contexts. To mitigate these limitations, drawing inspiration from Event Segmentation Theory, we propose ES-Mem, a framework incorporating two core components: (1) a dynamic event segmentation module that partitions long-term interactions into semantically coherent events with distinct boundaries; (2) a hierarchical memory architecture that constructs multi-layered memories and leverages boundary semantics to anchor specific episodic memory for precise context localization. Evaluations on two memory benchmarks demonstrate that ES-Mem yields consistent performance gains over baseline methods. Furthermore, the proposed event segmentation module exhibits robust applicability on dialogue segmentation datasets.
DiffER: Diffusion Entity-Relation Modeling for Reversal Curse in Diffusion Large Language Models
Jan 12, 2026The "reversal curse" refers to the phenomenon where large language models (LLMs) exhibit predominantly unidirectional behavior when processing logically bidirectional relationships. Prior work attributed this to autoregressive training -- predicting the next token inherently favors left-to-right information flow over genuine bidirectional knowledge associations. However, we observe that Diffusion LLMs (DLLMs), despite being trained bidirectionally, also suffer from the reversal curse. To investigate the root causes, we conduct systematic experiments on DLLMs and identify three key reasons: 1) entity fragmentation during training, 2) data asymmetry, and 3) missing entity relations. Motivated by the analysis of these reasons, we propose Diffusion Entity-Relation Modeling (DiffER), which addresses the reversal curse through entity-aware training and balanced data construction. Specifically, DiffER introduces whole-entity masking, which mitigates entity fragmentation by predicting complete entities in a single step. DiffER further employs distribution-symmetric and relation-enhanced data construction strategies to alleviate data asymmetry and missing relations. Extensive experiments demonstrate that DiffER effectively alleviates the reversal curse in Diffusion LLMs, offering new perspectives for future research.
DiffuGR: Generative Document Retrieval with Diffusion Language Models
Nov 19, 2025Generative retrieval (GR) re-frames document retrieval as a sequence-based document identifier (DocID) generation task, memorizing documents with model parameters and enabling end-to-end retrieval without explicit indexing. Existing GR methods are based on auto-regressive generative models, i.e., the token generation is performed from left to right. However, such auto-regressive methods suffer from: (1) mismatch between DocID generation and natural language generation, e.g., an incorrect DocID token generated in early left steps would lead to totally erroneous retrieval; and (2) failure to balance the trade-off between retrieval efficiency and accuracy dynamically, which is crucial for practical applications. To address these limitations, we propose generative document retrieval with diffusion language models, dubbed DiffuGR. It models DocID generation as a discrete diffusion process: during training, DocIDs are corrupted through a stochastic masking process, and a diffusion language model is learned to recover them under a retrieval-aware objective. For inference, DiffuGR attempts to generate DocID tokens in parallel and refines them through a controllable number of denoising steps. In contrast to conventional left-to-right auto-regressive decoding, DiffuGR provides a novel mechanism to first generate more confident DocID tokens and refine the generation through diffusion-based denoising. Moreover, DiffuGR also offers explicit runtime control over the qualitylatency tradeoff. Extensive experiments on benchmark retrieval datasets show that DiffuGR is competitive with strong auto-regressive generative retrievers, while offering flexible speed and accuracy tradeoffs through variable denoising budgets. Overall, our results indicate that non-autoregressive diffusion models are a practical and effective alternative for generative document retrieval.
EventTracer: Fast Path Tracing-based Event Stream Rendering
Aug 25, 2025

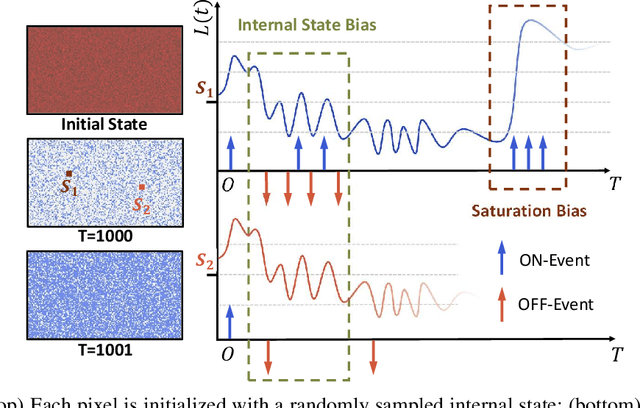
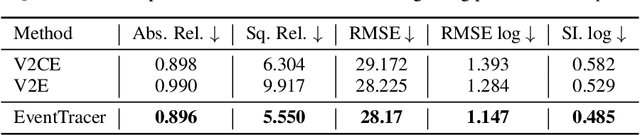
Simulating event streams from 3D scenes has become a common practice in event-based vision research, as it meets the demand for large-scale, high temporal frequency data without setting up expensive hardware devices or undertaking extensive data collections. Yet existing methods in this direction typically work with noiseless RGB frames that are costly to render, and therefore they can only achieve a temporal resolution equivalent to 100-300 FPS, far lower than that of real-world event data. In this work, we propose EventTracer, a path tracing-based rendering pipeline that simulates high-fidelity event sequences from complex 3D scenes in an efficient and physics-aware manner. Specifically, we speed up the rendering process via low sample-per-pixel (SPP) path tracing, and train a lightweight event spiking network to denoise the resulting RGB videos into realistic event sequences. To capture the physical properties of event streams, the network is equipped with a bipolar leaky integrate-and-fired (BiLIF) spiking unit and trained with a bidirectional earth mover distance (EMD) loss. Our EventTracer pipeline runs at a speed of about 4 minutes per second of 720p video, and it inherits the merit of accurate spatiotemporal modeling from its path tracing backbone. We show in two downstream tasks that EventTracer captures better scene details and demonstrates a greater similarity to real-world event data than other event simulators, which establishes it as a promising tool for creating large-scale event-RGB datasets at a low cost, narrowing the sim-to-real gap in event-based vision, and boosting various application scenarios such as robotics, autonomous driving, and VRAR.
Enhanced Velocity Field Modeling for Gaussian Video Reconstruction
Jul 31, 2025High-fidelity 3D video reconstruction is essential for enabling real-time rendering of dynamic scenes with realistic motion in virtual and augmented reality (VR/AR). The deformation field paradigm of 3D Gaussian splatting has achieved near-photorealistic results in video reconstruction due to the great representation capability of deep deformation networks. However, in videos with complex motion and significant scale variations, deformation networks often overfit to irregular Gaussian trajectories, leading to suboptimal visual quality. Moreover, the gradient-based densification strategy designed for static scene reconstruction proves inadequate to address the absence of dynamic content. In light of these challenges, we propose a flow-empowered velocity field modeling scheme tailored for Gaussian video reconstruction, dubbed FlowGaussian-VR. It consists of two core components: a velocity field rendering (VFR) pipeline which enables optical flow-based optimization, and a flow-assisted adaptive densification (FAD) strategy that adjusts the number and size of Gaussians in dynamic regions. We validate our model's effectiveness on multi-view dynamic reconstruction and novel view synthesis with multiple real-world datasets containing challenging motion scenarios, demonstrating not only notable visual improvements (over 2.5 dB gain in PSNR) and less blurry artifacts in dynamic textures, but also regularized and trackable per-Gaussian trajectories.
Joint Flashback Adaptation for Forgetting-Resistant Instruction Tuning
May 21, 2025Large language models have achieved remarkable success in various tasks. However, it is challenging for them to learn new tasks incrementally due to catastrophic forgetting. Existing approaches rely on experience replay, optimization constraints, or task differentiation, which encounter strict limitations in real-world scenarios. To address these issues, we propose Joint Flashback Adaptation. We first introduce flashbacks -- a limited number of prompts from old tasks -- when adapting to new tasks and constrain the deviations of the model outputs compared to the original one. We then interpolate latent tasks between flashbacks and new tasks to enable jointly learning relevant latent tasks, new tasks, and flashbacks, alleviating data sparsity in flashbacks and facilitating knowledge sharing for smooth adaptation. Our method requires only a limited number of flashbacks without access to the replay data and is task-agnostic. We conduct extensive experiments on state-of-the-art large language models across 1000+ instruction-following tasks, arithmetic reasoning tasks, and general reasoning tasks. The results demonstrate the superior performance of our method in improving generalization on new tasks and reducing forgetting in old tasks.