 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-driven Disentangled Representation Learning for Multimodal Recommendation
Paper and Code
Dec 22, 2023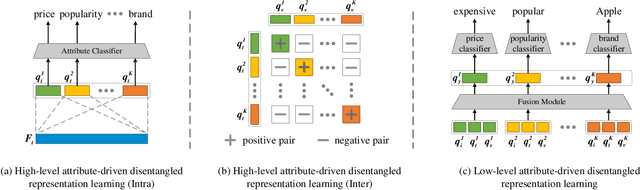

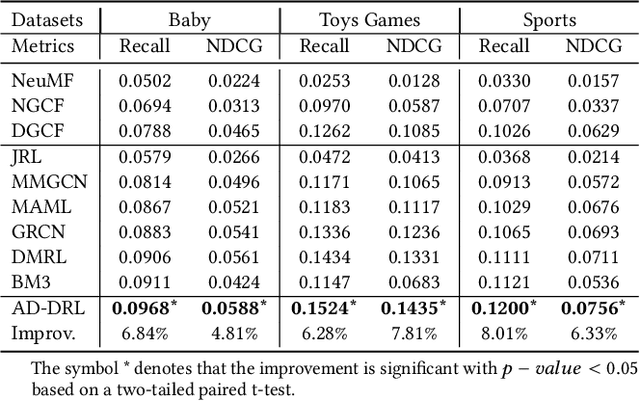
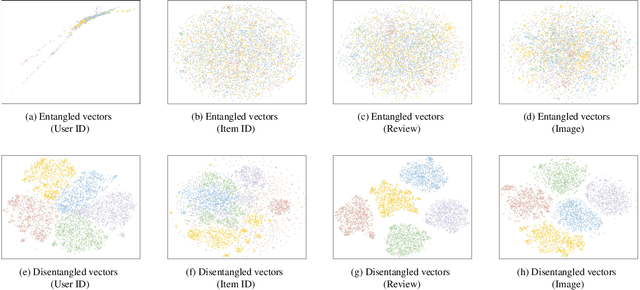
Recommendation algorithms forecast user preferences by correlating user and item representations derived from historical interaction patterns. In pursuit of enhanced performance, many methods focus on learning robust and independent representations by disentangling the intricate factors within interaction data across various modalities in an unsupervised manner. However, such an approach obfuscates the discernment of how specific factors (e.g., category or brand) influence the outcomes, making it challenging to regulate their effects. In response to this challenge, we introduce a novel method called Attribute-Driven Disentangled Representation Learning (short for AD-DRL), which explicitly incorporates attributes from different modalities into the disentangled representation learning process. By assigning a specific attribute to each factor in multimodal features, AD-DRL can disentangle the factors at both attribute and attribute-value levels. To obtain robust and independent representations for each factor associated with a specific attribute, we first disentangle the representations of features both within and across different modalities. Moreover, we further enhance the robustness of the representations by fusing the multimodal features of the same factor. Empirical evaluations conducted on three public real-world datasets substantiate the effectiveness of AD-DRL, as well as its interpretability and controllability.