 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMBRec: Robust Multi-Behavior Recommendation towards Target Behaviors
Jan 13, 2026Multi-behavior recommendation faces a critical challenge in practice: auxiliary behaviors (e.g., clicks, carts) are often noisy, weakly correlated, or semantically misaligned with the target behavior (e.g., purchase), which leads to biased preference learning and suboptimal performance. While existing methods attempt to fuse these heterogeneous signals, they inherently lack a principled mechanism to ensure robustness against such behavioral inconsistency. In this work, we propose Robust Multi-Behavior Recommendation towards Target Behaviors (RMBRec), a robust multi-behavior recommendation framework grounded in an information-theoretic robustness principle. We interpret robustness as a joint process of maximizing predictive information while minimizing its variance across heterogeneous behavioral environments. Under this perspective, the Representation Robustness Module (RRM) enhances local semantic consistency by maximizing the mutual information between users' auxiliary and target representations, whereas the Optimization Robustness Module (ORM) enforces global stability by minimizing the variance of predictive risks across behaviors, which is an efficient approximation to invariant risk minimization. This local-global collaboration bridges representation purification and optimization invariance in a theoretically coherent way. Extensive experiments on three real-world datasets demonstrate that RMBRec not only outperforms state-of-the-art methods in accuracy but also maintains remarkable stability under various noise perturbations. For reproducibility, our code is available at https://github.com/miaomiao-cai2/RMBRec/.
Towards Efficient General Feature Prediction in Masked Skeleton Modeling
Sep 03, 2025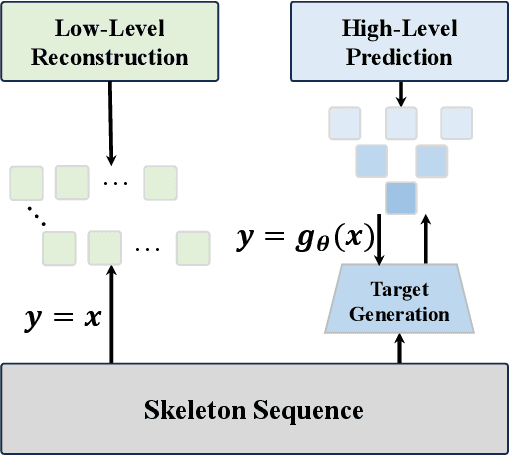
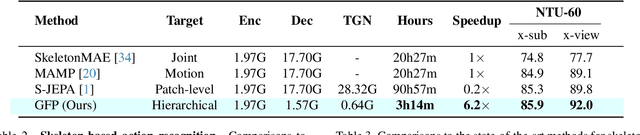
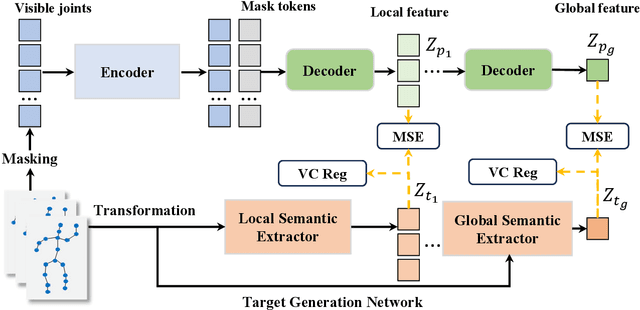
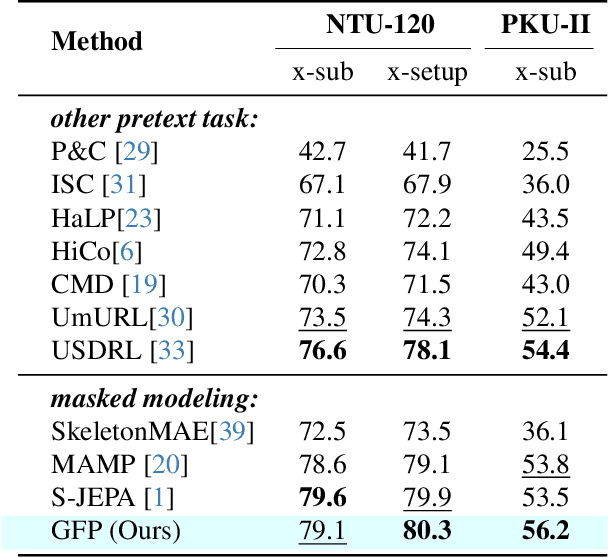
Recent advances in the masked autoencoder (MAE) paradigm have significantly propelled self-supervised skeleton-based action recognition. However, most existing approaches limit reconstruction targets to raw joint coordinates or their simple variants, resulting in computational redundancy and limited semantic representation. To address this, we propose a novel General Feature Prediction framework (GFP) for efficient mask skeleton modeling. Our key innovation is replacing conventional low-level reconstruction with high-level feature prediction that spans from local motion patterns to global semantic representations. Specifically, we introduce a collaborative learning framework where a lightweight target generation network dynamically produces diversified supervision signals across spatial-temporal hierarchies, avoiding reliance on pre-computed offline features. The framework incorporates constrained optimization to ensure feature diversity while preventing model collapse. Experiments on NTU RGB+D 60, NTU RGB+D 120 and PKU-MMD demonstrate the benefits of our approach: Computational efficiency (with 6.2$\times$ faster training than standard masked skeleton modeling methods) and superior representation quality, achieving state-of-the-art performance in various downstream tasks.
I$^3$-MRec: Invariant Learning with Information Bottleneck for Incomplete Modality Recommendation
Aug 06, 2025



Multimodal recommender systems (MRS) improve recommendation performance by integrating diverse semantic information from multiple modalities. However, the assumption of the availability of all modalities rarely holds in practice due to missing images, incomplete descriptions, or inconsistent user content. These challenges significantly degrade the robustness and generalization capabilities of current models. To address these challenges, we introduce a novel method called \textbf{I$^3$-MRec}, which uses \textbf{I}nvariant learning with \textbf{I}nformation bottleneck principle for \textbf{I}ncomplete \textbf{M}odality \textbf{Rec}ommendation. To achieve robust performance in missing modality scenarios, I$^3$-MRec enforces two pivotal properties: (i) cross-modal preference invariance, which ensures consistent user preference modeling across varying modality environments, and (ii) compact yet effective modality representation, which filters out task-irrelevant modality information while maximally preserving essential features relevant to recommendation. By treating each modality as a distinct semantic environment, I$^3$-MRec employs invariant risk minimization (IRM) to learn modality-specific item representations. In parallel, a missing-aware fusion module grounded in the Information Bottleneck (IB) principle extracts compact and effective item embeddings by suppressing modality noise and preserving core user preference signals. Extensive experiments conducted on three real-world datasets demonstrate that I$^3$-MRec consistently outperforms existing state-of-the-art MRS methods across various modality-missing scenarios, highlighting its effectiveness and robustness in practical applications. The code and processed datasets are released at https://github.com/HuilinChenJN/I3-MRec.
* ACM Multimedia 2025 Accepted
Graph-Structured Driven Dual Adaptation for Mitigating Popularity Bias
Mar 30, 2025Popularity bias challenges recommender systems by causing uneven recommendation performance and amplifying the Matthew effect. Limited user-item interactions confine unpopular items within embedding neighborhoods of few users, leading to representation collapse and reduced model generalization. Existing supervised alignment and reweighting methods mitigate this bias but have key limitations: (1) ignoring inherent variability across Graph Convolutional Networks (GCNs) layers, causing negative effects in deeper layers; (2) reliance on fixed hyperparameters to balance item popularity, restricting adaptability and increasing complexity. To address these issues, we propose the Graph-Structured Dual Adaptation Framework (GSDA). Our theoretical analysis identifies a crucial limitation of supervised alignment methods caused by over-smoothing in GCNs. As GCN layers deepen, popular and unpopular items increasingly lose distinctiveness, quantified by reduced conditional entropy. This diminished distinctiveness weakens supervised alignment effectiveness in mitigating popularity bias. Motivated by this, GSDA captures structural and distribution characteristics from the adjacency matrix through a dual adaptive strategy. First, a hierarchical adaptive alignment mechanism uses the adjacency matrix's Frobenius norm for layer-specific weight decay, countering conditional entropy reduction effects at deeper layers. Second, a distribution-aware dynamic contrast weighting strategy, guided by a real-time Gini coefficient, removes dependence on fixed hyperparameters, enabling adaptability to diverse data. Experiments on three benchmark datasets demonstrate GSDA significantly alleviates popularity bias and consistently outperforms state-of-the-art recommendation methods.
Federated Semantic Learning for Privacy-preserving Cross-domain Recommendation
Mar 29, 2025In the evolving landscape of recommender systems, the challenge of effectively conducting privacy-preserving Cross-Domain Recommendation (CDR), especially under strict non-overlapping constraints, has emerged as a key focus. Despite extensive research has made significant progress, several limitations still exist: 1) Previous semantic-based methods fail to deeply exploit rich textual information, since they quantize the text into codes, losing its original rich semantics. 2) The current solution solely relies on the text-modality, while the synergistic effects with the ID-modality are ignored. 3) Existing studies do not consider the impact of irrelevant semantic features, leading to inaccurate semantic representation. To address these challenges, we introduce federated semantic learning and devise FFMSR as our solution. For Limitation 1, we locally learn items'semantic encodings from their original texts by a multi-layer semantic encoder, and then cluster them on the server to facilitate the transfer of semantic knowledge between domains. To tackle Limitation 2, we integrate both ID and Text modalities on the clients, and utilize them to learn different aspects of items. To handle Limitation 3, a Fast Fourier Transform (FFT)-based filter and a gating mechanism are developed to alleviate the impact of irrelevant semantic information in the local model. We conduct extensive experiments on two real-world datasets, and the results demonstrate the superiority of our FFMSR method over other SOTA methods. Our source codes are publicly available at: https://github.com/Sapphire-star/FFMSR.
Behavior Pattern Mining-based Multi-Behavior Recommendation
Aug 22, 2024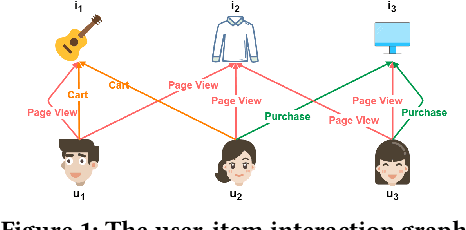
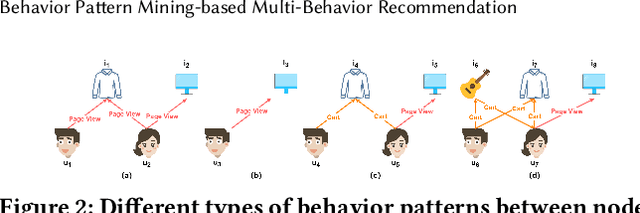
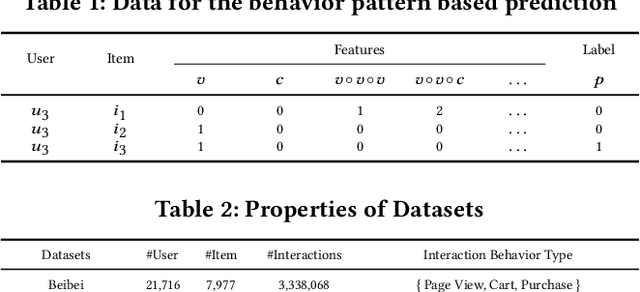
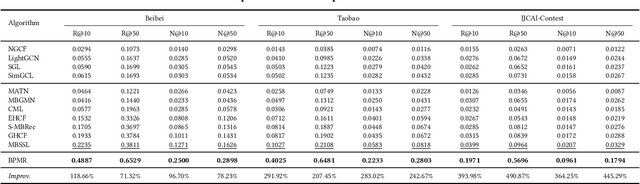
Multi-behavior recommendation systems enhance effectiveness by leveraging auxiliary behaviors (such as page views and favorites) to address the limitations of traditional models that depend solely on sparse target behaviors like purchases. Existing approaches to multi-behavior recommendations typically follow one of two strategies: some derive initial node representations from individual behavior subgraphs before integrating them for a comprehensive profile, while others interpret multi-behavior data as a heterogeneous graph, applying graph neural networks to achieve a unified node representation. However, these methods do not adequately explore the intricate patterns of behavior among users and items. To bridge this gap, we introduce a novel algorithm called Behavior Pattern mining-based Multi-behavior Recommendation (BPMR). Our method extensively investigates the diverse interaction patterns between users and items, utilizing these patterns as features for making recommendations. We employ a Bayesian approach to streamline the recommendation process, effectively circumventing the challenges posed by graph neural network algorithms, such as the inability to accurately capture user preferences due to over-smoothing. Our experimental evaluation on three real-world datasets demonstrates that BPMR significantly outperforms existing state-of-the-art algorithms, showing an average improvement of 268.29% in Recall@10 and 248.02% in NDCG@10 metrics. The code of our BPMR is openly accessible for use and further research at https://github.com/rookitkitlee/BPMR.
Behavior-Contextualized Item Preference Modeling for Multi-Behavior Recommendation
Apr 28, 2024In recommender systems, multi-behavior methods have demonstrated their effectiveness in mitigating issues like data sparsity, a common challenge in traditional single-behavior recommendation approaches. These methods typically infer user preferences from various auxiliary behaviors and apply them to the target behavior for recommendations. However, this direct transfer can introduce noise to the target behavior in recommendation, due to variations in user attention across different behaviors. To address this issue, this paper introduces a novel approach, Behavior-Contextualized Item Preference Modeling (BCIPM), for multi-behavior recommendation. Our proposed Behavior-Contextualized Item Preference Network discerns and learns users' specific item preferences within each behavior. It then considers only those preferences relevant to the target behavior for final recommendations, significantly reducing noise from auxiliary behaviors. These auxiliary behaviors are utilized solely for training the network parameters, thereby refining the learning process without compromising the accuracy of the target behavior recommendations. To further enhance the effectiveness of BCIPM, we adopt a strategy of pre-training the initial embeddings. This step is crucial for enriching the item-aware preferences, particularly in scenarios where data related to the target behavior is sparse. Comprehensive experiments conducted on four real-world datasets demonstrate BCIPM's superior performance compared to several leading state-of-the-art models, validating the robustness and efficiency of our proposed approach.
Disentangled Cascaded Graph Convolution Networks for Multi-Behavior Recommendation
Apr 17, 2024Multi-behavioral recommender systems have emerged as a solution to address data sparsity and cold-start issues by incorporating auxiliary behaviors alongside target behaviors. However, existing models struggle to accurately capture varying user preferences across different behaviors and fail to account for diverse item preferences within behaviors. Various user preference factors (such as price or quality) entangled in the behavior may lead to sub-optimization problems. Furthermore, these models overlook the personalized nature of user behavioral preferences by employing uniform transformation networks for all users and items. To tackle these challenges, we propose the Disentangled Cascaded Graph Convolutional Network (Disen-CGCN), a novel multi-behavior recommendation model. Disen-CGCN employs disentangled representation techniques to effectively separate factors within user and item representations, ensuring their independence. In addition, it incorporates a multi-behavioral meta-network, enabling personalized feature transformation across user and item behaviors. Furthermore, an attention mechanism captures user preferences for different item factors within each behavior. By leveraging attention weights, we aggregate user and item embeddings separately for each behavior, computing preference scores that predict overall user preferences for items. Our evaluation on benchmark datasets demonstrates the superiority of Disen-CGCN over state-of-the-art models, showcasing an average performance improvement of 7.07% and 9.00% on respective datasets. These results highlight Disen-CGCN's ability to effectively leverage multi-behavioral data, leading to more accurate recommendations.
Cluster-based Graph Collaborative Filtering
Apr 16, 2024Graph Convolution Networks (GCNs) have significantly succeeded in learning user and item representations for recommendation systems. The core of their efficacy is the ability to explicitly exploit the collaborative signals from both the first- and high-order neighboring nodes. However, most existing GCN-based methods overlook the multiple interests of users while performing high-order graph convolution. Thus, the noisy information from unreliable neighbor nodes (e.g., users with dissimilar interests) negatively impacts the representation learning of the target node. Additionally, conducting graph convolution operations without differentiating high-order neighbors suffers the over-smoothing issue when stacking more layers, resulting in performance degradation. In this paper, we aim to capture more valuable information from high-order neighboring nodes while avoiding noise for better representation learning of the target node. To achieve this goal, we propose a novel GCN-based recommendation model, termed Cluster-based Graph Collaborative Filtering (ClusterGCF). This model performs high-order graph convolution on cluster-specific graphs, which are constructed by capturing the multiple interests of users and identifying the common interests among them. Specifically, we design an unsupervised and optimizable soft node clustering approach to classify user and item nodes into multiple clusters. Based on the soft node clustering results and the topology of the user-item interaction graph, we assign the nodes with probabilities for different clusters to construct the cluster-specific graphs. To evaluate the effectiveness of ClusterGCF, we conducted extensive experiments on four publicly available datasets. Experimental results demonstrate that our model can significantly improve recommendation performance.
Understanding Before Recommendation: Semantic Aspect-Aware Review Exploitation via Large Language Models
Dec 26, 2023Recommendation systems harness user-item interactions like clicks and reviews to learn their representations. Previous studies improve recommendation accuracy and interpretability by modeling user preferences across various aspects and intents. However, the aspects and intents are inferred directly from user reviews or behavior patterns, suffering from the data noise and the data sparsity problem. Furthermore, it is difficult to understand the reasons behind recommendations due to the challenges of interpreting implicit aspects and intents. Inspired by the deep semantic understanding offered by large language models (LLMs), we introduce a chain-based prompting approach to uncover semantic aspect-aware interactions, which provide clearer insights into user behaviors at a fine-grained semantic level. To incorporate the abundant interactions of various aspects, we propose the simple yet effective Semantic Aspect-based Graph Convolution Network (short for SAGCN). By performing graph convolutions on multiple semantic aspect graphs, SAGCN efficiently combines embeddings across multiple semantic aspects for final user and item representations. The effectiveness of the SAGCN was evaluated on three publicly available datasets through extensive experiments, which revealed that it outperforms all other competitors. Furthermore, interpretability analysis experiments were conducted to demonstrate the interpretability of incorporating semantic aspects into the model.