 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Clues to Generation: Language-Guided Conditional Diffusion for Cross-Domain Recommendation
Apr 07, 2026Cross-domain Recommendation (CDR) exploits multi-domain correlations to alleviate data sparsity. As a core task within this field, inter-domain recommendation focuses on predicting preferences for users who interact in a source domain but lack behavioral records in a target domain. Existing approaches predominantly rely on overlapping users as anchors for knowledge transfer. In real-world scenarios, overlapping users are often scarce, leaving the vast majority of users with only single-domain interactions. For these users, the absence of explicit alignment signals makes fine-grained preference transfer intrinsically difficult. To address this challenge, this paper proposes Language-Guided Conditional Diffusion for CDR (LGCD), a novel framework that integrates Large Language Models (LLMs) and diffusion models for inter-domain sequential recommendation. Specifically, we leverage LLM reasoning to bridge the domain gap by inferring potential target preferences for single-domain users and mapping them to real items, thereby constructing pseudo-overlapping data. We distinguish between real and pseudo-interaction pathways and introduce additional supervision constraints to mitigate the semantic noise brought by pseudo-interaction. Furthermore, we design a conditional diffusion architecture to precisely guide the generation of target user representations based on source-domain patterns. Extensive experiments demonstrate that LGCD significantly outperforms state-of-the-art methods in inter-domain recommendation tasks.
Federated Semantic Learning for Privacy-preserving Cross-domain Recommendation
Mar 29, 2025In the evolving landscape of recommender systems, the challenge of effectively conducting privacy-preserving Cross-Domain Recommendation (CDR), especially under strict non-overlapping constraints, has emerged as a key focus. Despite extensive research has made significant progress, several limitations still exist: 1) Previous semantic-based methods fail to deeply exploit rich textual information, since they quantize the text into codes, losing its original rich semantics. 2) The current solution solely relies on the text-modality, while the synergistic effects with the ID-modality are ignored. 3) Existing studies do not consider the impact of irrelevant semantic features, leading to inaccurate semantic representation. To address these challenges, we introduce federated semantic learning and devise FFMSR as our solution. For Limitation 1, we locally learn items'semantic encodings from their original texts by a multi-layer semantic encoder, and then cluster them on the server to facilitate the transfer of semantic knowledge between domains. To tackle Limitation 2, we integrate both ID and Text modalities on the clients, and utilize them to learn different aspects of items. To handle Limitation 3, a Fast Fourier Transform (FFT)-based filter and a gating mechanism are developed to alleviate the impact of irrelevant semantic information in the local model. We conduct extensive experiments on two real-world datasets, and the results demonstrate the superiority of our FFMSR method over other SOTA methods. Our source codes are publicly available at: https://github.com/Sapphire-star/FFMSR.
Prompt-enhanced Federated Content Representation Learning for Cross-domain Recommendation
Jan 31, 2024



Cross-domain Recommendation (CDR) as one of the effective techniques in alleviating the data sparsity issues has been widely studied in recent years. However, previous works may cause domain privacy leakage since they necessitate the aggregation of diverse domain data into a centralized server during the training process. Though several studies have conducted privacy preserving CDR via Federated Learning (FL), they still have the following limitations: 1) They need to upload users' personal information to the central server, posing the risk of leaking user privacy. 2) Existing federated methods mainly rely on atomic item IDs to represent items, which prevents them from modeling items in a unified feature space, increasing the challenge of knowledge transfer among domains. 3) They are all based on the premise of knowing overlapped users between domains, which proves impractical in real-world applications. To address the above limitations, we focus on Privacy-preserving Cross-domain Recommendation (PCDR) and propose PFCR as our solution. For Limitation 1, we develop a FL schema by exclusively utilizing users' interactions with local clients and devising an encryption method for gradient encryption. For Limitation 2, we model items in a universal feature space by their description texts. For Limitation 3, we initially learn federated content representations, harnessing the generality of natural language to establish bridges between domains. Subsequently, we craft two prompt fine-tuning strategies to tailor the pre-trained model to the target domain. Extensive experiments on two real-world datasets demonstrate the superiority of our PFCR method compared to the SOTA approaches.
Unsupervised Typography Transfer
Feb 07, 2018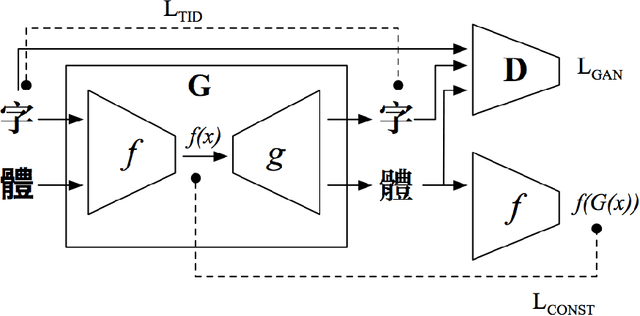


Traditional methods in Chinese typography synthesis view characters as an assembly of radicals and strokes, but they rely on manual definition of the key points, which is still time-costing. Some recent work on computer vision proposes a brand new approach: to treat every Chinese character as an independent and inseparable image, so the pre-processing and post-processing of each character can be avoided. Then with a combination of a transfer network and a discriminating network, one typography can be well transferred to another. Despite the quite satisfying performance of the model, the training process requires to be supervised, which means in the training data each character in the source domain and the target domain needs to be perfectly paired. Sometimes the pairing is time-costing, and sometimes there is no perfect pairing, such as the pairing between traditional Chinese and simplified Chinese characters. In this paper, we proposed an unsupervised typography transfer method which doesn't need pairing.