 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCRF: A Federated Cross-domain Recommendation Method with Semantic-driven Deep Knowledge Fusion
Apr 20, 2026As user behavior data becomes increasingly scattered across different platforms, achieving cross-domain knowledge fusion while preserving privacy has become a critical issue in recommender systems. Existing PPCDR methods usually rely on overlapping users or items as a bridge, making them inapplicable to non-overlapping scenarios. They also suffer from limitations in the collaborative modeling of global and local semantics. To this end, this paper proposes a Federated Cross-domain Recommendation method with deep knowledge Fusion (FedCRF). Using textual semantics as a cross-domain bridge, FedCRF achieves cross-domain knowledge transfer via federated semantic learning under the non-overlapping scenario. Specifically, FedCRF constructs global semantic clusters on the server side to extract shared semantic information, and designs a FGSAT module on the client side to dynamically adapt to local data distributions and alleviate cross-domain distribution shift. Meanwhile, it builds a semantic graph based on textual features to learn representations that integrate both structural and semantic information, and introduces contrastive learning constraints between global and local semantic representations to enhance semantic consistency and promote deep knowledge fusion. In this framework, only item semantic representations are shared, while user interaction data remains locally stored, effectively mitigating privacy leakage risks. Experimental results on multiple real-world datasets show that FedCRF significantly outperforms existing methods in terms of Recall@20 and NDCG@20, validating its effectiveness and superiority in non-overlapping cross-domain recommendation scenarios.
Federated User Behavior Modeling for Privacy-Preserving LLM Recommendation
Apr 16, 2026Large Language Models have shown great success in recommender systems. However, the limited and sparse nature of user data often restricts the LLM's ability to effectively model behavior patterns. To address this, existing studies have explored cross-domain solutions by conducting Cross-Domain Recommendation tasks. But previous methods typically assume domains are overlapped and can be accessed readily. None of the LLM methods address the privacy-preserving issues in the CDR settings, that is, Privacy-Preserving Cross-Domain Recommendation. Conducting non-overlapping PPCDR with LLM is challenging since: 1)The inability to share user identity or behavioral data across domains impedes effective cross-domain alignment. 2)The heterogeneity of data modalities across domains complicates knowledge integration. 3)Fusing collaborative filtering signals from traditional recommendation models with LLMs is difficult, as they operate within distinct feature spaces. To address the above issues, we propose SF-UBM, a Semantic-enhanced Federated User Behavior Modeling method. Specifically, to deal with Challenge 1, we leverage natural language as a universal bridge to connect disjoint domains via a semantic-enhanced federated architecture. Here, text-based item representations are encrypted and shared, while user-specific data remains local. To handle Challenge 2, we design a Fact-counter Knowledge Distillation module to integrate domain-agnostic knowledge with domain-specific knowledge, across different data modalities. To tackle Challenge 3, we project pre-learned user preferences and cross-domain item representations into the soft prompt space, aligning behavioral and semantic spaces for effective LLM learning. We conduct extensive experiments on three pairs of real-world domains, and the experimental results demonstrate the effectiveness of SF-UBM compared to the recent SOTA methods.
Momentum LMS Theory beyond Stationarity: Stability, Tracking, and Regret
Feb 12, 2026In large-scale data processing scenarios, data often arrive in sequential streams generated by complex systems that exhibit drifting distributions and time-varying system parameters. This nonstationarity challenges theoretical analysis, as it violates classical assumptions of i.i.d. (independent and identically distributed) samples, necessitating algorithms capable of real-time updates without expensive retraining. An effective approach should process each sample in a single pass, while maintaining computational and memory complexities independent of the data stream length. Motivated by these challenges, this paper investigates the Momentum Least Mean Squares (MLMS) algorithm as an adaptive identification tool, leveraging its computational simplicity and online processing capabilities. Theoretically, we derive tracking performance and regret bounds for the MLMS in time-varying stochastic linear systems under various practical conditions. Unlike classical LMS, whose stability can be characterized by first-order random vector difference equations, MLMS introduces an additional dynamical state due to momentum, leading to second-order time-varying random vector difference equations whose stability analysis hinges on more complicated products of random matrices, which poses a substantially challenging problem to resolve. Experiments on synthetic and real-world data streams demonstrate that MLMS achieves rapid adaptation and robust tracking, in agreement with our theoretical results especially in nonstationary settings, highlighting its promise for modern streaming and online learning applications.
Semantic-enhanced Co-attention Prompt Learning for Non-overlapping Cross-Domain Recommendation
May 25, 2025Non-overlapping Cross-domain Sequential Recommendation (NCSR) is the task that focuses on domain knowledge transfer without overlapping entities. Compared with traditional Cross-domain Sequential Recommendation (CSR), NCSR poses several challenges: 1) NCSR methods often rely on explicit item IDs, overlooking semantic information among entities. 2) Existing CSR mainly relies on domain alignment for knowledge transfer, risking semantic loss during alignment. 3) Most previous studies do not consider the many-to-one characteristic, which is challenging because of the utilization of multiple source domains. Given the above challenges, we introduce the prompt learning technique for Many-to-one Non-overlapping Cross-domain Sequential Recommendation (MNCSR) and propose a Text-enhanced Co-attention Prompt Learning Paradigm (TCPLP). Specifically, we capture semantic meanings by representing items through text rather than IDs, leveraging natural language universality to facilitate cross-domain knowledge transfer. Unlike prior works that need to conduct domain alignment, we directly learn transferable domain information, where two types of prompts, i.e., domain-shared and domain-specific prompts, are devised, with a co-attention-based network for prompt encoding. Then, we develop a two-stage learning strategy, i.e., pre-train & prompt-tuning paradigm, for domain knowledge pre-learning and transferring, respectively. We conduct extensive experiments on three datasets and the experimental results demonstrate the superiority of our TCPLP. Our source codes have been publicly released.
Adaptive Sentencing Prediction with Guaranteed Accuracy and Legal Interpretability
May 20, 2025



Existing research on judicial sentencing prediction predominantly relies on end-to-end models, which often neglect the inherent sentencing logic and lack interpretability-a critical requirement for both scholarly research and judicial practice. To address this challenge, we make three key contributions:First, we propose a novel Saturated Mechanistic Sentencing (SMS) model, which provides inherent legal interpretability by virtue of its foundation in China's Criminal Law. We also introduce the corresponding Momentum Least Mean Squares (MLMS) adaptive algorithm for this model. Second, for the MLMS algorithm based adaptive sentencing predictor, we establish a mathematical theory on the accuracy of adaptive prediction without resorting to any stationarity and independence assumptions on the data. We also provide a best possible upper bound for the prediction accuracy achievable by the best predictor designed in the known parameters case. Third, we construct a Chinese Intentional Bodily Harm (CIBH) dataset. Utilizing this real-world data, extensive experiments demonstrate that our approach achieves a prediction accuracy that is not far from the best possible theoretical upper bound, validating both the model's suitability and the algorithm's accuracy.
Federated Semantic Learning for Privacy-preserving Cross-domain Recommendation
Mar 29, 2025In the evolving landscape of recommender systems, the challenge of effectively conducting privacy-preserving Cross-Domain Recommendation (CDR), especially under strict non-overlapping constraints, has emerged as a key focus. Despite extensive research has made significant progress, several limitations still exist: 1) Previous semantic-based methods fail to deeply exploit rich textual information, since they quantize the text into codes, losing its original rich semantics. 2) The current solution solely relies on the text-modality, while the synergistic effects with the ID-modality are ignored. 3) Existing studies do not consider the impact of irrelevant semantic features, leading to inaccurate semantic representation. To address these challenges, we introduce federated semantic learning and devise FFMSR as our solution. For Limitation 1, we locally learn items'semantic encodings from their original texts by a multi-layer semantic encoder, and then cluster them on the server to facilitate the transfer of semantic knowledge between domains. To tackle Limitation 2, we integrate both ID and Text modalities on the clients, and utilize them to learn different aspects of items. To handle Limitation 3, a Fast Fourier Transform (FFT)-based filter and a gating mechanism are developed to alleviate the impact of irrelevant semantic information in the local model. We conduct extensive experiments on two real-world datasets, and the results demonstrate the superiority of our FFMSR method over other SOTA methods. Our source codes are publicly available at: https://github.com/Sapphire-star/FFMSR.
BadRefSR: Backdoor Attacks Against Reference-based Image Super Resolution
Feb 28, 2025Reference-based image super-resolution (RefSR) represents a promising advancement in super-resolution (SR). In contrast to single-image super-resolution (SISR), RefSR leverages an additional reference image to help recover high-frequency details, yet its vulnerability to backdoor attacks has not been explored. To fill this research gap, we propose a novel attack framework called BadRefSR, which embeds backdoors in the RefSR model by adding triggers to the reference images and training with a mixed loss function. Extensive experiments across various backdoor attack settings demonstrate the effectiveness of BadRefSR. The compromised RefSR network performs normally on clean input images, while outputting attacker-specified target images on triggered input images. Our study aims to alert researchers to the potential backdoor risks in RefSR. Codes are available at https://github.com/xuefusiji/BadRefSR.
Feedback Favors the Generalization of Neural ODEs
Oct 14, 2024



The well-known generalization problem hinders the application of artificial neural networks in continuous-time prediction tasks with varying latent dynamics. In sharp contrast, biological systems can neatly adapt to evolving environments benefiting from real-time feedback mechanisms. Inspired by the feedback philosophy, we present feedback neural networks, showing that a feedback loop can flexibly correct the learned latent dynamics of neural ordinary differential equations (neural ODEs), leading to a prominent generalization improvement. The feedback neural network is a novel two-DOF neural network, which possesses robust performance in unseen scenarios with no loss of accuracy performance on previous tasks. A linear feedback form is presented to correct the learned latent dynamics firstly, with a convergence guarantee. Then, domain randomization is utilized to learn a nonlinear neural feedback form. Finally, extensive tests including trajectory prediction of a real irregular object and model predictive control of a quadrotor with various uncertainties, are implemented, indicating significant improvements over state-of-the-art model-based and learning-based methods.
3D-CT-GPT: Generating 3D Radiology Reports through Integration of Large Vision-Language Models
Sep 28, 2024



Medical image analysis is crucial in modern radiological diagnostics, especially given the exponential growth in medical imaging data. The demand for automated report generation systems has become increasingly urgent. While prior research has mainly focused on using machine learning and multimodal language models for 2D medical images, the generation of reports for 3D medical images has been less explored due to data scarcity and computational complexities. This paper introduces 3D-CT-GPT, a Visual Question Answering (VQA)-based medical visual language model specifically designed for generating radiology reports from 3D CT scans, particularly chest CTs. Extensive experiments on both public and private datasets demonstrate that 3D-CT-GPT significantly outperforms existing methods in terms of report accuracy and quality. Although current methods are few, including the partially open-source CT2Rep and the open-source M3D, we ensured fair comparison through appropriate data conversion and evaluation methodologies. Experimental results indicate that 3D-CT-GPT enhances diagnostic accuracy and report coherence, establishing itself as a robust solution for clinical radiology report generation. Future work will focus on expanding the dataset and further optimizing the model to enhance its performance and applicability.
A Survey of Foundation Models for Music Understanding
Sep 15, 2024
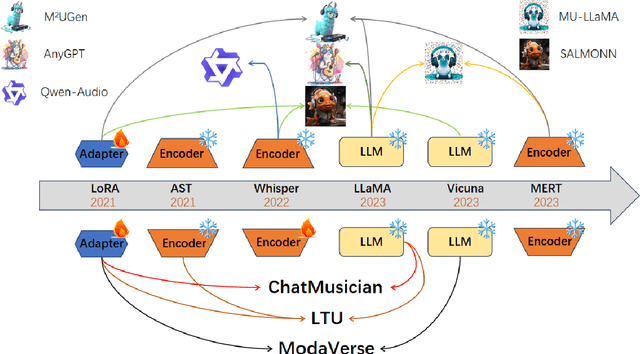
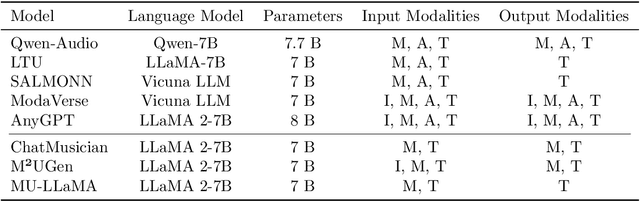
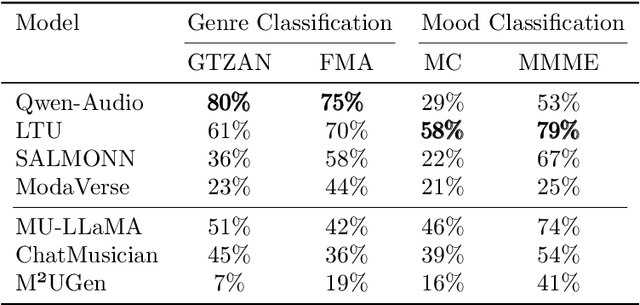
Music is essential in daily life, fulfilling emotional and entertainment needs, and connecting us personally, socially, and culturally. A better understanding of music can enhance our emotions, cognitive skills, and cultural connections. The rapid advancement of artificial intelligence (AI) has introduced new ways to analyze music, aiming to replicate human understanding of music and provide related services. While the traditional models focused on audio features and simple tasks, the recent development of large language models (LLMs) and foundation models (FMs), which excel in various fields by integrating semantic information and demonstrating strong reasoning abilities, could capture complex musical features and patterns, integrate music with language and incorporate rich musical, emotional and psychological knowledge. Therefore, they have the potential in handling complex music understanding tasks from a semantic perspective, producing outputs closer to human perception. This work, to our best knowledge, is one of the early reviews of the intersection of AI techniques and music understanding. We investigated, analyzed, and tested recent large-scale music foundation models in respect of their music comprehension abilities. We also discussed their limitations and proposed possible future directions, offering insights for researchers in this field.