 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Learning for Possibilistic Logic Programs Under Stable Models
Oct 08, 2025Possibilistic logic programs (poss-programs) under stable models are a major variant of answer set programming (ASP). While its semantics (possibilistic stable models) and properties have been well investigated, the problem of inductive reasoning has not been investigated yet. This paper presents an approach to extracting poss-programs from a background program and examples (parts of intended possibilistic stable models). To this end, the notion of induction tasks is first formally defined, its properties are investigated and two algorithms ilpsm and ilpsmmin for computing induction solutions are presented. An implementation of ilpsmmin is also provided and experimental results show that when inputs are ordinary logic programs, the prototype outperforms a major inductive learning system for normal logic programs from stable models on the datasets that are randomly generated.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
Visual-Semantic Graph Matching Net for Zero-Shot Learning
Nov 18, 2024Zero-shot learning (ZSL) aims to leverage additional semantic information to recognize unseen classes. To transfer knowledge from seen to unseen classes, most ZSL methods often learn a shared embedding space by simply aligning visual embeddings with semantic prototypes. However, methods trained under this paradigm often struggle to learn robust embedding space because they align the two modalities in an isolated manner among classes, which ignore the crucial class relationship during the alignment process. To address the aforementioned challenges, this paper proposes a Visual-Semantic Graph Matching Net, termed as VSGMN, which leverages semantic relationships among classes to aid in visual-semantic embedding. VSGMN employs a Graph Build Network (GBN) and a Graph Matching Network (GMN) to achieve two-stage visual-semantic alignment. Specifically, GBN first utilizes an embedding-based approach to build visual and semantic graphs in the semantic space and align the embedding with its prototype for first-stage alignment. Additionally, to supplement unseen class relations in these graphs, GBN also build the unseen class nodes based on semantic relationships. In the second stage, GMN continuously integrates neighbor and cross-graph information into the constructed graph nodes, and aligns the node relationships between the two graphs under the class relationship constraint. Extensive experiments on three benchmark datasets demonstrate that VSGMN achieves superior performance in both conventional and generalized ZSL scenarios. The implementation of our VSGMN and experimental results are available at github: https://github.com/dbwfd/VSGMN
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024
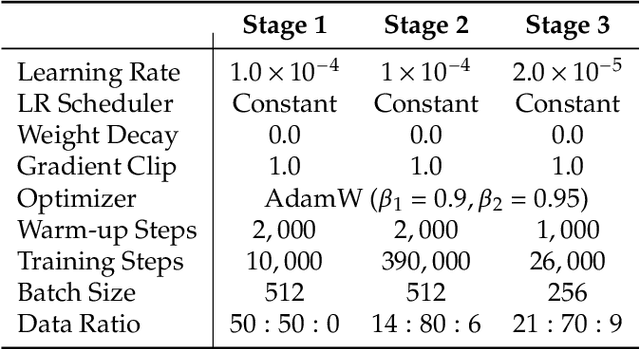

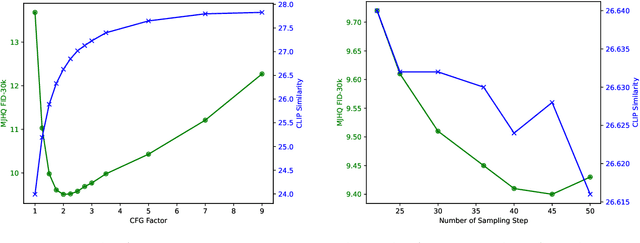
We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
3D-CT-GPT: Generating 3D Radiology Reports through Integration of Large Vision-Language Models
Sep 28, 2024



Medical image analysis is crucial in modern radiological diagnostics, especially given the exponential growth in medical imaging data. The demand for automated report generation systems has become increasingly urgent. While prior research has mainly focused on using machine learning and multimodal language models for 2D medical images, the generation of reports for 3D medical images has been less explored due to data scarcity and computational complexities. This paper introduces 3D-CT-GPT, a Visual Question Answering (VQA)-based medical visual language model specifically designed for generating radiology reports from 3D CT scans, particularly chest CTs. Extensive experiments on both public and private datasets demonstrate that 3D-CT-GPT significantly outperforms existing methods in terms of report accuracy and quality. Although current methods are few, including the partially open-source CT2Rep and the open-source M3D, we ensured fair comparison through appropriate data conversion and evaluation methodologies. Experimental results indicate that 3D-CT-GPT enhances diagnostic accuracy and report coherence, establishing itself as a robust solution for clinical radiology report generation. Future work will focus on expanding the dataset and further optimizing the model to enhance its performance and applicability.
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Jan 23, 2024
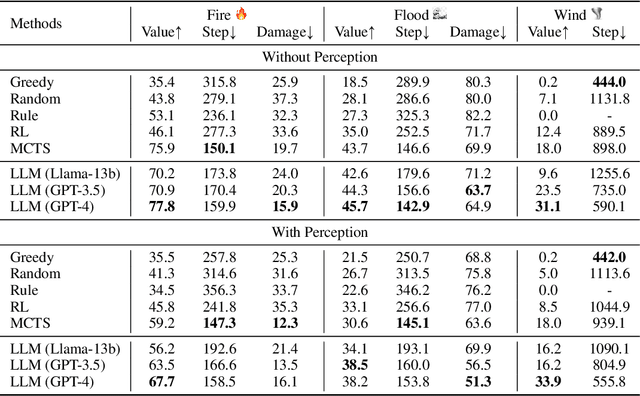

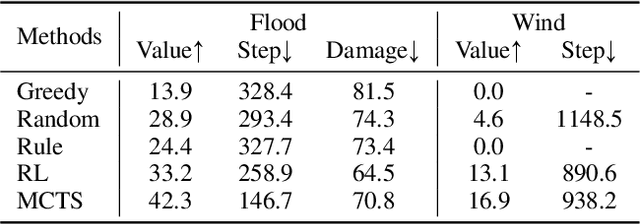
Recent advances in high-fidelity virtual environments serve as one of the major driving forces for building intelligent embodied agents to perceive, reason and interact with the physical world. Typically, these environments remain unchanged unless agents interact with them. However, in real-world scenarios, agents might also face dynamically changing environments characterized by unexpected events and need to rapidly take action accordingly. To remedy this gap, we propose a new simulated embodied benchmark, called HAZARD, specifically designed to assess the decision-making abilities of embodied agents in dynamic situations. HAZARD consists of three unexpected disaster scenarios, including fire, flood, and wind, and specifically supports the utilization of large language models (LLMs) to assist common sense reasoning and decision-making. This benchmark enables us to evaluate autonomous agents' decision-making capabilities across various pipelines, including reinforcement learning (RL), rule-based, and search-based methods in dynamically changing environments. As a first step toward addressing this challenge using large language models, we further develop an LLM-based agent and perform an in-depth analysis of its promise and challenge of solving these challenging tasks. HAZARD is available at https://vis-www.cs.umass.edu/hazard/.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023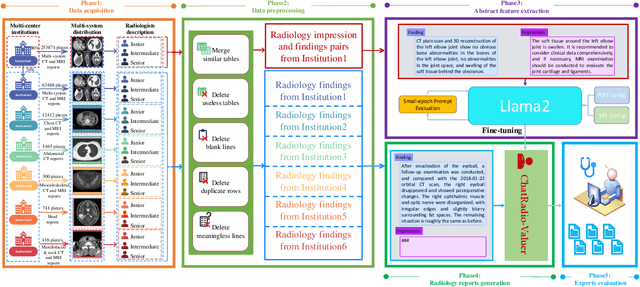
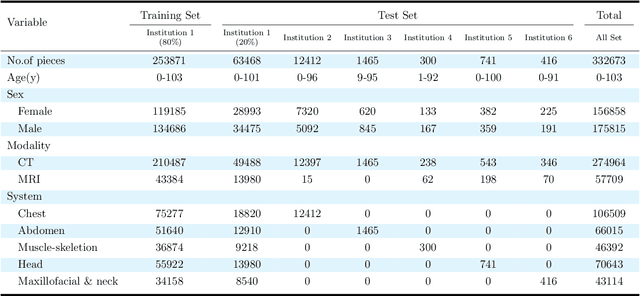
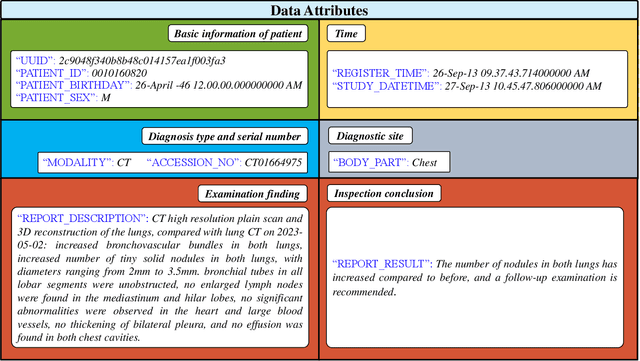
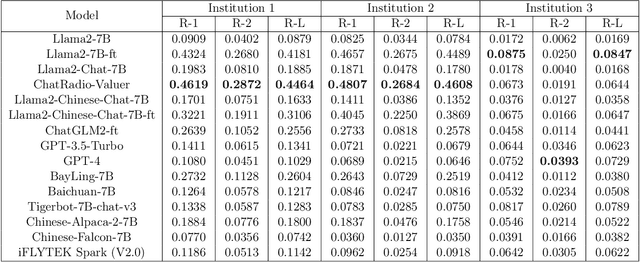
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
On Sufficient and Necessary Conditions in Bounded CTL
Mar 13, 2020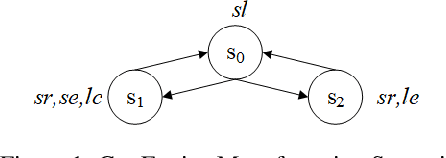
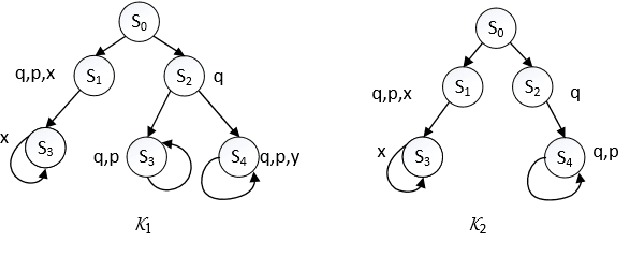

Computation Tree Logic (CTL) is one of the central formalisms in formal verification. As a specification language, it is used to express a property that the system at hand is expected to satisfy. From both the verification and the system design points of view, some information content of such property might become irrelevant for the system due to various reasons e.g., it might become obsolete by time, or perhaps infeasible due to practical difficulties. Then, the problem arises on how to subtract such piece of information without altering the relevant system behaviour or violating the existing specifications. Moreover, in such a scenario, two crucial notions are informative: the strongest necessary condition (SNC) and the weakest sufficient condition (WSC) of a given property. To address such a scenario in a principled way, we introduce a forgetting-based approach in CTL and show that it can be used to compute SNC and WSC of a property under a given model. We study its theoretical properties and also show that our notion of forgetting satisfies existing essential postulates. Furthermore, we analyse the computational complexity of basic tasks, including various results for the relevant fragment CTLAF.