 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ontology for Unified Modeling of Tasks, Actions, Environments, and Capabilities in Personal Service Robotics
Sep 26, 2025



Personal service robots are increasingly used in domestic settings to assist older adults and people requiring support. Effective operation involves not only physical interaction but also the ability to interpret dynamic environments, understand tasks, and choose appropriate actions based on context. This requires integrating both hardware components (e.g. sensors, actuators) and software systems capable of reasoning about tasks, environments, and robot capabilities. Frameworks such as the Robot Operating System (ROS) provide open-source tools that help connect low-level hardware with higher-level functionalities. However, real-world deployments remain tightly coupled to specific platforms. As a result, solutions are often isolated and hard-coded, limiting interoperability, reusability, and knowledge sharing. Ontologies and knowledge graphs offer a structured way to represent tasks, environments, and robot capabilities. Existing ontologies, such as the Socio-physical Model of Activities (SOMA) and the Descriptive Ontology for Linguistic and Cognitive Engineering (DOLCE), provide models for activities, spatial relationships, and reasoning structures. However, they often focus on specific domains and do not fully capture the connection between environment, action, robot capabilities, and system-level integration. In this work, we propose the Ontology for roBOts and acTions (OntoBOT), which extends existing ontologies to provide a unified representation of tasks, actions, environments, and capabilities. Our contributions are twofold: (1) we unify these aspects into a cohesive ontology to support formal reasoning about task execution, and (2) we demonstrate its generalizability by evaluating competency questions across four embodied agents - TIAGo, HSR, UR3, and Stretch - showing how OntoBOT enables context-aware reasoning, task-oriented execution, and knowledge sharing in service robotics.
On Sufficient and Necessary Conditions in Bounded CTL
Mar 13, 2020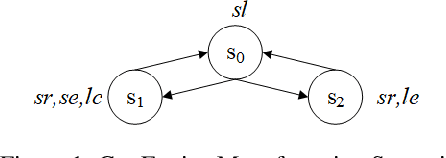
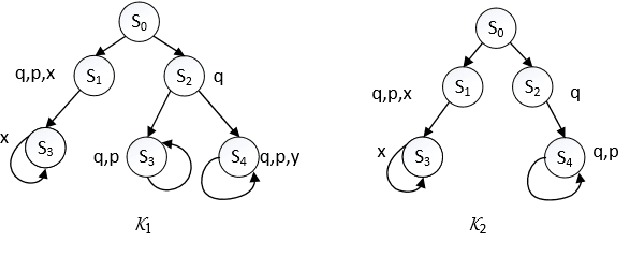

Computation Tree Logic (CTL) is one of the central formalisms in formal verification. As a specification language, it is used to express a property that the system at hand is expected to satisfy. From both the verification and the system design points of view, some information content of such property might become irrelevant for the system due to various reasons e.g., it might become obsolete by time, or perhaps infeasible due to practical difficulties. Then, the problem arises on how to subtract such piece of information without altering the relevant system behaviour or violating the existing specifications. Moreover, in such a scenario, two crucial notions are informative: the strongest necessary condition (SNC) and the weakest sufficient condition (WSC) of a given property. To address such a scenario in a principled way, we introduce a forgetting-based approach in CTL and show that it can be used to compute SNC and WSC of a property under a given model. We study its theoretical properties and also show that our notion of forgetting satisfies existing essential postulates. Furthermore, we analyse the computational complexity of basic tasks, including various results for the relevant fragment CTLAF.
Release Early, Release Often: Predicting Change in Versioned Knowledge Organization Systems on the Web
Sep 15, 2015



The Semantic Web is built on top of Knowledge Organization Systems (KOS) (vocabularies, ontologies, concept schemes) that provide a structured, interoperable and distributed access to Linked Data on the Web. The maintenance of these KOS over time has produced a number of KOS version chains: subsequent unique version identifiers to unique states of a KOS. However, the release of new KOS versions pose challenges to both KOS publishers and users. For publishers, updating a KOS is a knowledge intensive task that requires a lot of manual effort, often implying deep deliberation on the set of changes to introduce. For users that link their datasets to these KOS, a new version compromises the validity of their links, often creating ramifications. In this paper we describe a method to automatically detect which parts of a Web KOS are likely to change in a next version, using supervised learning on past versions in the KOS version chain. We use a set of ontology change features to model and predict change in arbitrary Web KOS. We apply our method on 139 varied datasets systematically retrieved from the Semantic Web, obtaining robust results at correctly predicting change. To illustrate the accuracy, genericity and domain independence of the method, we study the relationship between its effectiveness and several characterizations of the evaluated datasets, finding that predictors like the number of versions in a chain and their release frequency have a fundamental impact in predictability of change in Web KOS. Consequently, we argue for adopting a release early, release often philosophy in Web KOS development cycles.