 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the Explainer: Understanding the Inner Workings of Transformer-based Symbolic Regression Models
Feb 03, 2026Following their success across many domains, transformers have also proven effective for symbolic regression (SR); however, the internal mechanisms underlying their generation of mathematical operators remain largely unexplored. Although mechanistic interpretability has successfully identified circuits in language and vision models, it has not yet been applied to SR. In this article, we introduce PATCHES, an evolutionary circuit discovery algorithm that identifies compact and correct circuits for SR. Using PATCHES, we isolate 28 circuits, providing the first circuit-level characterisation of an SR transformer. We validate these findings through a robust causal evaluation framework based on key notions such as faithfulness, completeness, and minimality. Our analysis shows that mean patching with performance-based evaluation most reliably isolates functionally correct circuits. In contrast, we demonstrate that direct logit attribution and probing classifiers primarily capture correlational features rather than causal ones, limiting their utility for circuit discovery. Overall, these results establish SR as a high-potential application domain for mechanistic interpretability and propose a principled methodology for circuit discovery.
ECSEL: Explainable Classification via Signomial Equation Learning
Jan 29, 2026We introduce ECSEL, an explainable classification method that learns formal expressions in the form of signomial equations, motivated by the observation that many symbolic regression benchmarks admit compact signomial structure. ECSEL directly constructs a structural, closed-form expression that serves as both a classifier and an explanation. On standard symbolic regression benchmarks, our method recovers a larger fraction of target equations than competing state-of-the-art approaches while requiring substantially less computation. Leveraging this efficiency, ECSEL achieves classification accuracy competitive with established machine learning models without sacrificing interpretability. Further, we show that ECSEL satisfies some desirable properties regarding global feature behavior, decision-boundary analysis, and local feature attributions. Experiments on benchmark datasets and two real-world case studies i.e., e-commerce and fraud detection, demonstrate that the learned equations expose dataset biases, support counterfactual reasoning, and yield actionable insights.
Same Content, Different Answers: Cross-Modal Inconsistency in MLLMs
Dec 09, 2025We introduce two new benchmarks REST and REST+(Render-Equivalence Stress Tests) to enable systematic evaluation of cross-modal inconsistency in multimodal large language models (MLLMs). MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities. Our benchmarks contain samples with the same semantic information in three modalities (image, text, mixed) and we show that state-of-the-art MLLMs cannot consistently reason over these different modalities. We evaluate 15 MLLMs and find that the degree of modality inconsistency varies substantially, even when accounting for problems with text recognition (OCR). Neither rendering text as image nor rendering an image as text solves the inconsistency. Even if OCR is correct, we find that visual characteristics (text colour and resolution, but not font) and the number of vision tokens have an impact on model performance. Finally, we find that our consistency score correlates with the modality gap between text and images, highlighting a mechanistic interpretation of cross-modal inconsistent MLLMs.
ACTIVA: Amortized Causal Effect Estimation without Graphs via Transformer-based Variational Autoencoder
Mar 03, 2025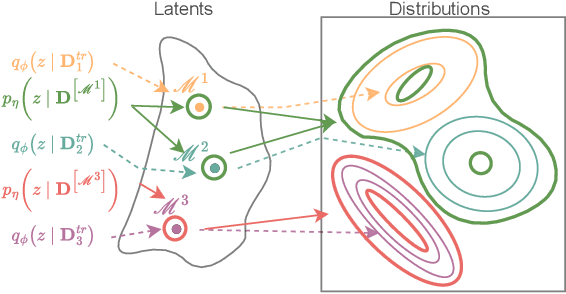
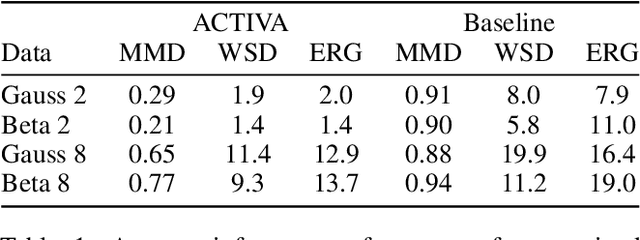
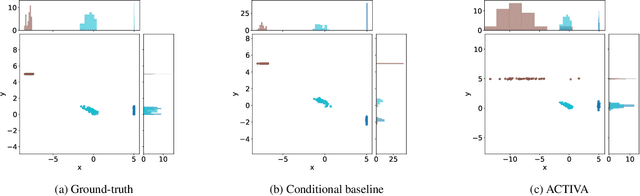

Predicting the distribution of outcomes under hypothetical interventions is crucial in domains like healthcare, economics, and policy-making. Current methods often rely on strong assumptions, such as known causal graphs or parametric models, and lack amortization across problem instances, limiting their practicality. We propose a novel transformer-based conditional variational autoencoder architecture, named ACTIVA, that extends causal transformer encoders to predict causal effects as mixtures of Gaussians. Our method requires no causal graph and predicts interventional distributions given only observational data and a queried intervention. By amortizing over many simulated instances, it enables zero-shot generalization to novel datasets without retraining. Experiments demonstrate accurate predictions for synthetic and semi-synthetic data, showcasing the effectiveness of our graph-free, amortized causal inference approach.
Think Smart, Act SMARL! Analyzing Probabilistic Logic Driven Safety in Multi-Agent Reinforcement Learning
Nov 07, 2024


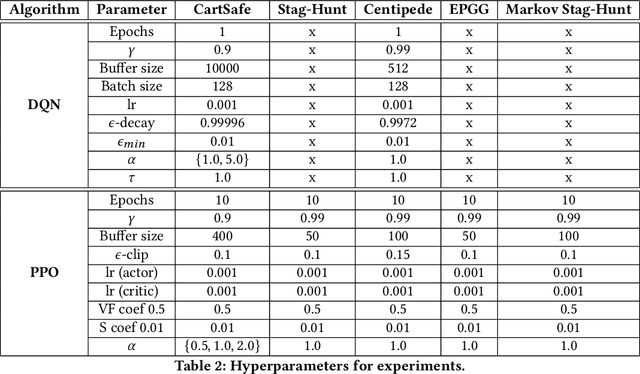
An important challenge for enabling the deployment of reinforcement learning (RL) algorithms in the real world is safety. This has resulted in the recent research field of Safe RL, which aims to learn optimal policies that are safe. One successful approach in that direction is probabilistic logic shields (PLS), a model-based Safe RL technique that uses formal specifications based on probabilistic logic programming, constraining an agent's policy to comply with those specifications in a probabilistic sense. However, safety is inherently a multi-agent concept, since real-world environments often involve multiple agents interacting simultaneously, leading to a complex system which is hard to control. Moreover, safe multi-agent RL (Safe MARL) is still underexplored. In order to address this gap, in this paper we ($i$) introduce Shielded MARL (SMARL) by extending PLS to MARL -- in particular, we introduce Probabilistic Logic Temporal Difference Learning (PLTD) to enable shielded independent Q-learning (SIQL), and introduce shielded independent PPO (SIPPO) using probabilistic logic policy gradients; ($ii$) show its positive effect and use as an equilibrium selection mechanism in various game-theoretic environments including two-player simultaneous games, extensive-form games, stochastic games, and some grid-world extensions in terms of safety, cooperation, and alignment with normative behaviors; and ($iii$) look into the asymmetric case where only one agent is shielded, and show that the shielded agent has a significant influence on the unshielded one, providing further evidence of SMARL's ability to enhance safety and cooperation in diverse multi-agent environments.
Integrating Fuzzy Logic into Deep Symbolic Regression
Nov 01, 2024


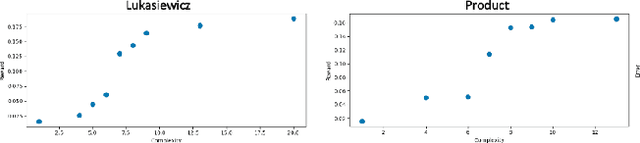
Credit card fraud detection is a critical concern for financial institutions, intensified by the rise of contactless payment technologies. While deep learning models offer high accuracy, their lack of explainability poses significant challenges in financial settings. This paper explores the integration of fuzzy logic into Deep Symbolic Regression (DSR) to enhance both performance and explainability in fraud detection. We investigate the effectiveness of different fuzzy logic implications, specifically {\L}ukasiewicz, G\"odel, and Product, in handling the complexity and uncertainty of fraud detection datasets. Our analysis suggest that the {\L}ukasiewicz implication achieves the highest F1-score and overall accuracy, while the Product implication offers a favorable balance between performance and explainability. Despite having a performance lower than state-of-the-art (SOTA) models due to information loss in data transformation, our approach provides novelty and insights into into integrating fuzzy logic into DSR for fraud detection, providing a comprehensive comparison between different implications and methods.
Enforcing Interpretability in Time Series Transformers: A Concept Bottleneck Framework
Oct 08, 2024



There has been a recent push of research on Transformer-based models for long-term time series forecasting, even though they are inherently difficult to interpret and explain. While there is a large body of work on interpretability methods for various domains and architectures, the interpretability of Transformer-based forecasting models remains largely unexplored. To address this gap, we develop a framework based on Concept Bottleneck Models to enforce interpretability of time series Transformers. We modify the training objective to encourage a model to develop representations similar to predefined interpretable concepts. In our experiments, we enforce similarity using Centered Kernel Alignment, and the predefined concepts include time features and an interpretable, autoregressive surrogate model (AR). We apply the framework to the Autoformer model, and present an in-depth analysis for a variety of benchmark tasks. We find that the model performance remains mostly unaffected, while the model shows much improved interpretability. Additionally, interpretable concepts become local, which makes the trained model easily intervenable. As a proof of concept, we demonstrate a successful intervention in the scenario of a time shift in the data, which eliminates the need to retrain.
DAVIDE: Depth-Aware Video Deblurring
Sep 02, 2024Video deblurring aims at recovering sharp details from a sequence of blurry frames. Despite the proliferation of depth sensors in mobile phones and the potential of depth information to guide deblurring, depth-aware deblurring has received only limited attention. In this work, we introduce the 'Depth-Aware VIdeo DEblurring' (DAVIDE) dataset to study the impact of depth information in video deblurring. The dataset comprises synchronized blurred, sharp, and depth videos. We investigate how the depth information should be injected into the existing deep RGB video deblurring models, and propose a strong baseline for depth-aware video deblurring. Our findings reveal the significance of depth information in video deblurring and provide insights into the use cases where depth cues are beneficial. In addition, our results demonstrate that while the depth improves deblurring performance, this effect diminishes when models are provided with a longer temporal context. Project page: https://germanftv.github.io/DAVIDE.github.io/ .
Learning in Multi-Objective Public Goods Games with Non-Linear Utilities
Aug 01, 2024



Addressing the question of how to achieve optimal decision-making under risk and uncertainty is crucial for enhancing the capabilities of artificial agents that collaborate with or support humans. In this work, we address this question in the context of Public Goods Games. We study learning in a novel multi-objective version of the Public Goods Game where agents have different risk preferences, by means of multi-objective reinforcement learning. We introduce a parametric non-linear utility function to model risk preferences at the level of individual agents, over the collective and individual reward components of the game. We study the interplay between such preference modelling and environmental uncertainty on the incentive alignment level in the game. We demonstrate how different combinations of individual preferences and environmental uncertainties sustain the emergence of cooperative patterns in non-cooperative environments (i.e., where competitive strategies are dominant), while others sustain competitive patterns in cooperative environments (i.e., where cooperative strategies are dominant).
CausalPlayground: Addressing Data-Generation Requirements in Cutting-Edge Causality Research
May 21, 2024Research on causal effects often relies on synthetic data due to the scarcity of real-world datasets with ground-truth effects. Since current data-generating tools do not always meet all requirements for state-of-the-art research, ad-hoc methods are often employed. This leads to heterogeneity among datasets and delays research progress. We address the shortcomings of current data-generating libraries by introducing CausalPlayground, a Python library that provides a standardized platform for generating, sampling, and sharing structural causal models (SCMs). CausalPlayground offers fine-grained control over SCMs, interventions, and the generation of datasets of SCMs for learning and quantitative research. Furthermore, by integrating with Gymnasium, the standard framework for reinforcement learning (RL) environments, we enable online interaction with the SCMs. Overall, by introducing CausalPlayground we aim to foster more efficient and comparable research in the field. All code and API documentation is available at https://github.com/sa-and/CausalPlayground.