 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning in Speech Language Models: Analyzing the Role of Acoustic Features, Linguistic Structure, and Induction Heads
Apr 07, 2026In-Context Learning (ICL) has been extensively studied in text-only Language Models, but remains largely unexplored in the speech domain. Here, we investigate how linguistic and acoustic features affect ICL in Speech Language Models. We focus on the Text-to-Speech (TTS) task, which allows us to analyze ICL from two angles: (1) how accurately the model infers the task from the demonstrations (i.e., generating the correct spoken content), and (2) to what extent the model mimics the acoustic characteristics of the demonstration speech in its output. We find that speaking rate strongly affects ICL performance and is also mimicked in the output, whereas pitch range and intensity have little impact on performance and are not consistently reproduced. Finally, we investigate the role of induction heads in speech-based ICL and show that these heads play a causal role: ablating the top-k induction heads completely removes the model's ICL ability, mirroring findings from text-based ICL.
Transformer See, Transformer Do: Copying as an Intermediate Step in Learning Analogical Reasoning
Apr 07, 2026Analogical reasoning is a hallmark of human intelligence, enabling us to solve new problems by transferring knowledge from one situation to another. Yet, developing artificial intelligence systems capable of robust human-like analogical reasoning has proven difficult. In this work, we train transformers using Meta-Learning for Compositionality (MLC) on an analogical reasoning task (letter-string analogies) and assess their generalization capabilities. We find that letter-string analogies become learnable when guiding the models to attend to the most informative problem elements induced by including copying tasks in the training data. Furthermore, generalization to new alphabets becomes better when models are trained with more heterogeneous datasets, where our 3-layer encoder-decoder model outperforms most frontier models. The MLC approach also enables some generalization to compositions of trained transformations, but not to completely novel transformations. To understand how the model operates, we identify an algorithm that approximates the model's computations. We verify this using interpretability analyses and show that the model can be steered precisely according to expectations derived from the algorithm. Finally, we discuss implications of our findings for generalization capabilities of larger models and parallels to human analogical reasoning.
Tracking the emergence of linguistic structure in self-supervised models learning from speech
Apr 02, 2026Self-supervised speech models learn effective representations of spoken language, which have been shown to reflect various aspects of linguistic structure. But when does such structure emerge in model training? We study the encoding of a wide range of linguistic structures, across layers and intermediate checkpoints of six Wav2Vec2 and HuBERT models trained on spoken Dutch. We find that different levels of linguistic structure show notably distinct layerwise patterns as well as learning trajectories, which can partially be explained by differences in their degree of abstraction from the acoustic signal and the timescale at which information from the input is integrated. Moreover, we find that the level at which pre-training objectives are defined strongly affects both the layerwise organization and the learning trajectories of linguistic structures, with greater parallelism induced by higher-order prediction tasks (i.e. iteratively refined pseudo-labels).
Linguists should learn to love speech-based deep learning models
Dec 16, 2025Futrell and Mahowald present a useful framework bridging technology-oriented deep learning systems and explanation-oriented linguistic theories. Unfortunately, the target article's focus on generative text-based LLMs fundamentally limits fruitful interactions with linguistics, as many interesting questions on human language fall outside what is captured by written text. We argue that audio-based deep learning models can and should play a crucial role.
The Curious Case of Visual Grounding: Different Effects for Speech- and Text-based Language Encoders
Sep 19, 2025



How does visual information included in training affect language processing in audio- and text-based deep learning models? We explore how such visual grounding affects model-internal representations of words, and find substantially different effects in speech- vs. text-based language encoders. Firstly, global representational comparisons reveal that visual grounding increases alignment between representations of spoken and written language, but this effect seems mainly driven by enhanced encoding of word identity rather than meaning. We then apply targeted clustering analyses to probe for phonetic vs. semantic discriminability in model representations. Speech-based representations remain phonetically dominated with visual grounding, but in contrast to text-based representations, visual grounding does not improve semantic discriminability. Our findings could usefully inform the development of more efficient methods to enrich speech-based models with visually-informed semantics.
Propositional Logic for Probing Generalization in Neural Networks
Jun 10, 2025
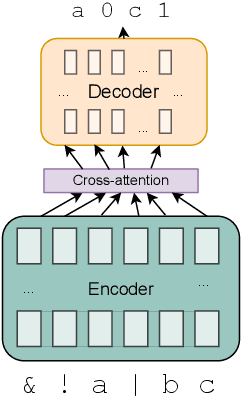
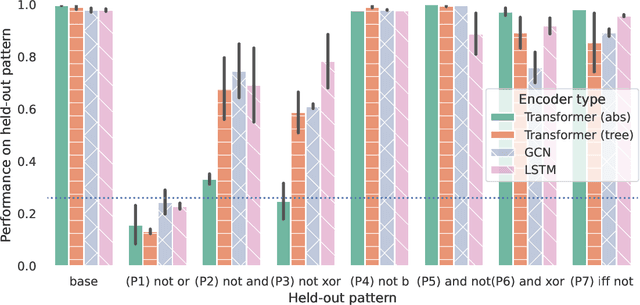
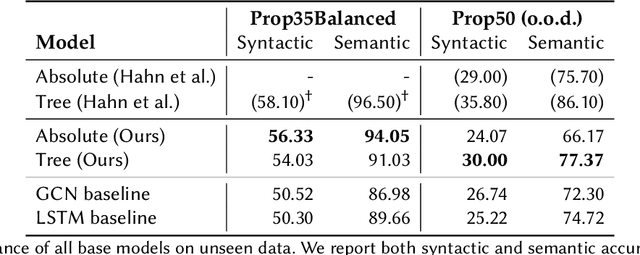
The extent to which neural networks are able to acquire and represent symbolic rules remains a key topic of research and debate. Much current work focuses on the impressive capabilities of large language models, as well as their often ill-understood failures on a wide range of reasoning tasks. In this paper, in contrast, we investigate the generalization behavior of three key neural architectures (Transformers, Graph Convolution Networks and LSTMs) in a controlled task rooted in propositional logic. The task requires models to generate satisfying assignments for logical formulas, making it a structured and interpretable setting for studying compositionality. We introduce a balanced extension of an existing dataset to eliminate superficial patterns and enable testing on unseen operator combinations. Using this dataset, we evaluate the ability of the three architectures to generalize beyond the training distribution. While all models perform well in-distribution, we find that generalization to unseen patterns, particularly those involving negation, remains a significant challenge. Transformers fail to apply negation compositionally, unless structural biases are introduced. Our findings highlight persistent limitations in the ability of standard architectures to learn systematic representations of logical operators, suggesting the need for stronger inductive biases to support robust rule-based reasoning.
A Linguistically Motivated Analysis of Intonational Phrasing in Text-to-Speech Systems: Revealing Gaps in Syntactic Sensitivity
May 28, 2025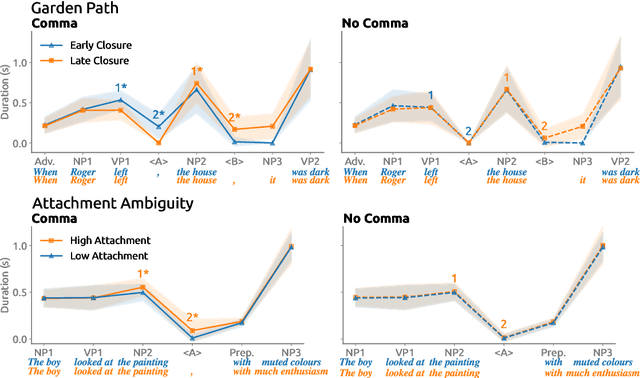
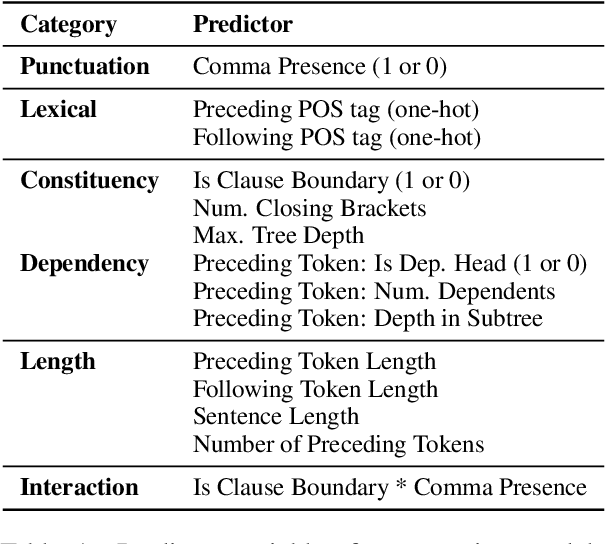
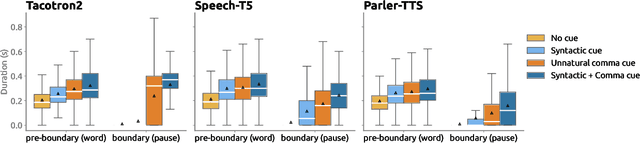

We analyze the syntactic sensitivity of Text-to-Speech (TTS) systems using methods inspired by psycholinguistic research. Specifically, we focus on the generation of intonational phrase boundaries, which can often be predicted by identifying syntactic boundaries within a sentence. We find that TTS systems struggle to accurately generate intonational phrase boundaries in sentences where syntactic boundaries are ambiguous (e.g., garden path sentences or sentences with attachment ambiguity). In these cases, systems need superficial cues such as commas to place boundaries at the correct positions. In contrast, for sentences with simpler syntactic structures, we find that systems do incorporate syntactic cues beyond surface markers. Finally, we finetune models on sentences without commas at the syntactic boundary positions, encouraging them to focus on more subtle linguistic cues. Our findings indicate that this leads to more distinct intonation patterns that better reflect the underlying structure.
PolyPythias: Stability and Outliers across Fifty Language Model Pre-Training Runs
Mar 12, 2025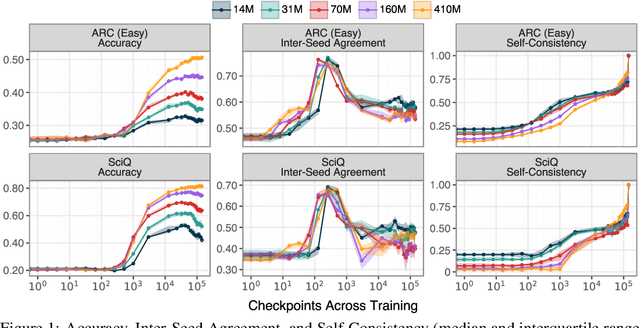

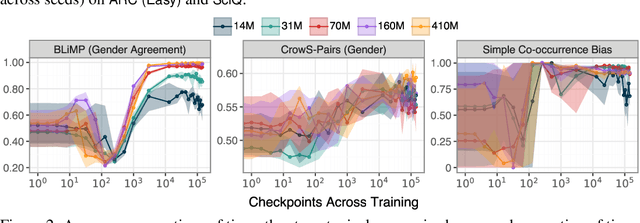
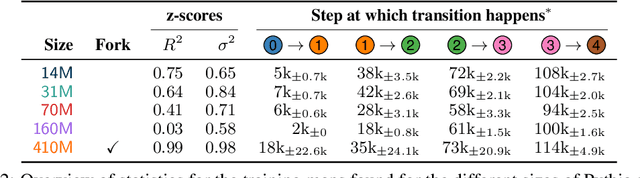
The stability of language model pre-training and its effects on downstream performance are still understudied. Prior work shows that the training process can yield significantly different results in response to slight variations in initial conditions, e.g., the random seed. Crucially, the research community still lacks sufficient resources and tools to systematically investigate pre-training stability, particularly for decoder-only language models. We introduce the PolyPythias, a set of 45 new training runs for the Pythia model suite: 9 new seeds across 5 model sizes, from 14M to 410M parameters, resulting in about 7k new checkpoints that we release. Using these new 45 training runs, in addition to the 5 already available, we study the effects of different initial conditions determined by the seed -- i.e., parameters' initialisation and data order -- on (i) downstream performance, (ii) learned linguistic representations, and (iii) emergence of training phases. In addition to common scaling behaviours, our analyses generally reveal highly consistent training dynamics across both model sizes and initial conditions. Further, the new seeds for each model allow us to identify outlier training runs and delineate their characteristics. Our findings show the potential of using these methods to predict training stability.
Enforcing Interpretability in Time Series Transformers: A Concept Bottleneck Framework
Oct 08, 2024



There has been a recent push of research on Transformer-based models for long-term time series forecasting, even though they are inherently difficult to interpret and explain. While there is a large body of work on interpretability methods for various domains and architectures, the interpretability of Transformer-based forecasting models remains largely unexplored. To address this gap, we develop a framework based on Concept Bottleneck Models to enforce interpretability of time series Transformers. We modify the training objective to encourage a model to develop representations similar to predefined interpretable concepts. In our experiments, we enforce similarity using Centered Kernel Alignment, and the predefined concepts include time features and an interpretable, autoregressive surrogate model (AR). We apply the framework to the Autoformer model, and present an in-depth analysis for a variety of benchmark tasks. We find that the model performance remains mostly unaffected, while the model shows much improved interpretability. Additionally, interpretable concepts become local, which makes the trained model easily intervenable. As a proof of concept, we demonstrate a successful intervention in the scenario of a time shift in the data, which eliminates the need to retrain.
Disentangling Textual and Acoustic Features of Neural Speech Representations
Oct 03, 2024



Neural speech models build deeply entangled internal representations, which capture a variety of features (e.g., fundamental frequency, loudness, syntactic category, or semantic content of a word) in a distributed encoding. This complexity makes it difficult to track the extent to which such representations rely on textual and acoustic information, or to suppress the encoding of acoustic features that may pose privacy risks (e.g., gender or speaker identity) in critical, real-world applications. In this paper, we build upon the Information Bottleneck principle to propose a disentanglement framework that separates complex speech representations into two distinct components: one encoding content (i.e., what can be transcribed as text) and the other encoding acoustic features relevant to a given downstream task. We apply and evaluate our framework to emotion recognition and speaker identification downstream tasks, quantifying the contribution of textual and acoustic features at each model layer. Additionally, we explore the application of our disentanglement framework as an attribution method to identify the most salient speech frame representations from both the textual and acoustic perspectives.