 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropositional Logic for Probing Generalization in Neural Networks
Jun 10, 2025
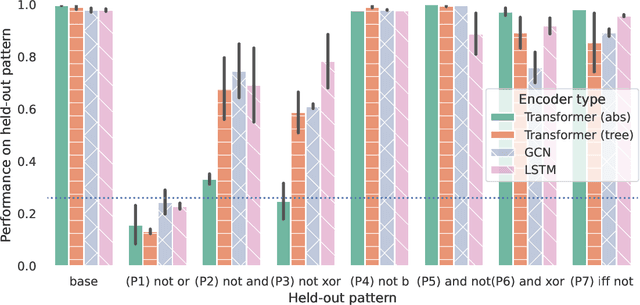
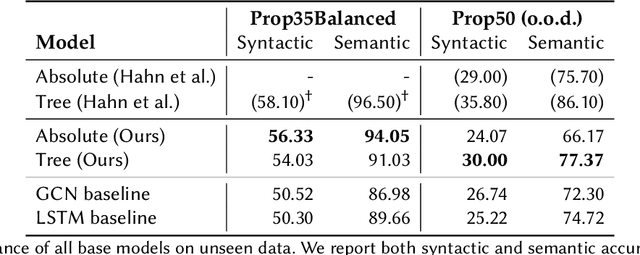
The extent to which neural networks are able to acquire and represent symbolic rules remains a key topic of research and debate. Much current work focuses on the impressive capabilities of large language models, as well as their often ill-understood failures on a wide range of reasoning tasks. In this paper, in contrast, we investigate the generalization behavior of three key neural architectures (Transformers, Graph Convolution Networks and LSTMs) in a controlled task rooted in propositional logic. The task requires models to generate satisfying assignments for logical formulas, making it a structured and interpretable setting for studying compositionality. We introduce a balanced extension of an existing dataset to eliminate superficial patterns and enable testing on unseen operator combinations. Using this dataset, we evaluate the ability of the three architectures to generalize beyond the training distribution. While all models perform well in-distribution, we find that generalization to unseen patterns, particularly those involving negation, remains a significant challenge. Transformers fail to apply negation compositionally, unless structural biases are introduced. Our findings highlight persistent limitations in the ability of standard architectures to learn systematic representations of logical operators, suggesting the need for stronger inductive biases to support robust rule-based reasoning.
ChapGTP, ILLC's Attempt at Raising a BabyLM: Improving Data Efficiency by Automatic Task Formation
Oct 17, 2023


We present the submission of the ILLC at the University of Amsterdam to the BabyLM challenge (Warstadt et al., 2023), in the strict-small track. Our final model, ChapGTP, is a masked language model that was trained for 200 epochs, aided by a novel data augmentation technique called Automatic Task Formation. We discuss in detail the performance of this model on the three evaluation suites: BLiMP, (Super)GLUE, and MSGS. Furthermore, we present a wide range of methods that were ultimately not included in the model, but may serve as inspiration for training LMs in low-resource settings.
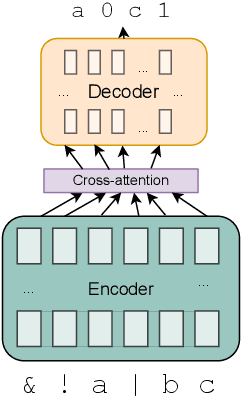
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
Oct 05, 2023



In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.
Meta-learning for fast cross-lingual adaptation in dependency parsing
Apr 13, 2021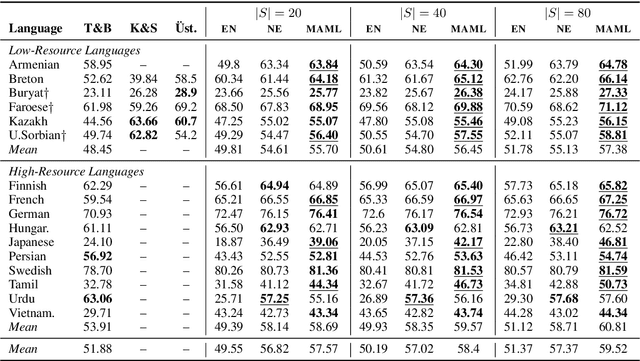
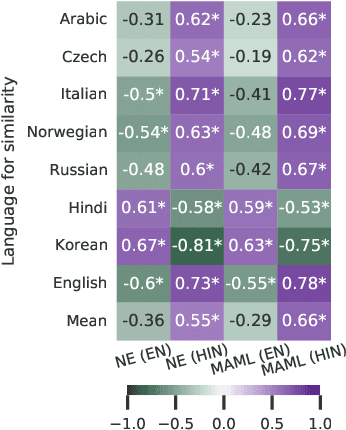
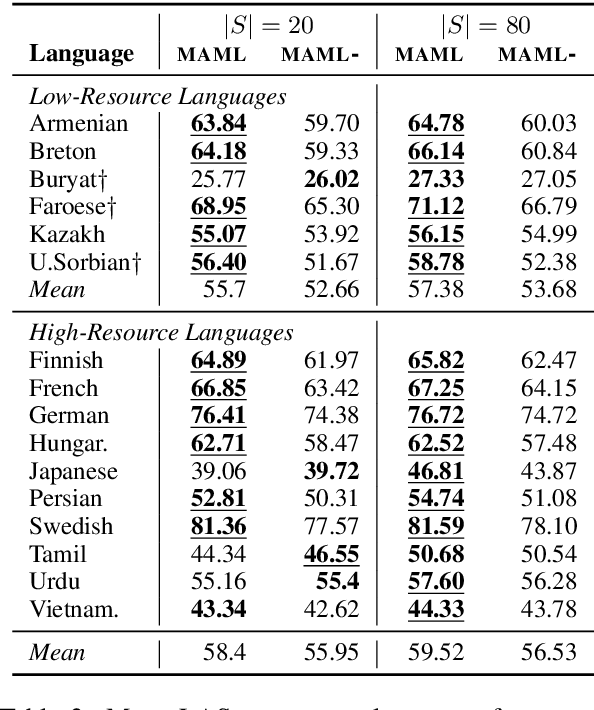
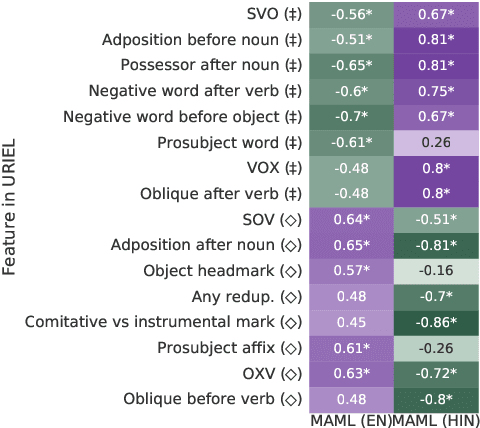
Meta-learning, or learning to learn, is a technique that can help to overcome resource scarcity in cross-lingual NLP problems, by enabling fast adaptation to new tasks. We apply model-agnostic meta-learning (MAML) to the task of cross-lingual dependency parsing. We train our model on a diverse set of languages to learn a parameter initialization that can adapt quickly to new languages. We find that meta-learning with pre-training can significantly improve upon the performance of language transfer and standard supervised learning baselines for a variety of unseen, typologically diverse, and low-resource languages, in a few-shot learning setup.