 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of Typological Features on Multilingual Machine Translation in the Age of Large Language Models
Feb 03, 2026Despite major advances in multilingual modeling, large quality disparities persist across languages. Besides the obvious impact of uneven training resources, typological properties have also been proposed to determine the intrinsic difficulty of modeling a language. The existing evidence, however, is mostly based on small monolingual language models or bilingual translation models trained from scratch. We expand on this line of work by analyzing two large pre-trained multilingual translation models, NLLB-200 and Tower+, which are state-of-the-art representatives of encoder-decoder and decoder-only machine translation, respectively. Based on a broad set of languages, we find that target language typology drives translation quality of both models, even after controlling for more trivial factors, such as data resourcedness and writing script. Additionally, languages with certain typological properties benefit more from a wider search of the output space, suggesting that such languages could profit from alternative decoding strategies beyond the standard left-to-right beam search. To facilitate further research in this area, we release a set of fine-grained typological properties for 212 languages of the FLORES+ MT evaluation benchmark.
TurBLiMP: A Turkish Benchmark of Linguistic Minimal Pairs
Jun 16, 2025We introduce TurBLiMP, the first Turkish benchmark of linguistic minimal pairs, designed to evaluate the linguistic abilities of monolingual and multilingual language models (LMs). Covering 16 linguistic phenomena with 1000 minimal pairs each, TurBLiMP fills an important gap in linguistic evaluation resources for Turkish. In designing the benchmark, we give extra attention to two properties of Turkish that remain understudied in current syntactic evaluations of LMs, namely word order flexibility and subordination through morphological processes. Our experiments on a wide range of LMs and a newly collected set of human acceptability judgments reveal that even cutting-edge Large LMs still struggle with grammatical phenomena that are not challenging for humans, and may also exhibit different sensitivities to word order and morphological complexity compared to humans.
Propositional Logic for Probing Generalization in Neural Networks
Jun 10, 2025
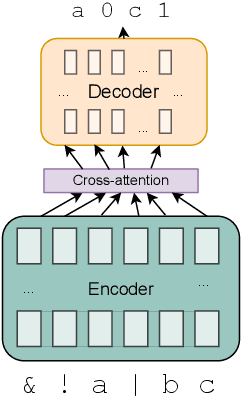
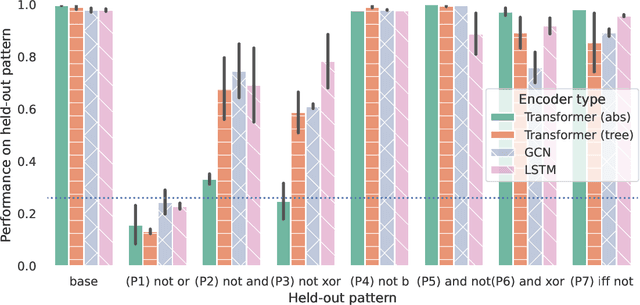
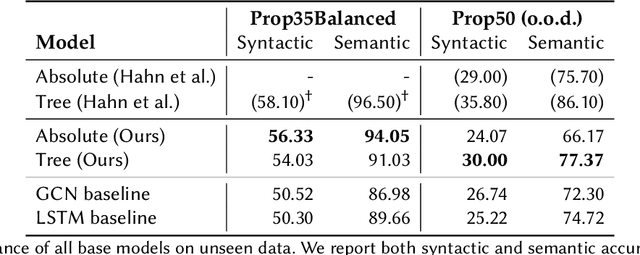
The extent to which neural networks are able to acquire and represent symbolic rules remains a key topic of research and debate. Much current work focuses on the impressive capabilities of large language models, as well as their often ill-understood failures on a wide range of reasoning tasks. In this paper, in contrast, we investigate the generalization behavior of three key neural architectures (Transformers, Graph Convolution Networks and LSTMs) in a controlled task rooted in propositional logic. The task requires models to generate satisfying assignments for logical formulas, making it a structured and interpretable setting for studying compositionality. We introduce a balanced extension of an existing dataset to eliminate superficial patterns and enable testing on unseen operator combinations. Using this dataset, we evaluate the ability of the three architectures to generalize beyond the training distribution. While all models perform well in-distribution, we find that generalization to unseen patterns, particularly those involving negation, remains a significant challenge. Transformers fail to apply negation compositionally, unless structural biases are introduced. Our findings highlight persistent limitations in the ability of standard architectures to learn systematic representations of logical operators, suggesting the need for stronger inductive biases to support robust rule-based reasoning.
Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
May 29, 2025Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of adult-directed written text, suggesting that CDL could provide more effective LM training material than the commonly used internet-crawled data. However, the generalizability of these results across languages, model types, and evaluation settings remains unclear. We test this by comparing models trained on CDL vs. Wikipedia across two LM objectives (masked and causal), three languages (English, French, German), and three syntactic minimal-pair benchmarks. Our results on these benchmarks show inconsistent benefits of CDL, which in most cases is outperformed by Wikipedia models. We then identify various shortcomings in previous benchmarks, and introduce a novel testing methodology, FIT-CLAMS, which uses a frequency-controlled design to enable balanced comparisons across training corpora. Through minimal pair evaluations and regression analysis we show that training on CDL does not yield stronger generalizations for acquiring syntax and highlight the importance of controlling for frequency effects when evaluating syntactic ability.
MultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs
Apr 03, 2025We introduce MultiBLiMP 1.0, a massively multilingual benchmark of linguistic minimal pairs, covering 101 languages, 6 linguistic phenomena and containing more than 125,000 minimal pairs. Our minimal pairs are created using a fully automated pipeline, leveraging the large-scale linguistic resources of Universal Dependencies and UniMorph. MultiBLiMP 1.0 evaluates abilities of LLMs at an unprecedented multilingual scale, and highlights the shortcomings of the current state-of-the-art in modelling low-resource languages.
Finding Structure in Language Models
Nov 25, 2024



When we speak, write or listen, we continuously make predictions based on our knowledge of a language's grammar. Remarkably, children acquire this grammatical knowledge within just a few years, enabling them to understand and generalise to novel constructions that have never been uttered before. Language models are powerful tools that create representations of language by incrementally predicting the next word in a sentence, and they have had a tremendous societal impact in recent years. The central research question of this thesis is whether these models possess a deep understanding of grammatical structure similar to that of humans. This question lies at the intersection of natural language processing, linguistics, and interpretability. To address it, we will develop novel interpretability techniques that enhance our understanding of the complex nature of large-scale language models. We approach our research question from three directions. First, we explore the presence of abstract linguistic information through structural priming, a key paradigm in psycholinguistics for uncovering grammatical structure in human language processing. Next, we examine various linguistic phenomena, such as adjective order and negative polarity items, and connect a model's comprehension of these phenomena to the data distribution on which it was trained. Finally, we introduce a controlled testbed for studying hierarchical structure in language models using various synthetic languages of increasing complexity and examine the role of feature interactions in modelling this structure. Our findings offer a detailed account of the grammatical knowledge embedded in language model representations and provide several directions for investigating fundamental linguistic questions using computational methods.
Black Big Boxes: Do Language Models Hide a Theory of Adjective Order?
Jul 02, 2024



In English and other languages, multiple adjectives in a complex noun phrase show intricate ordering patterns that have been a target of much linguistic theory. These patterns offer an opportunity to assess the ability of language models (LMs) to learn subtle rules of language involving factors that cross the traditional divisions of syntax, semantics, and pragmatics. We review existing hypotheses designed to explain Adjective Order Preferences (AOPs) in humans and develop a setup to study AOPs in LMs: we present a reusable corpus of adjective pairs and define AOP measures for LMs. With these tools, we study a series of LMs across intermediate checkpoints during training. We find that all models' predictions are much closer to human AOPs than predictions generated by factors identified in theoretical linguistics. At the same time, we demonstrate that the observed AOPs in LMs are strongly correlated with the frequency of the adjective pairs in the training data and report limited generalization to unseen combinations. This highlights the difficulty in establishing the link between LM performance and linguistic theory. We therefore conclude with a road map for future studies our results set the stage for, and a discussion of key questions about the nature of knowledge in LMs and their ability to generalize beyond the training sets.
Interpretability of Language Models via Task Spaces
Jun 10, 2024



The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
Do Language Models Exhibit Human-like Structural Priming Effects?
Jun 07, 2024



We explore which linguistic factors -- at the sentence and token level -- play an important role in influencing language model predictions, and investigate whether these are reflective of results found in humans and human corpora (Gries and Kootstra, 2017). We make use of the structural priming paradigm, where recent exposure to a structure facilitates processing of the same structure. We don't only investigate whether, but also where priming effects occur, and what factors predict them. We show that these effects can be explained via the inverse frequency effect, known in human priming, where rarer elements within a prime increase priming effects, as well as lexical dependence between prime and target. Our results provide an important piece in the puzzle of understanding how properties within their context affect structural prediction in language models.
Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
May 24, 2024This paper introduces Filtered Corpus Training, a method that trains language models (LMs) on corpora with certain linguistic constructions filtered out from the training data, and uses it to measure the ability of LMs to perform linguistic generalization on the basis of indirect evidence. We apply the method to both LSTM and Transformer LMs (of roughly comparable size), developing filtered corpora that target a wide range of linguistic phenomena. Our results show that while transformers are better qua LMs (as measured by perplexity), both models perform equally and surprisingly well on linguistic generalization measures, suggesting that they are capable of generalizing from indirect evidence.