 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferences in Typological Alignment in Language Models' Treatment of Differential Argument Marking
Feb 19, 2026Recent work has shown that language models (LMs) trained on synthetic corpora can exhibit typological preferences that resemble cross-linguistic regularities in human languages, particularly for syntactic phenomena such as word order. In this paper, we extend this paradigm to differential argument marking (DAM), a semantic licensing system in which morphological marking depends on semantic prominence. Using a controlled synthetic learning method, we train GPT-2 models on 18 corpora implementing distinct DAM systems and evaluate their generalization using minimal pairs. Our results reveal a dissociation between two typological dimensions of DAM. Models reliably exhibit human-like preferences for natural markedness direction, favoring systems in which overt marking targets semantically atypical arguments. In contrast, models do not reproduce the strong object preference in human languages, in which overt marking in DAM more often targets objects rather than subjects. These findings suggest that different typological tendencies may arise from distinct underlying sources.
When Efficient Communication Explains Convexity
Feb 02, 2026Much recent work has argued that the variation in the languages of the world can be explained from the perspective of efficient communication; in particular, languages can be seen as optimally balancing competing pressures to be simple and to be informative. Focusing on the expression of meaning -- semantic typology -- the present paper asks what factors are responsible for successful explanations in terms of efficient communication. Using the Information Bottleneck (IB) approach to formalizing this trade-off, we first demonstrate and analyze a correlation between optimality in the IB sense and a novel generalization of convexity to this setting. In a second experiment, we manipulate various modeling parameters in the IB framework to determine which factors drive the correlation between convexity and optimality. We find that the convexity of the communicative need distribution plays an especially important role. These results move beyond showing that efficient communication can explain aspects of semantic typology into explanations for why that is the case by identifying which underlying factors are responsible.
Minimization of Boolean Complexity in In-Context Concept Learning
Dec 03, 2024
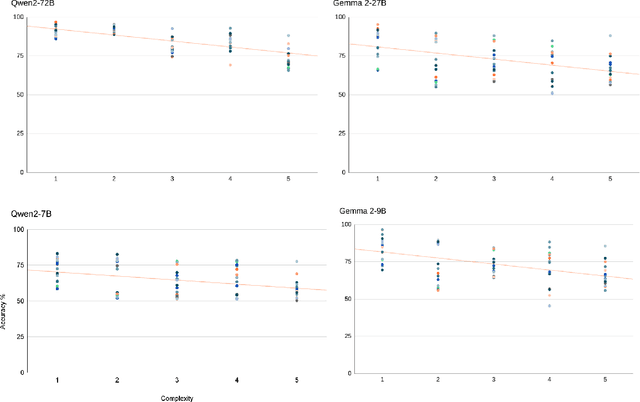

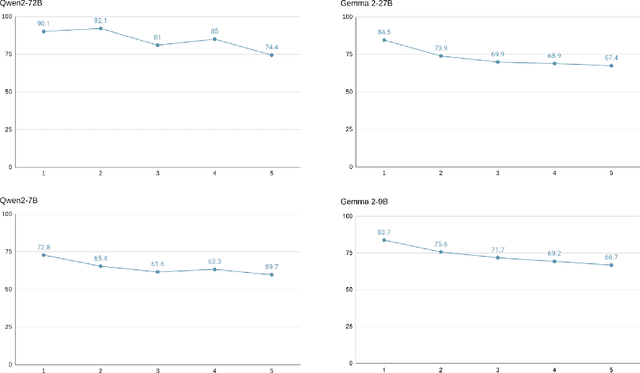
What factors contribute to the relative success and corresponding difficulties of in-context learning for Large Language Models (LLMs)? Drawing on insights from the literature on human concept learning, we test LLMs on carefully designed concept learning tasks, and show that task performance highly correlates with the Boolean complexity of the concept. This suggests that in-context learning exhibits a learning bias for simplicity in a way similar to humans.
Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
May 24, 2024This paper introduces Filtered Corpus Training, a method that trains language models (LMs) on corpora with certain linguistic constructions filtered out from the training data, and uses it to measure the ability of LMs to perform linguistic generalization on the basis of indirect evidence. We apply the method to both LSTM and Transformer LMs (of roughly comparable size), developing filtered corpora that target a wide range of linguistic phenomena. Our results show that while transformers are better qua LMs (as measured by perplexity), both models perform equally and surprisingly well on linguistic generalization measures, suggesting that they are capable of generalizing from indirect evidence.
Targeted Multilingual Adaptation for Low-resource Language Families
May 20, 2024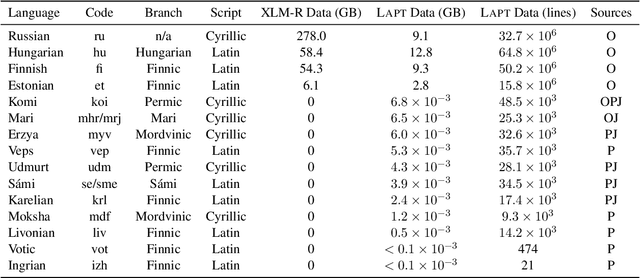
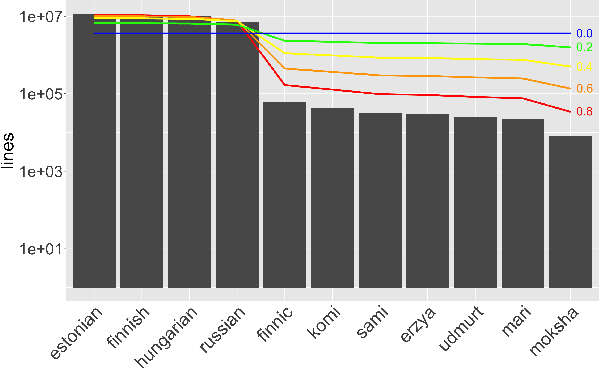
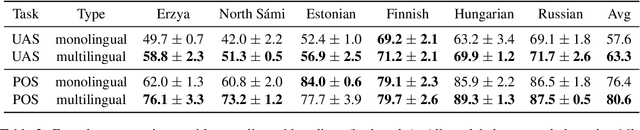
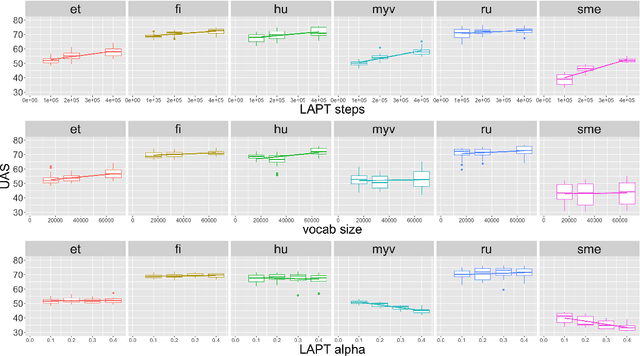
The "massively-multilingual" training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
The Impact of Syntactic and Semantic Proximity on Machine Translation with Back-Translation
Mar 26, 2024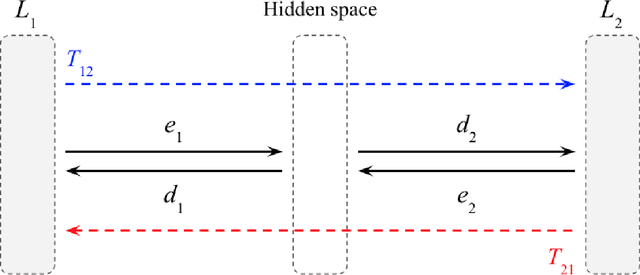

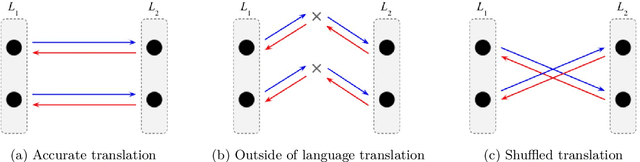

Unsupervised on-the-fly back-translation, in conjunction with multilingual pretraining, is the dominant method for unsupervised neural machine translation. Theoretically, however, the method should not work in general. We therefore conduct controlled experiments with artificial languages to determine what properties of languages make back-translation an effective training method, covering lexical, syntactic, and semantic properties. We find, contrary to popular belief, that (i) parallel word frequency distributions, (ii) partially shared vocabulary, and (iii) similar syntactic structure across languages are not sufficient to explain the success of back-translation. We show however that even crude semantic signal (similar lexical fields across languages) does improve alignment of two languages through back-translation. We conjecture that rich semantic dependencies, parallel across languages, are at the root of the success of unsupervised methods based on back-translation. Overall, the success of unsupervised machine translation was far from being analytically guaranteed. Instead, it is another proof that languages of the world share deep similarities, and we hope to show how to identify which of these similarities can serve the development of unsupervised, cross-linguistic tools.
Embedding structure matters: Comparing methods to adapt multilingual vocabularies to new languages
Sep 09, 2023



Pre-trained multilingual language models underpin a large portion of modern NLP tools outside of English. A strong baseline for specializing these models for specific languages is Language-Adaptive Pre-Training (LAPT). However, retaining a large cross-lingual vocabulary and embedding matrix comes at considerable excess computational cost during adaptation. In this study, we propose several simple techniques to replace a cross-lingual vocabulary with a compact, language-specific one. Namely, we address strategies for re-initializing the token embedding matrix after vocabulary specialization. We then provide a systematic experimental comparison of our techniques, in addition to the recently-proposed Focus method. We demonstrate that: 1) Embedding-replacement techniques in the monolingual transfer literature are inadequate for adapting multilingual models. 2) Replacing cross-lingual vocabularies with smaller specialized ones provides an efficient method to improve performance in low-resource languages. 3) Simple embedding re-initialization techniques based on script-wise sub-distributions rival techniques such as Focus, which rely on similarity scores obtained from an auxiliary model.
Evaluating Transformer's Ability to Learn Mildly Context-Sensitive Languages
Sep 02, 2023Despite that Transformers perform well in NLP tasks, recent studies suggest that self-attention is theoretically limited in learning even some regular and context-free languages. These findings motivated us to think about their implications in modeling natural language, which is hypothesized to be mildly context-sensitive. We test Transformer's ability to learn a variety of mildly context-sensitive languages of varying complexities, and find that they generalize well to unseen in-distribution data, but their ability to extrapolate to longer strings is worse than that of LSTMs. Our analyses show that the learned self-attention patterns and representations modeled dependency relations and demonstrated counting behavior, which may have helped the models solve the languages.
The Weighted Möbius Score: A Unified Framework for Feature Attribution
May 16, 2023Feature attribution aims to explain the reasoning behind a black-box model's prediction by identifying the impact of each feature on the prediction. Recent work has extended feature attribution to interactions between multiple features. However, the lack of a unified framework has led to a proliferation of methods that are often not directly comparable. This paper introduces a parameterized attribution framework -- the Weighted M\"obius Score -- and (i) shows that many different attribution methods for both individual features and feature interactions are special cases and (ii) identifies some new methods. By studying the vector space of attribution methods, our framework utilizes standard linear algebra tools and provides interpretations in various fields, including cooperative game theory and causal mediation analysis. We empirically demonstrate the framework's versatility and effectiveness by applying these attribution methods to feature interactions in sentiment analysis and chain-of-thought prompting.
Probing for Understanding of English Verb Classes and Alternations in Large Pre-trained Language Models
Sep 11, 2022
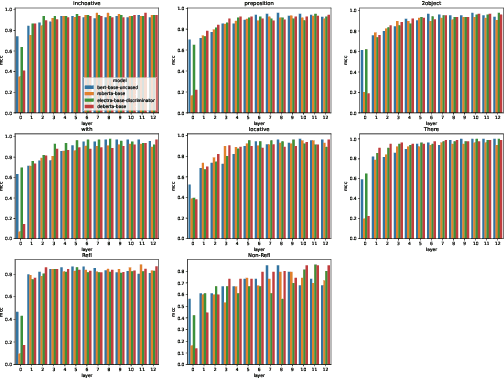
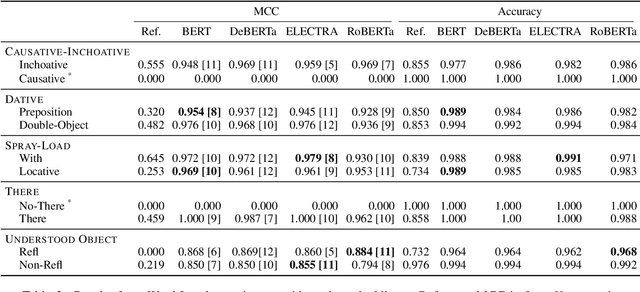
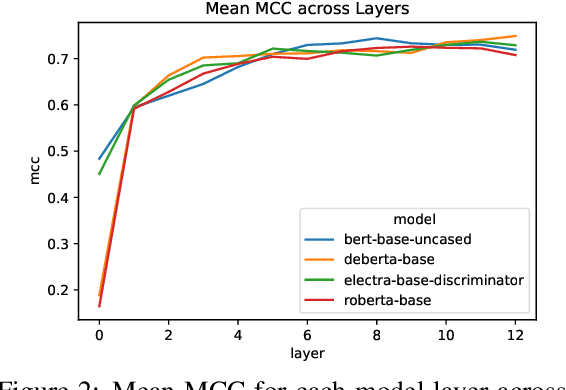
We investigate the extent to which verb alternation classes, as described by Levin (1993), are encoded in the embeddings of Large Pre-trained Language Models (PLMs) such as BERT, RoBERTa, ELECTRA, and DeBERTa using selectively constructed diagnostic classifiers for word and sentence-level prediction tasks. We follow and expand upon the experiments of Kann et al. (2019), which aim to probe whether static embeddings encode frame-selectional properties of verbs. At both the word and sentence level, we find that contextual embeddings from PLMs not only outperform non-contextual embeddings, but achieve astonishingly high accuracies on tasks across most alternation classes. Additionally, we find evidence that the middle-to-upper layers of PLMs achieve better performance on average than the lower layers across all probing tasks.