 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimization of Boolean Complexity in In-Context Concept Learning
Dec 03, 2024
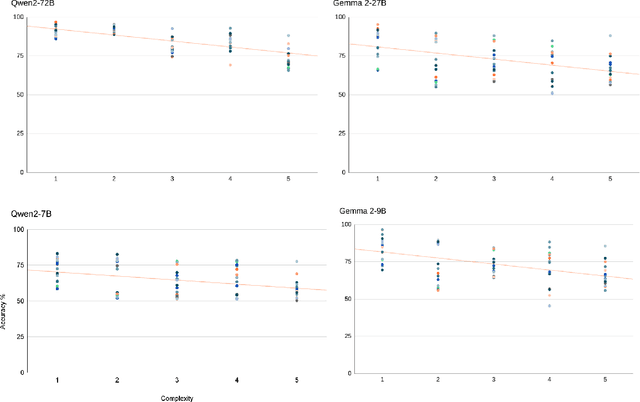

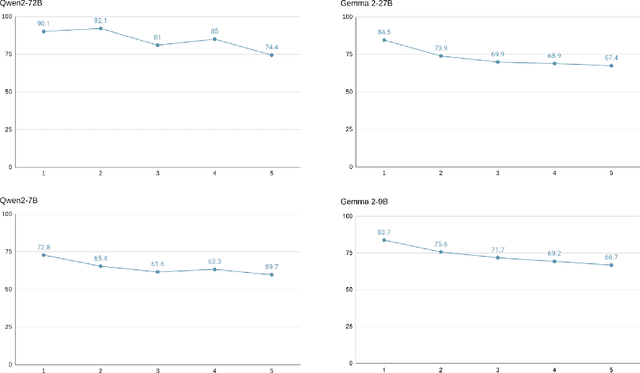
What factors contribute to the relative success and corresponding difficulties of in-context learning for Large Language Models (LLMs)? Drawing on insights from the literature on human concept learning, we test LLMs on carefully designed concept learning tasks, and show that task performance highly correlates with the Boolean complexity of the concept. This suggests that in-context learning exhibits a learning bias for simplicity in a way similar to humans.
Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection
Jan 26, 2022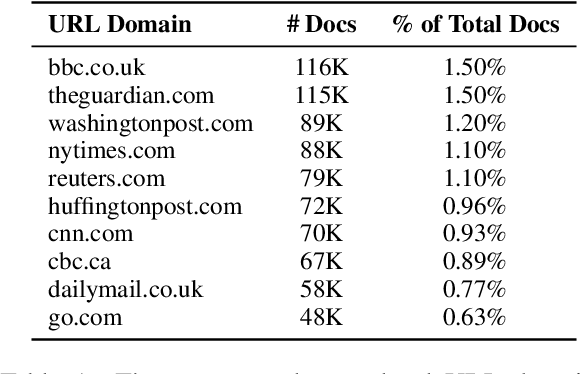
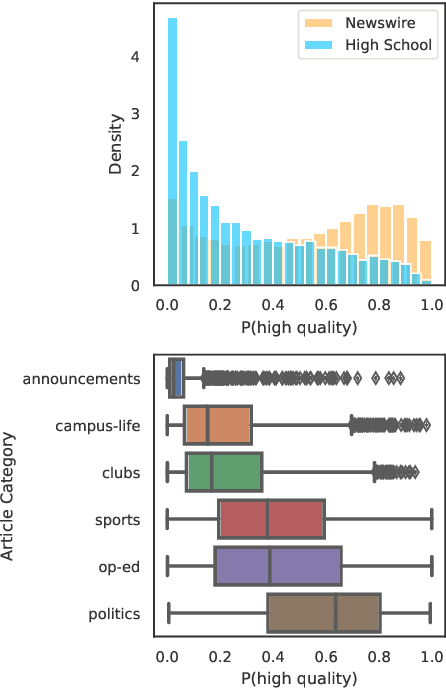
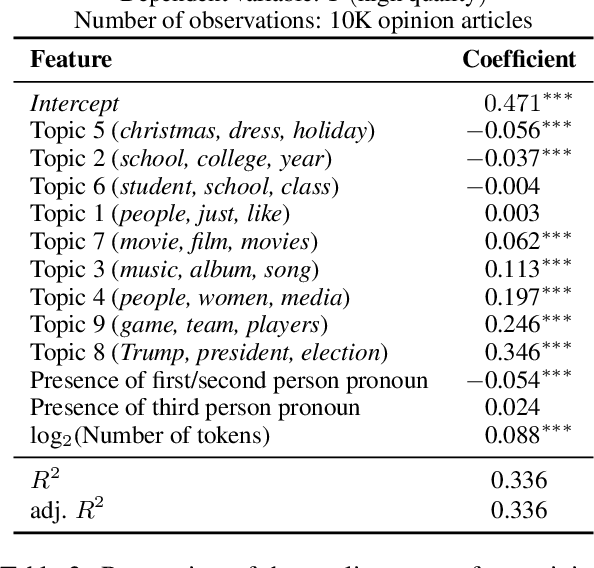
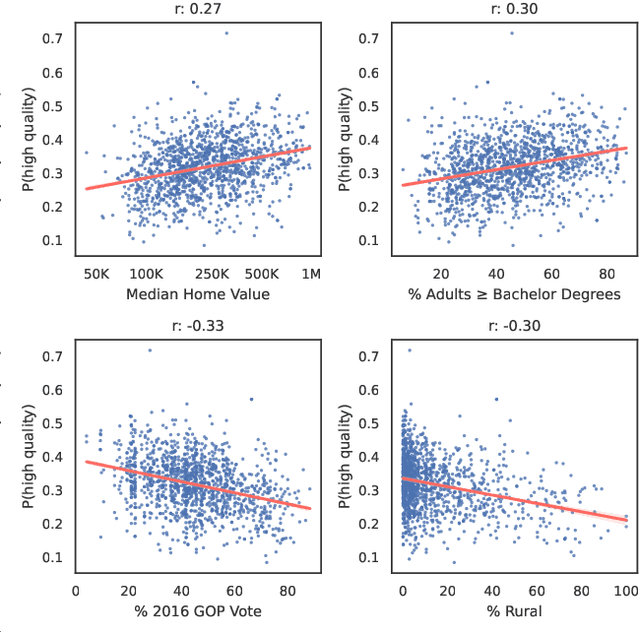
Language models increasingly rely on massive web dumps for diverse text data. However, these sources are rife with undesirable content. As such, resources like Wikipedia, books, and newswire often serve as anchors for automatically selecting web text most suitable for language modeling, a process typically referred to as quality filtering. Using a new dataset of U.S. high school newspaper articles -- written by students from across the country -- we investigate whose language is preferred by the quality filter used for GPT-3. We find that newspapers from larger schools, located in wealthier, educated, and urban ZIP codes are more likely to be classified as high quality. We then demonstrate that the filter's measurement of quality is unaligned with other sensible metrics, such as factuality or literary acclaim. We argue that privileging any corpus as high quality entails a language ideology, and more care is needed to construct training corpora for language models, with better transparency and justification for the inclusion or exclusion of various texts.