 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubato: Transcribing Piano Music with Timestamps
May 22, 2026We consider the conversion of musical recordings into human-readable sheet music annotated with timestamps. Such output lets a listener clearly visualize rubato (temporally expressive playing), a learner diagnose ensemble precision and timing choices against the written music, and a musicology scholar compare performance styles across recordings of the same work. We introduce (1) a prompt-conditioned encoder-decoder model, named Rubato, trained to output (2) a new textual representation for polyphonic music, named InterMo, which we designed for compatibility with sequence-to-sequence training. Our experiments demonstrate that Rubato produces timestamped piano sheet music from audio with higher notational accuracy than the best existing approaches, which are based on cascades. We find that even if the cascade is given ground-truth MIDI instead of audio, Rubato performs better, suggesting that the ceiling of existing approaches is primarily representational, not acoustic. Further, because Rubato is trained on several related tasks (with prompts), it competes with or outperforms the best single-task systems on related but simpler tasks like MIDI note grounding and beat/downbeat detection. A demo is available at https://nctamer.github.io/rubato-transcription .
Train Separately, Merge Together: Modular Post-Training with Mixture-of-Experts
Apr 20, 2026Extending a fully post-trained language model with new domain capabilities is fundamentally limited by monolithic training paradigms: retraining from scratch is expensive and scales poorly, while continued training often degrades existing capabilities. We present BAR (Branch-Adapt-Route), which trains independent domain experts, each through its own mid-training, supervised finetuning, and reinforcement learning pipeline, and composes them via a Mixture-of-Experts architecture with lightweight router training. Unlike retraining approaches that mix all domains and require full reprocessing for any update (with cost scaling quadratically), BAR enables updating individual experts independently with linear cost scaling and no degradation to existing domains. At the 7B scale, with experts for math, code, tool use, and safety, BAR achieves an overall score of 49.1 (averaged across 7 evaluation categories), matching or exceeding re-training baselines (47.8 without mid-training, 50.5 with). We further show that modular training provides a structural advantage: by isolating each domain, it avoids the catastrophic forgetting that occurs when late-stage RL degrades capabilities from earlier training stages, while significantly reducing the cost and complexity of updating or adding a domain. Together, these results suggest that decoupled, expert-based training is a scalable alternative to monolithic retraining for extending language models.
Olmo Hybrid: From Theory to Practice and Back
Apr 07, 2026Recent work has demonstrated the potential of non-transformer language models, especially linear recurrent neural networks (RNNs) and hybrid models that mix recurrence and attention. Yet there is no consensus on whether the potential benefits of these new architectures justify the risk and effort of scaling them up. To address this, we provide evidence for the advantages of hybrid models over pure transformers on several fronts. First, theoretically, we show that hybrid models do not merely inherit the expressivity of transformers and linear RNNs, but can express tasks beyond both, such as code execution. Putting this theory to practice, we train Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B but with the sliding window layers replaced by Gated DeltaNet layers. We show that Olmo Hybrid outperforms Olmo 3 across standard pretraining and mid-training evaluations, demonstrating the benefit of hybrid models in a controlled, large-scale setting. We find that the hybrid model scales significantly more efficiently than the transformer, explaining its higher performance. However, its unclear why greater expressivity on specific formal problems should result in better scaling or superior performance on downstream tasks unrelated to those problems. To explain this apparent gap, we return to theory and argue why increased expressivity should translate to better scaling efficiency, completing the loop. Overall, our results suggest that hybrid models mixing attention and recurrent layers are a powerful extension to the language modeling paradigm: not merely to reduce memory during inference, but as a fundamental way to obtain more expressive models that scale better during pretraining.
Meta-Reinforcement Learning with Self-Reflection for Agentic Search
Mar 11, 2026This paper introduces MR-Search, an in-context meta reinforcement learning (RL) formulation for agentic search with self-reflection. Instead of optimizing a policy within a single independent episode with sparse rewards, MR-Search trains a policy that conditions on past episodes and adapts its search strategy across episodes. MR-Search learns to learn a search strategy with self-reflection, allowing search agents to improve in-context exploration at test-time. Specifically, MR-Search performs cross-episode exploration by generating explicit self-reflections after each episode and leveraging them as additional context to guide subsequent attempts, thereby promoting more effective exploration during test-time. We further introduce a multi-turn RL algorithm that estimates a dense relative advantage at the turn level, enabling fine-grained credit assignment on each episode. Empirical results across various benchmarks demonstrate the advantages of MR-Search over baselines based RL, showing strong generalization and relative improvements of 9.2% to 19.3% across eight benchmarks. Our code and data are available at https://github.com/tengxiao1/MR-Search.
Frame-Level Internal Tool Use for Temporal Grounding in Audio LMs
Feb 10, 2026Large audio language models are increasingly used for complex audio understanding tasks, but they struggle with temporal tasks that require precise temporal grounding, such as word alignment and speaker diarization. The standard approach, where we generate timestamps as sequences of text tokens, is computationally expensive and prone to hallucination, especially when processing audio lengths outside the model's training distribution. In this work, we propose frame-level internal tool use, a method that trains audio LMs to use their own internal audio representations to perform temporal grounding directly. We introduce a lightweight prediction mechanism trained via two objectives: a binary frame classifier and a novel inhomogeneous Poisson process (IHP) loss that models temporal event intensity. Across word localization, speaker diarization, and event localization tasks, our approach outperforms token-based baselines. Most notably, it achieves a >50x inference speedup and demonstrates robust length generalization, maintaining high accuracy on out-of-distribution audio durations where standard token-based models collapse completely.
BASS: Benchmarking Audio LMs for Musical Structure and Semantic Reasoning
Feb 03, 2026Music understanding is a complex task that often requires reasoning over both structural and semantic elements of audio. We introduce BASS, designed to evaluate music understanding and reasoning in audio language models across four broad categories: structural segmentation, lyric transcription, musicological analysis, and artist collaboration. BASS comprises 2658 questions spanning 12 tasks, 1993 unique songs and covering over 138 hours of music from a wide range of genres and tracks, crafted to assess musicological knowledge and reasoning in real-world scenarios. We evaluate 14 open-source and frontier multimodal LMs, finding that even state-of-the-art models struggle on higher-level reasoning tasks such as structural segmentation and artist collaboration, while performing best on lyric transcription. Our analysis reveals that current models leverage linguistic priors effectively but remain limited in reasoning over musical structure, vocal, and musicological attributes. BASS provides an evaluation framework with widespread applications in music recommendation and search and has the potential to guide the development of audio LMs.
Are you going to finish that? A Practical Study of the Tokenization Boundary Problem
Jan 30, 2026Language models (LMs) are trained over sequences of tokens, whereas users interact with LMs via text. This mismatch gives rise to the partial token problem, which occurs when a user ends their prompt in the middle of the expected next-token, leading to distorted next-token predictions. Although this issue has been studied using arbitrary character prefixes, its prevalence and severity in realistic prompts respecting word boundaries remains underexplored. In this work, we identify three domains where token and "word" boundaries often do not line up: languages that do not use whitespace, highly compounding languages, and code. In Chinese, for example, up to 25% of word boundaries do not line up with token boundaries, making even natural, word-complete prompts susceptible to this problem. We systematically construct semantically natural prompts ending with a partial tokens; in experiments, we find that they comprise a serious failure mode: frontier LMs consistently place three orders of magnitude less probability on the correct continuation compared to when the prompt is "backed-off" to be token-aligned. This degradation does not diminish with scale and often worsens for larger models. Finally, we evaluate inference-time mitigations to the partial token problem and validate the effectiveness of recent exact solutions. Overall, we demonstrate the scale and severity of probability distortion caused by tokenization in realistic use cases, and provide practical recommentions for model inference providers.
Bolmo: Byteifying the Next Generation of Language Models
Dec 17, 2025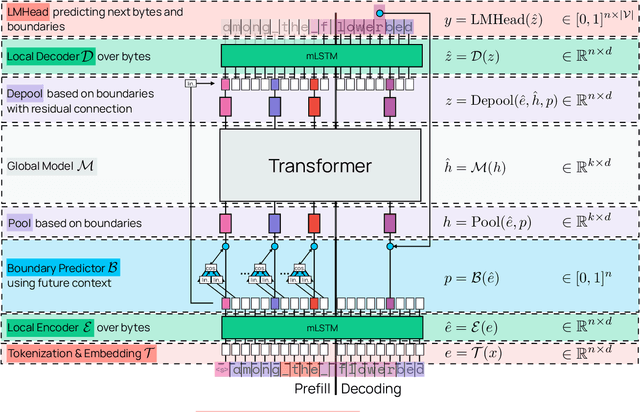
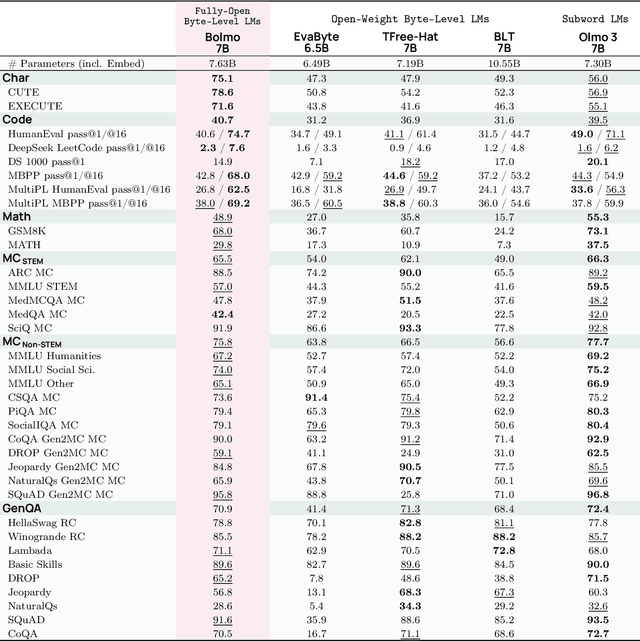
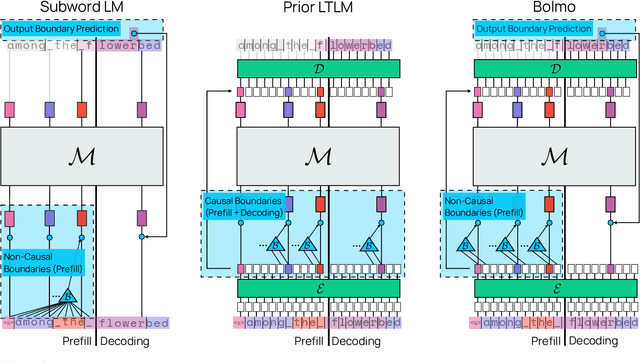
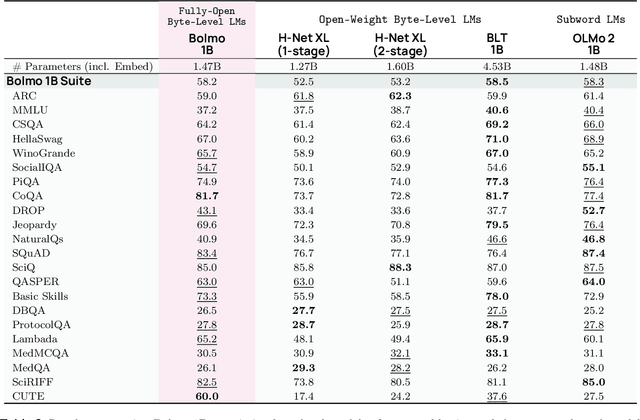
We introduce Bolmo, the first family of competitive fully open byte-level language models (LMs) at the 1B and 7B parameter scales. In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs. Byteification enables overcoming the limitations of subword tokenization - such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary - while performing at the level of leading subword-level LMs. Bolmo is specifically designed for byteification: our architecture resolves a mismatch between the expressivity of prior byte-level architectures and subword-level LMs, which makes it possible to employ an effective exact distillation objective between Bolmo and the source subword model. This allows for converting a subword-level LM to a byte-level LM by investing less than 1\% of a typical pretraining token budget. Bolmo substantially outperforms all prior byte-level LMs of comparable size, and outperforms the source subword-level LMs on character understanding and, in some cases, coding, while coming close to matching the original LMs' performance on other tasks. Furthermore, we show that Bolmo can achieve inference speeds competitive with subword-level LMs by training with higher token compression ratios, and can be cheaply and effectively post-trained by leveraging the existing ecosystem around the source subword-level LM. Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Rewriting History: A Recipe for Interventional Analyses to Study Data Effects on Model Behavior
Oct 16, 2025We present an experimental recipe for studying the relationship between training data and language model (LM) behavior. We outline steps for intervening on data batches -- i.e., ``rewriting history'' -- and then retraining model checkpoints over that data to test hypotheses relating data to behavior. Our recipe breaks down such an intervention into stages that include selecting evaluation items from a benchmark that measures model behavior, matching relevant documents to those items, and modifying those documents before retraining and measuring the effects. We demonstrate the utility of our recipe through case studies on factual knowledge acquisition in LMs, using both cooccurrence statistics and information retrieval methods to identify documents that might contribute to knowledge learning. Our results supplement past observational analyses that link cooccurrence to model behavior, while demonstrating that extant methods for identifying relevant training documents do not fully explain an LM's ability to correctly answer knowledge questions. Overall, we outline a recipe that researchers can follow to test further hypotheses about how training data affects model behavior. Our code is made publicly available to promote future work.