 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything at Every Scale: Scale-Invariant Diffusion with Continuous Super-Resolution
May 25, 2026Creating images from noise is image generation; reconstructing fine details from coarse inputs is super-resolution. Despite their practical differences, both can be understood as reversing information loss across scales. We introduce $\textbf{SKILD}$, a $\textbf{S}$cale-invariant $\textbf{K}$-Space $\textbf{I}$mage $\textbf{L}$earning $\textbf{D}$iffusion model that unifies generation and continuous super-resolution within a single unconditional framework. Both natural images and critical physical systems exhibit scale invariance, and we leverage it to design a forward process that attenuates image content from fine to coarse scales while injecting spectrum-matched Gaussian noise, making scale an explicit coordinate of the diffusion dynamics. The same trained reverse process performs generation and continuous super-resolution by varying only the starting timestep: $\textit{no task-specific architecture, no conditioning branch, no classifier-free guidance, no retraining per scale factor}$. Empirically, SKILD reaches FID $2.65$ and Inception Score $9.63$ on unconditional CIFAR-10, performs $2\times$--$8\times$ super-resolution on ImageNet from a single unconditional checkpoint while outperforming conditional models across perceptual metrics, and reconstructs critical Ising models whose connected four-point correlations closely track the ground truth.
GenMatter: Perceiving Physical Objects with Generative Matter Models
Apr 24, 2026Human visual perception offers valuable insights for understanding computational principles of motion-based scene interpretation. Humans robustly detect and segment moving entities that constitute independently moveable chunks of matter, whether observing sparse moving dots, textured surfaces, or naturalistic scenes. In contrast, existing computer vision systems lack a unified approach that works across these diverse settings. Inspired by principles of human perception, we propose a generative model that hierarchically groups low-level motion cues and high-level appearance features into particles (small Gaussians representing local matter), and groups particles into clusters capturing coherently and independently moveable physical entities. We develop a hardware-accelerated inference algorithm based on parallelized block Gibbs sampling to recover stable particle motion and groupings. Our model operates on different kinds of inputs (random dots, stylized textures, or naturalistic RGB video), enabling it to work across settings where biological vision succeeds but existing computer vision approaches do not. We validate this unified framework across three domains: on 2D random dot kinematograms, our approach captures human object perception including graded uncertainty across ambiguous conditions; on a Gestalt-inspired dataset of camouflaged rotating objects, our approach recovers correct 3D structure from motion and thereby accurate 2D object segmentation; and on naturalistic RGB videos, our model tracks the moving 3D matter that makes up deforming objects, enabling robust object-level scene understanding. This work thus establishes a general framework for motion-based perception grounded in principles of human vision.
MathNet: a Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
Apr 20, 2026Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce MathNet, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models and mathematical retrieval in embedding-based systems. MathNet spans 47 countries, 17 languages, and two decades of competitions, comprising 30,676 expert-authored problems with solutions across diverse domains. In addition to the core dataset, we construct a retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts. MathNet supports three tasks: (i) Problem Solving, (ii) Math-Aware Retrieval, and (iii) Retrieval-Augmented Problem Solving. Experimental results show that even state-of-the-art reasoning models (78.4% for Gemini-3.1-Pro and 69.3% for GPT-5) remain challenged, while embedding models struggle to retrieve equivalent problems. We further show that retrieval-augmented generation performance is highly sensitive to retrieval quality; for example, DeepSeek-V3.2-Speciale achieves gains of up to 12%, obtaining the highest scores on the benchmark. MathNet provides the largest high-quality Olympiad dataset together with the first benchmark for evaluating mathematical problem retrieval, and we publicly release both the dataset and benchmark at https://mathnet.mit.edu.
* ICLR 2026; Website: http://mathnet.mit.edu
Learning What's Real: Disentangling Signal and Measurement Artifacts in Multi-Sensor Data, with Applications to Astrophysics
Apr 10, 2026Data collected from the physical world is always a combination of multiple sources: an underlying signal from the physical process of interest and a signal from measurement-dependent artifacts from the sensor or instrument. This secondary signal acts as a confounding factor, limiting our ability to extract information about the physics underlying the phenomena we observe. Furthermore, it complicates the combination of observations in heterogeneous or multi-instrument settings. We propose a deep learning framework that leverages overlapping observations, a dual-encoder architecture, and a counterfactual generation objective to disentangle these factors of variation. The resulting representations explicitly separate intrinsic signals from sensor-specific distortions and noise, and can be used for counterfactual view generation, parameter inference unconfounded by measurement distortions, and instrument-independent similarity search. We demonstrate the effectiveness of our approach on astrophysical galaxy images from the DESI Legacy Imaging Survey (Legacy) and the Hyper Suprime-Cam (HSC) Survey as a representative multi-instrument setting. This framework provides a general recipe for scientific and multi-modal self-supervised pretraining: construct training pairs from overlapping observations of the same physical system, treat sensor- or modality-specific effects as augmentations, and learn invariant representations through counterfactual generation.
End-to-End Training for Unified Tokenization and Latent Denoising
Mar 23, 2026Latent diffusion models (LDMs) enable high-fidelity synthesis by operating in learned latent spaces. However, training state-of-the-art LDMs requires complex staging: a tokenizer must be trained first, before the diffusion model can be trained in the frozen latent space. We propose UNITE - an autoencoder architecture for unified tokenization and latent diffusion. UNITE consists of a Generative Encoder that serves as both image tokenizer and latent generator via weight sharing. Our key insight is that tokenization and generation can be viewed as the same latent inference problem under different conditioning regimes: tokenization infers latents from fully observed images, whereas generation infers them from noise together with text or class conditioning. Motivated by this, we introduce a single-stage training procedure that jointly optimizes both tasks via two forward passes through the same Generative Encoder. The shared parameters enable gradients to jointly shape the latent space, encouraging a "common latent language". Across image and molecule modalities, UNITE achieves near state of the art performance without adversarial losses or pretrained encoders (e.g., DINO), reaching FID 2.12 and 1.73 for Base and Large models on ImageNet 256 x 256. We further analyze the Generative Encoder through the lenses of representation alignment and compression. These results show that single stage joint training of tokenization & generation from scratch is feasible.
Dynamic Black-hole Emission Tomography with Physics-informed Neural Fields
Feb 08, 2026With the success of static black-hole imaging, the next frontier is the dynamic and 3D imaging of black holes. Recovering the dynamic 3D gas near a black hole would reveal previously-unseen parts of the universe and inform new physics models. However, only sparse radio measurements from a single viewpoint are possible, making the dynamic 3D reconstruction problem significantly ill-posed. Previously, BH-NeRF addressed the ill-posed problem by assuming Keplerian dynamics of the gas, but this assumption breaks down near the black hole, where the strong gravitational pull of the black hole and increased electromagnetic activity complicate fluid dynamics. To overcome the restrictive assumptions of BH-NeRF, we propose PI-DEF, a physics-informed approach that uses differentiable neural rendering to fit a 4D (time + 3D) emissivity field given EHT measurements. Our approach jointly reconstructs the 3D velocity field with the 4D emissivity field and enforces the velocity as a soft constraint on the dynamics of the emissivity. In experiments on simulated data, we find significantly improved reconstruction accuracy over both BH-NeRF and a physics-agnostic approach. We demonstrate how our method may be used to estimate other physics parameters of the black hole, such as its spin.
Large Video Planner Enables Generalizable Robot Control
Dec 17, 2025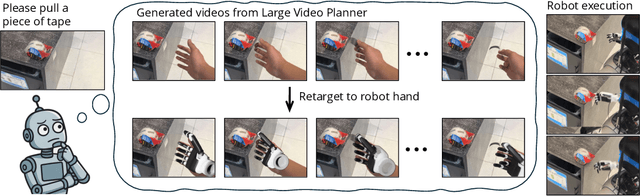
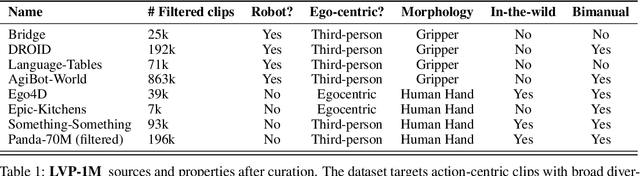
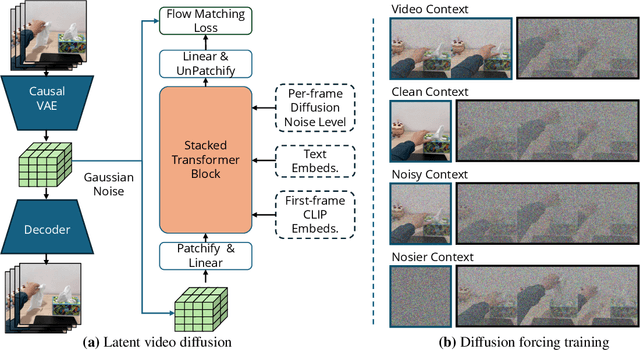

General-purpose robots require decision-making models that generalize across diverse tasks and environments. Recent works build robot foundation models by extending multimodal large language models (MLLMs) with action outputs, creating vision-language-action (VLA) systems. These efforts are motivated by the intuition that MLLMs' large-scale language and image pretraining can be effectively transferred to the action output modality. In this work, we explore an alternative paradigm of using large-scale video pretraining as a primary modality for building robot foundation models. Unlike static images and language, videos capture spatio-temporal sequences of states and actions in the physical world that are naturally aligned with robotic behavior. We curate an internet-scale video dataset of human activities and task demonstrations, and train, for the first time at a foundation-model scale, an open video model for generative robotics planning. The model produces zero-shot video plans for novel scenes and tasks, which we post-process to extract executable robot actions. We evaluate task-level generalization through third-party selected tasks in the wild and real-robot experiments, demonstrating successful physical execution. Together, these results show robust instruction following, strong generalization, and real-world feasibility. We release both the model and dataset to support open, reproducible video-based robot learning. Our website is available at https://www.boyuan.space/large-video-planner/.
Single-pass Adaptive Image Tokenization for Minimum Program Search
Jul 10, 2025According to Algorithmic Information Theory (AIT) -- Intelligent representations compress data into the shortest possible program that can reconstruct its content, exhibiting low Kolmogorov Complexity (KC). In contrast, most visual representation learning systems use fixed-length representations for all inputs, ignoring variations in complexity or familiarity. Recent adaptive tokenization methods address this by allocating variable-length representations but typically require test-time search over multiple encodings to find the most predictive one. Inspired by Kolmogorov Complexity principles, we propose a single-pass adaptive tokenizer, KARL, which predicts the appropriate number of tokens for an image in a single forward pass, halting once its approximate KC is reached. The token count serves as a proxy for the minimum description length. KARL's training procedure closely resembles the Upside-Down Reinforcement Learning paradigm, as it learns to conditionally predict token halting based on a desired reconstruction quality. KARL matches the performance of recent adaptive tokenizers while operating in a single pass. We present scaling laws for KARL, analyzing the role of encoder/decoder size, continuous vs. discrete tokenization and more. Additionally, we offer a conceptual study drawing an analogy between Adaptive Image Tokenization and Algorithmic Information Theory, examining the predicted image complexity (KC) across axes such as structure vs. noise and in- vs. out-of-distribution familiarity -- revealing alignment with human intuition.
Test-Time Training Done Right
May 29, 2025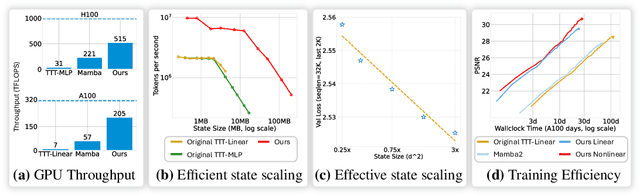

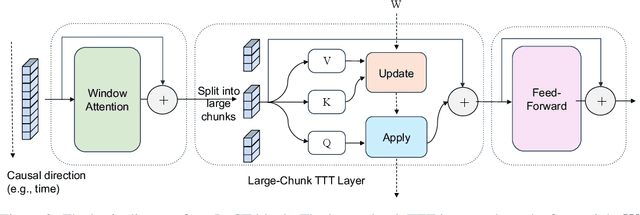
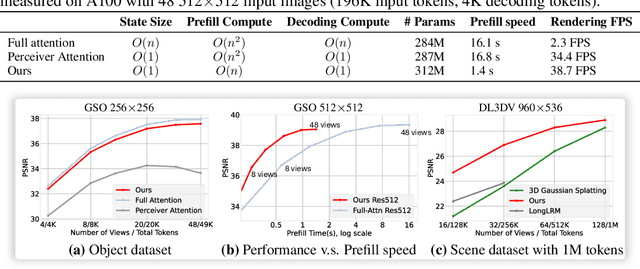
Test-Time Training (TTT) models context dependencies by adapting part of the model's weights (referred to as fast weights) during inference. This fast weight, akin to recurrent states in RNNs, stores temporary memories of past tokens in the current sequence. Existing TTT methods struggled to show effectiveness in handling long-context data, due to their inefficiency on modern GPUs. The TTT layers in many of these approaches operate with extremely low FLOPs utilization (often <5%) because they deliberately apply small online minibatch sizes (e.g., updating fast weights every 16 or 64 tokens). Moreover, a small minibatch implies fine-grained block-wise causal dependencies in the data, unsuitable for data beyond 1D ordered sequences, like sets or N-dimensional grids such as images or videos. In contrast, we pursue the opposite direction by using an extremely large chunk update, ranging from 2K to 1M tokens across tasks of varying modalities, which we refer to as Large Chunk Test-Time Training (LaCT). It improves hardware utilization by orders of magnitude, and more importantly, facilitates scaling of nonlinear state size (up to 40% of model parameters), hence substantially improving state capacity, all without requiring cumbersome and error-prone kernel implementations. It also allows easy integration of sophisticated optimizers, e.g. Muon for online updates. We validate our approach across diverse modalities and tasks, including novel view synthesis with image set, language models, and auto-regressive video diffusion. Our approach can scale up to 14B-parameter AR video diffusion model on sequences up to 56K tokens. In our longest sequence experiment, we perform novel view synthesis with 1 million context length. We hope this work will inspire and accelerate new research in the field of long-context modeling and test-time training. Website: https://tianyuanzhang.com/projects/ttt-done-right
Eval3D: Interpretable and Fine-grained Evaluation for 3D Generation
Apr 25, 2025Despite the unprecedented progress in the field of 3D generation, current systems still often fail to produce high-quality 3D assets that are visually appealing and geometrically and semantically consistent across multiple viewpoints. To effectively assess the quality of the generated 3D data, there is a need for a reliable 3D evaluation tool. Unfortunately, existing 3D evaluation metrics often overlook the geometric quality of generated assets or merely rely on black-box multimodal large language models for coarse assessment. In this paper, we introduce Eval3D, a fine-grained, interpretable evaluation tool that can faithfully evaluate the quality of generated 3D assets based on various distinct yet complementary criteria. Our key observation is that many desired properties of 3D generation, such as semantic and geometric consistency, can be effectively captured by measuring the consistency among various foundation models and tools. We thus leverage a diverse set of models and tools as probes to evaluate the inconsistency of generated 3D assets across different aspects. Compared to prior work, Eval3D provides pixel-wise measurement, enables accurate 3D spatial feedback, and aligns more closely with human judgments. We comprehensively evaluate existing 3D generation models using Eval3D and highlight the limitations and challenges of current models.