 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamCtrl3D: Single-Image Scene Exploration with Precise 3D Camera Control
Jan 10, 2025



We propose a method for generating fly-through videos of a scene, from a single image and a given camera trajectory. We build upon an image-to-video latent diffusion model. We condition its UNet denoiser on the camera trajectory, using four techniques. (1) We condition the UNet's temporal blocks on raw camera extrinsics, similar to MotionCtrl. (2) We use images containing camera rays and directions, similar to CameraCtrl. (3) We reproject the initial image to subsequent frames and use the resulting video as a condition. (4) We use 2D<=>3D transformers to introduce a global 3D representation, which implicitly conditions on the camera poses. We combine all conditions in a ContolNet-style architecture. We then propose a metric that evaluates overall video quality and the ability to preserve details with view changes, which we use to analyze the trade-offs of individual and combined conditions. Finally, we identify an optimal combination of conditions. We calibrate camera positions in our datasets for scale consistency across scenes, and we train our scene exploration model, CamCtrl3D, demonstrating state-of-theart results.
Efficient Hybrid Zoom using Camera Fusion on Mobile Phones
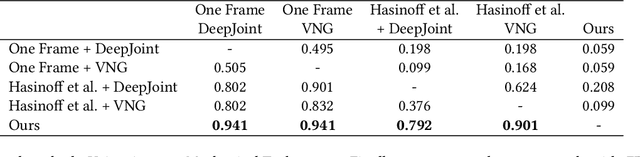
Jan 02, 2024DSLR cameras can achieve multiple zoom levels via shifting lens distances or swapping lens types. However, these techniques are not possible on smartphone devices due to space constraints. Most smartphone manufacturers adopt a hybrid zoom system: commonly a Wide (W) camera at a low zoom level and a Telephoto (T) camera at a high zoom level. To simulate zoom levels between W and T, these systems crop and digitally upsample images from W, leading to significant detail loss. In this paper, we propose an efficient system for hybrid zoom super-resolution on mobile devices, which captures a synchronous pair of W and T shots and leverages machine learning models to align and transfer details from T to W. We further develop an adaptive blending method that accounts for depth-of-field mismatches, scene occlusion, flow uncertainty, and alignment errors. To minimize the domain gap, we design a dual-phone camera rig to capture real-world inputs and ground-truths for supervised training. Our method generates a 12-megapixel image in 500ms on a mobile platform and compares favorably against state-of-the-art methods under extensive evaluation on real-world scenarios.
Face Deblurring using Dual Camera Fusion on Mobile Phones
Jul 23, 2022
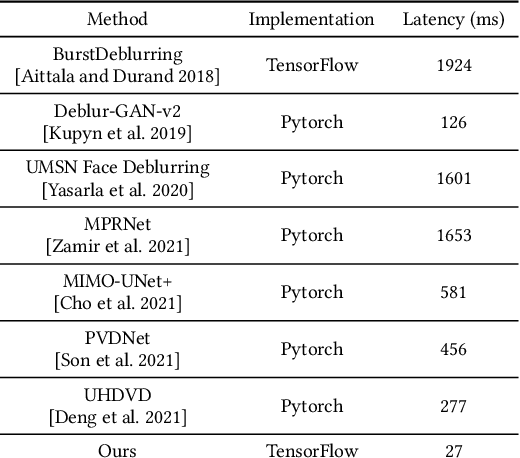

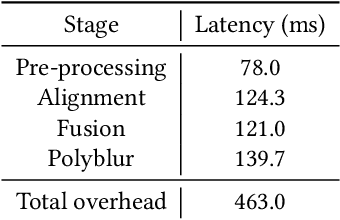
Motion blur of fast-moving subjects is a longstanding problem in photography and very common on mobile phones due to limited light collection efficiency, particularly in low-light conditions. While we have witnessed great progress in image deblurring in recent years, most methods require significant computational power and have limitations in processing high-resolution photos with severe local motions. To this end, we develop a novel face deblurring system based on the dual camera fusion technique for mobile phones. The system detects subject motion to dynamically enable a reference camera, e.g., ultrawide angle camera commonly available on recent premium phones, and captures an auxiliary photo with faster shutter settings. While the main shot is low noise but blurry, the reference shot is sharp but noisy. We learn ML models to align and fuse these two shots and output a clear photo without motion blur. Our algorithm runs efficiently on Google Pixel 6, which takes 463 ms overhead per shot. Our experiments demonstrate the advantage and robustness of our system against alternative single-image, multi-frame, face-specific, and video deblurring algorithms as well as commercial products. To the best of our knowledge, our work is the first mobile solution for face motion deblurring that works reliably and robustly over thousands of images in diverse motion and lighting conditions.
SLIDE: Single Image 3D Photography with Soft Layering and Depth-aware Inpainting
Sep 02, 2021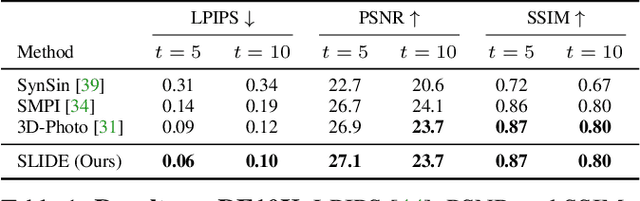
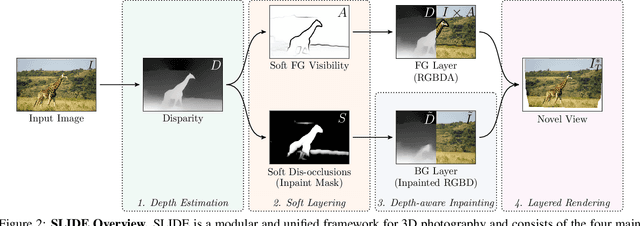
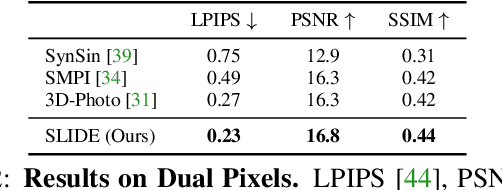

Single image 3D photography enables viewers to view a still image from novel viewpoints. Recent approaches combine monocular depth networks with inpainting networks to achieve compelling results. A drawback of these techniques is the use of hard depth layering, making them unable to model intricate appearance details such as thin hair-like structures. We present SLIDE, a modular and unified system for single image 3D photography that uses a simple yet effective soft layering strategy to better preserve appearance details in novel views. In addition, we propose a novel depth-aware training strategy for our inpainting module, better suited for the 3D photography task. The resulting SLIDE approach is modular, enabling the use of other components such as segmentation and matting for improved layering. At the same time, SLIDE uses an efficient layered depth formulation that only requires a single forward pass through the component networks to produce high quality 3D photos. Extensive experimental analysis on three view-synthesis datasets, in combination with user studies on in-the-wild image collections, demonstrate superior performance of our technique in comparison to existing strong baselines while being conceptually much simpler. Project page: https://varunjampani.github.io/slide
AutoFlow: Learning a Better Training Set for Optical Flow
Apr 29, 2021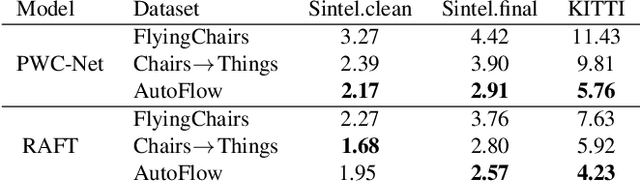
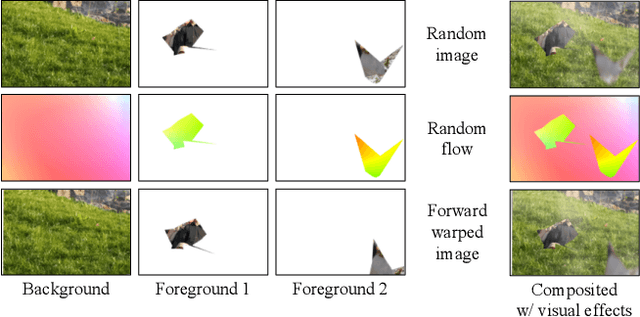
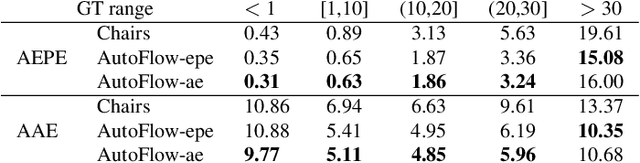
Synthetic datasets play a critical role in pre-training CNN models for optical flow, but they are painstaking to generate and hard to adapt to new applications. To automate the process, we present AutoFlow, a simple and effective method to render training data for optical flow that optimizes the performance of a model on a target dataset. AutoFlow takes a layered approach to render synthetic data, where the motion, shape, and appearance of each layer are controlled by learnable hyperparameters. Experimental results show that AutoFlow achieves state-of-the-art accuracy in pre-training both PWC-Net and RAFT. Our code and data are available at https://autoflow-google.github.io .
Robust image stitching with multiple registrations
Nov 23, 2020
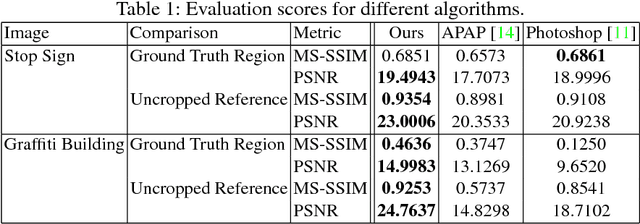


Panorama creation is one of the most widely deployed techniques in computer vision. In addition to industry applications such as Google Street View, it is also used by millions of consumers in smartphones and other cameras. Traditionally, the problem is decomposed into three phases: registration, which picks a single transformation of each source image to align it to the other inputs, seam finding, which selects a source image for each pixel in the final result, and blending, which fixes minor visual artifacts. Here, we observe that the use of a single registration often leads to errors, especially in scenes with significant depth variation or object motion. We propose instead the use of multiple registrations, permitting regions of the image at different depths to be captured with greater accuracy. MRF inference techniques naturally extend to seam finding over multiple registrations, and we show here that their energy functions can be readily modified with new terms that discourage duplication and tearing, common problems that are exacerbated by the use of multiple registrations. Our techniques are closely related to layer-based stereo, and move image stitching closer to explicit scene modeling. Experimental evidence demonstrates that our techniques often generate significantly better panoramas when there is substantial motion or parallax.
Handheld Multi-Frame Super-Resolution
May 08, 2019
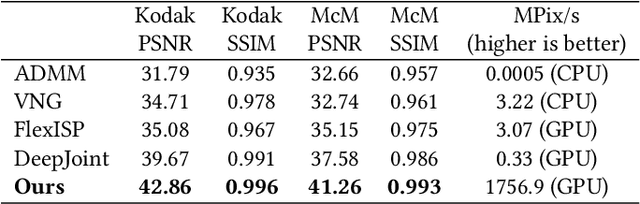
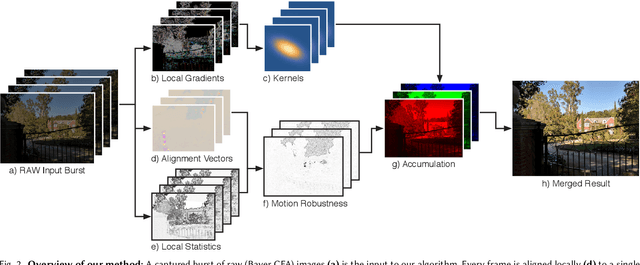
Compared to DSLR cameras, smartphone cameras have smaller sensors, which limits their spatial resolution; smaller apertures, which limits their light gathering ability; and smaller pixels, which reduces their signal-to noise ratio. The use of color filter arrays (CFAs) requires demosaicing, which further degrades resolution. In this paper, we supplant the use of traditional demosaicing in single-frame and burst photography pipelines with a multiframe super-resolution algorithm that creates a complete RGB image directly from a burst of CFA raw images. We harness natural hand tremor, typical in handheld photography, to acquire a burst of raw frames with small offsets. These frames are then aligned and merged to form a single image with red, green, and blue values at every pixel site. This approach, which includes no explicit demosaicing step, serves to both increase image resolution and boost signal to noise ratio. Our algorithm is robust to challenging scene conditions: local motion, occlusion, or scene changes. It runs at 100 milliseconds per 12-megapixel RAW input burst frame on mass-produced mobile phones. Specifically, the algorithm is the basis of the Super-Res Zoom feature, as well as the default merge method in Night Sight mode (whether zooming or not) on Google's flagship phone.