 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Cinemetrics : Structured Taxonomy and Evaluation for Professional Video Generation
Sep 30, 2025Recent advances in video generation have enabled high-fidelity video synthesis from user provided prompts. However, existing models and benchmarks fail to capture the complexity and requirements of professional video generation. Towards that goal, we introduce Stable Cinemetrics, a structured evaluation framework that formalizes filmmaking controls into four disentangled, hierarchical taxonomies: Setup, Event, Lighting, and Camera. Together, these taxonomies define 76 fine-grained control nodes grounded in industry practices. Using these taxonomies, we construct a benchmark of prompts aligned with professional use cases and develop an automated pipeline for prompt categorization and question generation, enabling independent evaluation of each control dimension. We conduct a large-scale human study spanning 10+ models and 20K videos, annotated by a pool of 80+ film professionals. Our analysis, both coarse and fine-grained reveal that even the strongest current models exhibit significant gaps, particularly in Events and Camera-related controls. To enable scalable evaluation, we train an automatic evaluator, a vision-language model aligned with expert annotations that outperforms existing zero-shot baselines. SCINE is the first approach to situate professional video generation within the landscape of video generative models, introducing taxonomies centered around cinematic controls and supporting them with structured evaluation pipelines and detailed analyses to guide future research.
DiffusionLight-Turbo: Accelerated Light Probes for Free via Single-Pass Chrome Ball Inpainting
Jul 02, 2025We introduce a simple yet effective technique for estimating lighting from a single low-dynamic-range (LDR) image by reframing the task as a chrome ball inpainting problem. This approach leverages a pre-trained diffusion model, Stable Diffusion XL, to overcome the generalization failures of existing methods that rely on limited HDR panorama datasets. While conceptually simple, the task remains challenging because diffusion models often insert incorrect or inconsistent content and cannot readily generate chrome balls in HDR format. Our analysis reveals that the inpainting process is highly sensitive to the initial noise in the diffusion process, occasionally resulting in unrealistic outputs. To address this, we first introduce DiffusionLight, which uses iterative inpainting to compute a median chrome ball from multiple outputs to serve as a stable, low-frequency lighting prior that guides the generation of a high-quality final result. To generate high-dynamic-range (HDR) light probes, an Exposure LoRA is fine-tuned to create LDR images at multiple exposure values, which are then merged. While effective, DiffusionLight is time-intensive, requiring approximately 30 minutes per estimation. To reduce this overhead, we introduce DiffusionLight-Turbo, which reduces the runtime to about 30 seconds with minimal quality loss. This 60x speedup is achieved by training a Turbo LoRA to directly predict the averaged chrome balls from the iterative process. Inference is further streamlined into a single denoising pass using a LoRA swapping technique. Experimental results that show our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios. Our code is available at https://diffusionlight.github.io/turbo
LightHeadEd: Relightable & Editable Head Avatars from a Smartphone
Apr 13, 2025Creating photorealistic, animatable, and relightable 3D head avatars traditionally requires expensive Lightstage with multiple calibrated cameras, making it inaccessible for widespread adoption. To bridge this gap, we present a novel, cost-effective approach for creating high-quality relightable head avatars using only a smartphone equipped with polaroid filters. Our approach involves simultaneously capturing cross-polarized and parallel-polarized video streams in a dark room with a single point-light source, separating the skin's diffuse and specular components during dynamic facial performances. We introduce a hybrid representation that embeds 2D Gaussians in the UV space of a parametric head model, facilitating efficient real-time rendering while preserving high-fidelity geometric details. Our learning-based neural analysis-by-synthesis pipeline decouples pose and expression-dependent geometrical offsets from appearance, decomposing the surface into albedo, normal, and specular UV texture maps, along with the environment maps. We collect a unique dataset of various subjects performing diverse facial expressions and head movements.
CamCtrl3D: Single-Image Scene Exploration with Precise 3D Camera Control
Jan 10, 2025



We propose a method for generating fly-through videos of a scene, from a single image and a given camera trajectory. We build upon an image-to-video latent diffusion model. We condition its UNet denoiser on the camera trajectory, using four techniques. (1) We condition the UNet's temporal blocks on raw camera extrinsics, similar to MotionCtrl. (2) We use images containing camera rays and directions, similar to CameraCtrl. (3) We reproject the initial image to subsequent frames and use the resulting video as a condition. (4) We use 2D<=>3D transformers to introduce a global 3D representation, which implicitly conditions on the camera poses. We combine all conditions in a ContolNet-style architecture. We then propose a metric that evaluates overall video quality and the ability to preserve details with view changes, which we use to analyze the trade-offs of individual and combined conditions. Finally, we identify an optimal combination of conditions. We calibrate camera positions in our datasets for scale consistency across scenes, and we train our scene exploration model, CamCtrl3D, demonstrating state-of-theart results.
ICE-G: Image Conditional Editing of 3D Gaussian Splats
Jun 12, 2024



Recently many techniques have emerged to create high quality 3D assets and scenes. When it comes to editing of these objects, however, existing approaches are either slow, compromise on quality, or do not provide enough customization. We introduce a novel approach to quickly edit a 3D model from a single reference view. Our technique first segments the edit image, and then matches semantically corresponding regions across chosen segmented dataset views using DINO features. A color or texture change from a particular region of the edit image can then be applied to other views automatically in a semantically sensible manner. These edited views act as an updated dataset to further train and re-style the 3D scene. The end-result is therefore an edited 3D model. Our framework enables a wide variety of editing tasks such as manual local edits, correspondence based style transfer from any example image, and a combination of different styles from multiple example images. We use Gaussian Splats as our primary 3D representation due to their speed and ease of local editing, but our technique works for other methods such as NeRFs as well. We show through multiple examples that our method produces higher quality results while offering fine-grained control of editing. Project page: ice-gaussian.github.io
AI Algorithm for Predicting and Optimizing Trajectory of UAV Swarm
May 20, 2024This paper explores the application of Artificial Intelligence (AI) techniques for generating the trajectories of fleets of Unmanned Aerial Vehicles (UAVs). The two main challenges addressed include accurately predicting the paths of UAVs and efficiently avoiding collisions between them. Firstly, the paper systematically applies a diverse set of activation functions to a Feedforward Neural Network (FFNN) with a single hidden layer, which enhances the accuracy of the predicted path compared to previous work. Secondly, we introduce a novel activation function, AdaptoSwelliGauss, which is a sophisticated fusion of Swish and Elliott activations, seamlessly integrated with a scaled and shifted Gaussian component. Swish facilitates smooth transitions, Elliott captures abrupt trajectory changes, and the scaled and shifted Gaussian enhances robustness against noise. This dynamic combination is specifically designed to excel in capturing the complexities of UAV trajectory prediction. This new activation function gives substantially better accuracy than all existing activation functions. Thirdly, we propose a novel Integrated Collision Detection, Avoidance, and Batching (ICDAB) strategy that merges two complementary UAV collision avoidance techniques: changing UAV trajectories and altering their starting times, also referred to as batching. This integration helps overcome the disadvantages of both - reduction in the number of trajectory manipulations, which avoids overly convoluted paths in the first technique, and smaller batch sizes, which reduce overall takeoff time in the second.
Probing the 3D Awareness of Visual Foundation Models
Apr 12, 2024Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
3D Congealing: 3D-Aware Image Alignment in the Wild
Apr 02, 2024



We propose 3D Congealing, a novel problem of 3D-aware alignment for 2D images capturing semantically similar objects. Given a collection of unlabeled Internet images, our goal is to associate the shared semantic parts from the inputs and aggregate the knowledge from 2D images to a shared 3D canonical space. We introduce a general framework that tackles the task without assuming shape templates, poses, or any camera parameters. At its core is a canonical 3D representation that encapsulates geometric and semantic information. The framework optimizes for the canonical representation together with the pose for each input image, and a per-image coordinate map that warps 2D pixel coordinates to the 3D canonical frame to account for the shape matching. The optimization procedure fuses prior knowledge from a pre-trained image generative model and semantic information from input images. The former provides strong knowledge guidance for this under-constraint task, while the latter provides the necessary information to mitigate the training data bias from the pre-trained model. Our framework can be used for various tasks such as correspondence matching, pose estimation, and image editing, achieving strong results on real-world image datasets under challenging illumination conditions and on in-the-wild online image collections.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024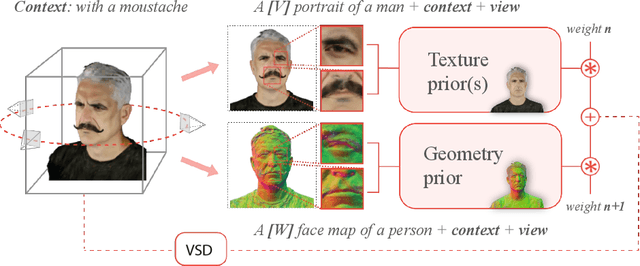



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
WordRobe: Text-Guided Generation of Textured 3D Garments
Mar 26, 2024In this paper, we tackle a new and challenging problem of text-driven generation of 3D garments with high-quality textures. We propose "WordRobe", a novel framework for the generation of unposed & textured 3D garment meshes from user-friendly text prompts. We achieve this by first learning a latent representation of 3D garments using a novel coarse-to-fine training strategy and a loss for latent disentanglement, promoting better latent interpolation. Subsequently, we align the garment latent space to the CLIP embedding space in a weakly supervised manner, enabling text-driven 3D garment generation and editing. For appearance modeling, we leverage the zero-shot generation capability of ControlNet to synthesize view-consistent texture maps in a single feed-forward inference step, thereby drastically decreasing the generation time as compared to existing methods. We demonstrate superior performance over current SOTAs for learning 3D garment latent space, garment interpolation, and text-driven texture synthesis, supported by quantitative evaluation and qualitative user study. The unposed 3D garment meshes generated using WordRobe can be directly fed to standard cloth simulation & animation pipelines without any post-processing.