 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMB-Loc: Multi-planar Bird's-eye-view Localization in outdoor LiDAR scenes
Jun 07, 2026Global LiDAR localization is a fundamental task for autonomous navigation systems. Recent methods perform Scene Coordinate Regression (SCR) and achieve superior accuracy over Absolute Pose Regression (APR) solutions by predicting dense 3D world coordinates. However, SCR approaches introduce two major bottlenecks: severe computational inefficiency from processing raw 3D geometries and significant performance degradation under varying sensor viewpoints. To address these limitations, we present MB-Loc, a lightweight and viewpoint-robust SCR framework. Instead of relying on heavy 3D convolutions, we project the input LiDAR scan into a 2.5D Multi-planar Bird's-Eye View (BEV) representation. By slicing the point-cloud along the Z-axis and mapping signed depths into discrete 2D planes, MB-Loc retains essential 3D geometric structures while exploiting the computational tractability of standard 2D CNNs. To handle the inherent sparsity of outdoor LiDAR, we introduce a KL-regularized latent bottleneck that explicitly models spatial uncertainty without injecting stochastic noise. Finally, to ensure rotation robustness, we apply 3D spatial augmentations prior to planar projection, forcing the network to implicitly learn viewpoint-invariant features. We perform extensive experiments on the publicly available NCLT dataset and demonstrate that our proposed method outperforms the current state-of-the-art. Operating at real-time inference speeds, MB-Loc significantly outperforms traditional 3D-SCR architectures in computational efficiency.
HyperBones: Realtime Bone-driven Neural Garment Simulation with Hypernetwork Conditioning
May 19, 2026Recent advances in garment simulation have brought high-quality results closer to real-time performance. Physics-based simulators can produce accurate motion, but remain too computationally expensive for interactive applications. In contrast, linear blend skinning is efficient, but cannot capture the complex dynamics of loose-fitting garments, often leading to unrealistic motion and visual artifacts. Neural methods offer a promising alternative, yet they still struggle to animate loose clothing plausibly under strict runtime constraints. We present a fast and physically plausible approach for dynamic garment simulation. Our method trains a reduced-space neural dynamics simulator composed of independent coarse- and fine-level components. At the coarse level, the garment is driven by a set of virtual bones integrated with a lightweight neural network. Fine-scale wrinkle details are then recovered using a trained convolutional neural map. By decoupling identity-specific computation from real-time neural integration, our architecture maintains high performance while supporting diverse body shapes and motions. We further introduce an effective physics-supervision scheme that enables accurate results without relying on an external simulator. Experiments show that our method produces physically plausible garment dynamics, generalizes across a range of motions and body shapes, and supports a fixed set of garments. Our simulator runs at 300+ FPS on a commodity GPU, making it suitable for real-time applications.
DInf-Grid: A Neural Differential Equation Solver with Differentiable Feature Grids
Jan 15, 2026We present a novel differentiable grid-based representation for efficiently solving differential equations (DEs). Widely used architectures for neural solvers, such as sinusoidal neural networks, are coordinate-based MLPs that are both computationally intensive and slow to train. Although grid-based alternatives for implicit representations (e.g., Instant-NGP and K-Planes) train faster by exploiting signal structure, their reliance on linear interpolation restricts their ability to compute higher-order derivatives, rendering them unsuitable for solving DEs. Our approach overcomes these limitations by combining the efficiency of feature grids with radial basis function interpolation, which is infinitely differentiable. To effectively capture high-frequency solutions and enable stable and faster computation of global gradients, we introduce a multi-resolution decomposition with co-located grids. Our proposed representation, DInf-Grid, is trained implicitly using the differential equations as loss functions, enabling accurate modelling of physical fields. We validate DInf-Grid on a variety of tasks, including the Poisson equation for image reconstruction, the Helmholtz equation for wave fields, and the Kirchhoff-Love boundary value problem for cloth simulation. Our results demonstrate a 5-20x speed-up over coordinate-based MLP-based methods, solving differential equations in seconds or minutes while maintaining comparable accuracy and compactness.
SymGS : Leveraging Local Symmetries for 3D Gaussian Splatting Compression
Nov 19, 2025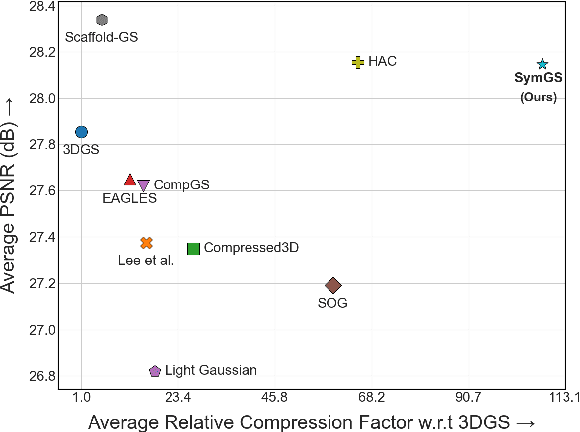



3D Gaussian Splatting has emerged as a transformative technique in novel view synthesis, primarily due to its high rendering speed and photorealistic fidelity. However, its memory footprint scales rapidly with scene complexity, often reaching several gigabytes. Existing methods address this issue by introducing compression strategies that exploit primitive-level redundancy through similarity detection and quantization. We aim to surpass the compression limits of such methods by incorporating symmetry-aware techniques, specifically targeting mirror symmetries to eliminate redundant primitives. We propose a novel compression framework, SymGS, introducing learnable mirrors into the scene, thereby eliminating local and global reflective redundancies for compression. Our framework functions as a plug-and-play enhancement to state-of-the-art compression methods, (e.g. HAC) to achieve further compression. Compared to HAC, we achieve $1.66 \times$ compression across benchmark datasets (upto $3\times$ on large-scale scenes). On an average, SymGS enables $\bf{108\times}$ compression of a 3DGS scene, while preserving rendering quality. The project page and supplementary can be found at symgs.github.io
NGD: Neural Gradient Based Deformation for Monocular Garment Reconstruction
Aug 25, 2025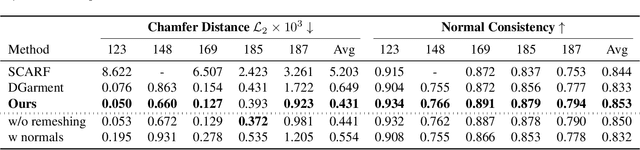
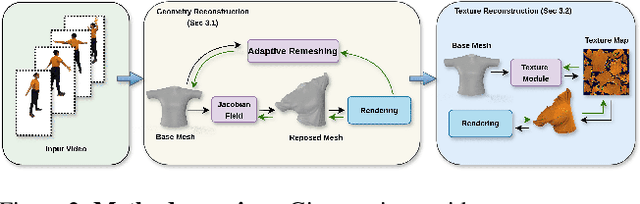

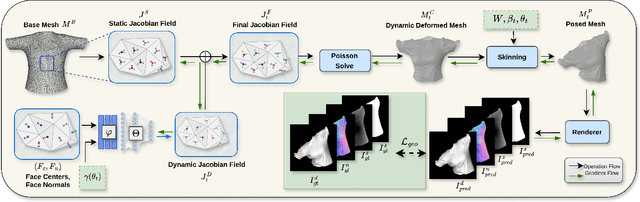
Dynamic garment reconstruction from monocular video is an important yet challenging task due to the complex dynamics and unconstrained nature of the garments. Recent advancements in neural rendering have enabled high-quality geometric reconstruction with image/video supervision. However, implicit representation methods that use volume rendering often provide smooth geometry and fail to model high-frequency details. While template reconstruction methods model explicit geometry, they use vertex displacement for deformation, which results in artifacts. Addressing these limitations, we propose NGD, a Neural Gradient-based Deformation method to reconstruct dynamically evolving textured garments from monocular videos. Additionally, we propose a novel adaptive remeshing strategy for modelling dynamically evolving surfaces like wrinkles and pleats of the skirt, leading to high-quality reconstruction. Finally, we learn dynamic texture maps to capture per-frame lighting and shadow effects. We provide extensive qualitative and quantitative evaluations to demonstrate significant improvements over existing SOTA methods and provide high-quality garment reconstructions.
LightHeadEd: Relightable & Editable Head Avatars from a Smartphone
Apr 13, 2025Creating photorealistic, animatable, and relightable 3D head avatars traditionally requires expensive Lightstage with multiple calibrated cameras, making it inaccessible for widespread adoption. To bridge this gap, we present a novel, cost-effective approach for creating high-quality relightable head avatars using only a smartphone equipped with polaroid filters. Our approach involves simultaneously capturing cross-polarized and parallel-polarized video streams in a dark room with a single point-light source, separating the skin's diffuse and specular components during dynamic facial performances. We introduce a hybrid representation that embeds 2D Gaussians in the UV space of a parametric head model, facilitating efficient real-time rendering while preserving high-fidelity geometric details. Our learning-based neural analysis-by-synthesis pipeline decouples pose and expression-dependent geometrical offsets from appearance, decomposing the surface into albedo, normal, and specular UV texture maps, along with the environment maps. We collect a unique dataset of various subjects performing diverse facial expressions and head movements.
WordRobe: Text-Guided Generation of Textured 3D Garments
Mar 26, 2024In this paper, we tackle a new and challenging problem of text-driven generation of 3D garments with high-quality textures. We propose "WordRobe", a novel framework for the generation of unposed & textured 3D garment meshes from user-friendly text prompts. We achieve this by first learning a latent representation of 3D garments using a novel coarse-to-fine training strategy and a loss for latent disentanglement, promoting better latent interpolation. Subsequently, we align the garment latent space to the CLIP embedding space in a weakly supervised manner, enabling text-driven 3D garment generation and editing. For appearance modeling, we leverage the zero-shot generation capability of ControlNet to synthesize view-consistent texture maps in a single feed-forward inference step, thereby drastically decreasing the generation time as compared to existing methods. We demonstrate superior performance over current SOTAs for learning 3D garment latent space, garment interpolation, and text-driven texture synthesis, supported by quantitative evaluation and qualitative user study. The unposed 3D garment meshes generated using WordRobe can be directly fed to standard cloth simulation & animation pipelines without any post-processing.
ATPPNet: Attention based Temporal Point cloud Prediction Network
Jan 30, 2024Point cloud prediction is an important yet challenging task in the field of autonomous driving. The goal is to predict future point cloud sequences that maintain object structures while accurately representing their temporal motion. These predicted point clouds help in other subsequent tasks like object trajectory estimation for collision avoidance or estimating locations with the least odometry drift. In this work, we present ATPPNet, a novel architecture that predicts future point cloud sequences given a sequence of previous time step point clouds obtained with LiDAR sensor. ATPPNet leverages Conv-LSTM along with channel-wise and spatial attention dually complemented by a 3D-CNN branch for extracting an enhanced spatio-temporal context to recover high quality fidel predictions of future point clouds. We conduct extensive experiments on publicly available datasets and report impressive performance outperforming the existing methods. We also conduct a thorough ablative study of the proposed architecture and provide an application study that highlights the potential of our model for tasks like odometry estimation.
Dress-Me-Up: A Dataset & Method for Self-Supervised 3D Garment Retargeting
Jan 06, 2024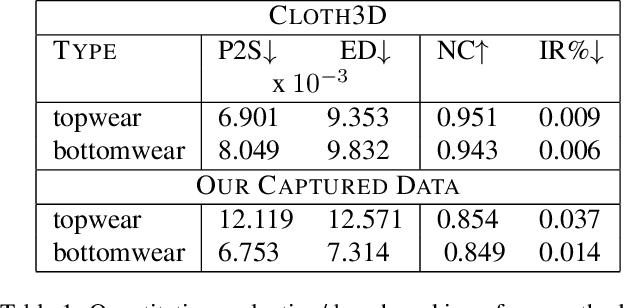
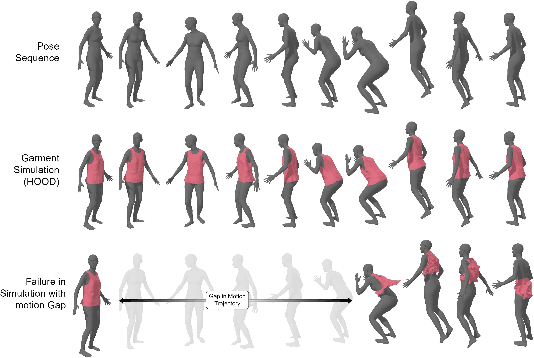
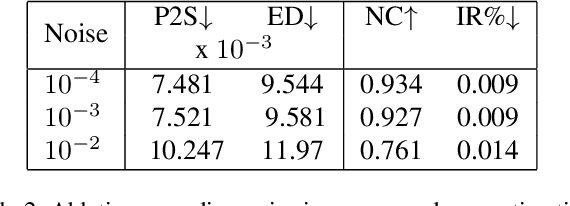
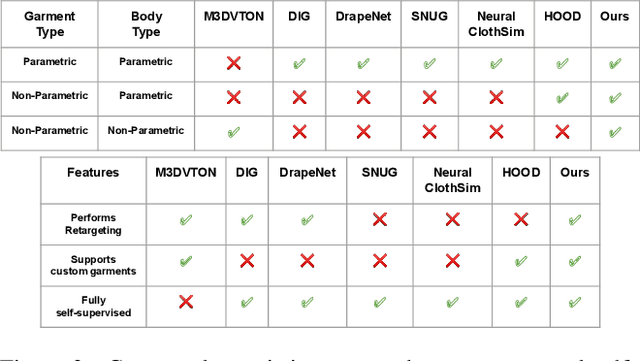
We propose a novel self-supervised framework for retargeting non-parameterized 3D garments onto 3D human avatars of arbitrary shapes and poses, enabling 3D virtual try-on (VTON). Existing self-supervised 3D retargeting methods only support parametric and canonical garments, which can only be draped over parametric body, e.g. SMPL. To facilitate the non-parametric garments and body, we propose a novel method that introduces Isomap Embedding based correspondences matching between the garment and the human body to get a coarse alignment between the two meshes. We perform neural refinement of the coarse alignment in a self-supervised setting. Further, we leverage a Laplacian detail integration method for preserving the inherent details of the input garment. For evaluating our 3D non-parametric garment retargeting framework, we propose a dataset of 255 real-world garments with realistic noise and topological deformations. The dataset contains $44$ unique garments worn by 15 different subjects in 5 distinctive poses, captured using a multi-view RGBD capture setup. We show superior retargeting quality on non-parametric garments and human avatars over existing state-of-the-art methods, acting as the first-ever baseline on the proposed dataset for non-parametric 3D garment retargeting.
MANUS: Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians
Dec 04, 2023



Understanding how we grasp objects with our hands has important applications in areas like robotics and mixed reality. However, this challenging problem requires accurate modeling of the contact between hands and objects. To capture grasps, existing methods use skeletons, meshes, or parametric models that can cause misalignments resulting in inaccurate contacts. We present MANUS, a method for Markerless Hand-Object Grasp Capture using Articulated 3D Gaussians. We build a novel articulated 3D Gaussians representation that extends 3D Gaussian splatting for high-fidelity representation of articulating hands. Since our representation uses Gaussian primitives, it enables us to efficiently and accurately estimate contacts between the hand and the object. For the most accurate results, our method requires tens of camera views that current datasets do not provide. We therefore build MANUS-Grasps, a new dataset that contains hand-object grasps viewed from 53 cameras across 30+ scenes, 3 subjects, and comprising over 7M frames. In addition to extensive qualitative results, we also show that our method outperforms others on a quantitative contact evaluation method that uses paint transfer from the object to the hand.