 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Spatio-Temporal Context for Temporally Consistent Robust 3D Human Motion Recovery from Monocular Videos
Nov 20, 2023



Recovering temporally consistent 3D human body pose, shape and motion from a monocular video is a challenging task due to (self-)occlusions, poor lighting conditions, complex articulated body poses, depth ambiguity, and limited availability of annotated data. Further, doing a simple perframe estimation is insufficient as it leads to jittery and implausible results. In this paper, we propose a novel method for temporally consistent motion estimation from a monocular video. Instead of using generic ResNet-like features, our method uses a body-aware feature representation and an independent per-frame pose and camera initialization over a temporal window followed by a novel spatio-temporal feature aggregation by using a combination of self-similarity and self-attention over the body-aware features and the perframe initialization. Together, they yield enhanced spatiotemporal context for every frame by considering remaining past and future frames. These features are used to predict the pose and shape parameters of the human body model, which are further refined using an LSTM. Experimental results on the publicly available benchmark data show that our method attains significantly lower acceleration error and outperforms the existing state-of-the-art methods over all key quantitative evaluation metrics, including complex scenarios like partial occlusion, complex poses and even relatively low illumination.
Dissecting Deep Networks into an Ensemble of Generative Classifiers for Robust Predictions
Jun 18, 2020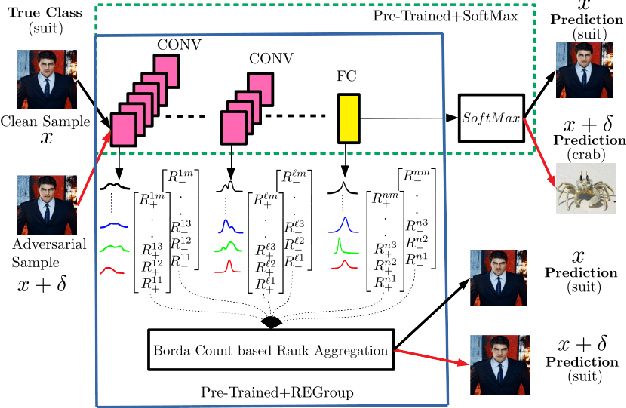
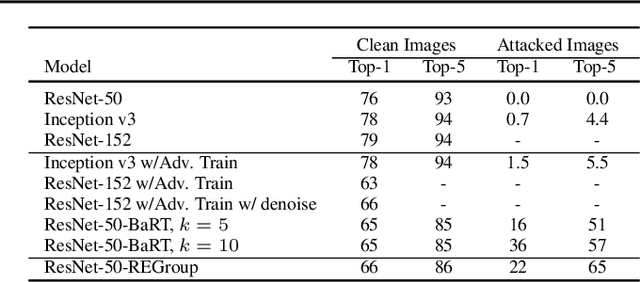
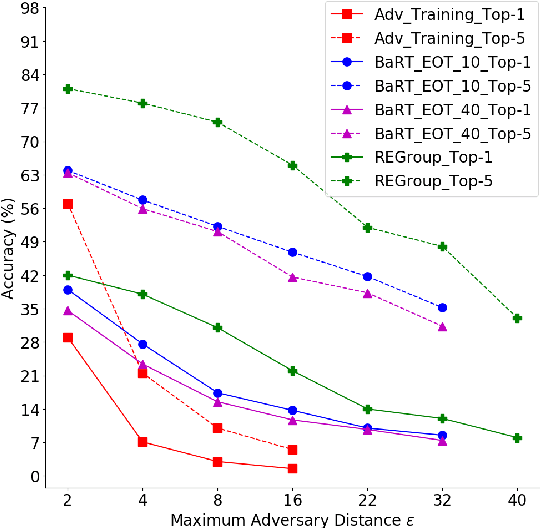
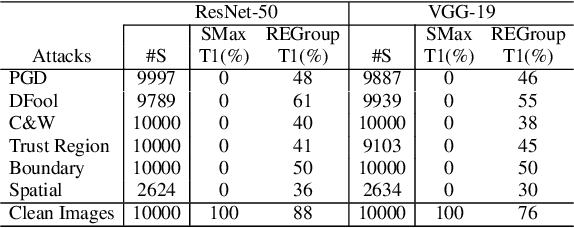
Deep Neural Networks (DNNs) are often criticized for being susceptible to adversarial attacks. Most successful defense strategies adopt adversarial training or random input transformations that typically require retraining or fine-tuning the model to achieve reasonable performance. In this work, our investigations of intermediate representations of a pre-trained DNN lead to an interesting discovery pointing to intrinsic robustness to adversarial attacks. We find that we can learn a generative classifier by statistically characterizing the neural response of an intermediate layer to clean training samples. The predictions of multiple such intermediate-layer based classifiers, when aggregated, show unexpected robustness to adversarial attacks. Specifically, we devise an ensemble of these generative classifiers that rank-aggregates their predictions via a Borda count-based consensus. Our proposed approach uses a subset of the clean training data and a pre-trained model, and yet is agnostic to network architectures or the adversarial attack generation method. We show extensive experiments to establish that our defense strategy achieves state-of-the-art performance on the ImageNet validation set.
DGSAC: Density Guided Sampling and Consensus
Jun 03, 2020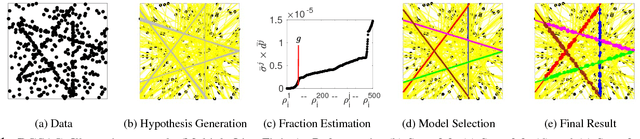
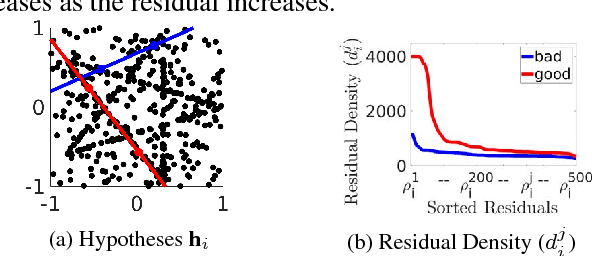
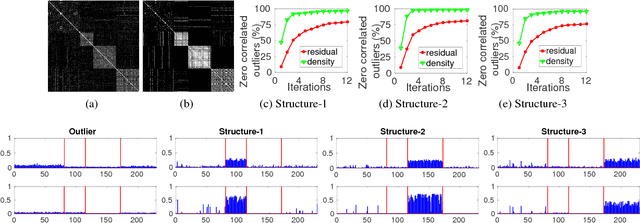
Robust multiple model fitting plays a crucial role in many computer vision applications. Unlike single model fitting problems, the multi-model fitting has additional challenges. The unknown number of models and the inlier noise scale are the two most important of them, which are in general provided by the user using ground-truth or some other auxiliary information. Mode seeking/ clustering-based approaches crucially depend on the quality of model hypotheses generated. While preference analysis based guided sampling approaches have shown remarkable performance, they operate in a time budget framework, and the user provides the time as a reasonable guess. In this paper, we deviate from the mode seeking and time budget framework. We propose a concept called Kernel Residual Density (KRD) and apply it to various components of a multiple-model fitting pipeline. The Kernel Residual Density act as a key differentiator between inliers and outliers. We use KRD to guide and automatically stop the sampling process. The sampling process stops after generating a set of hypotheses that can explain all the data points. An explanation score is maintained for each data point, which is updated on-the-fly. We propose two model selection algorithms, an optimal quadratic program based, and a greedy. Unlike mode seeking approaches, our model selection algorithms seek to find one representative hypothesis for each genuine structure present in the data. We evaluate our method (dubbed as DGSAC) on a wide variety of tasks like planar segmentation, motion segmentation, vanishing point estimation, plane fitting to 3D point cloud, line, and circle fitting, which shows the effectiveness of our method and its unified nature.
Pseudo RGB-D for Self-Improving Monocular SLAM and Depth Prediction
Apr 22, 2020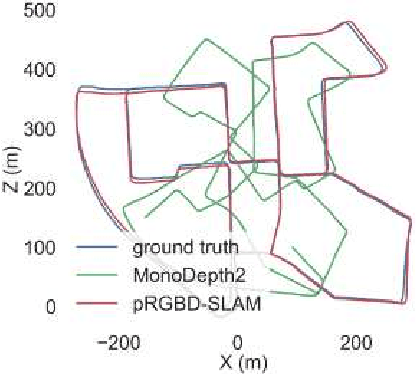
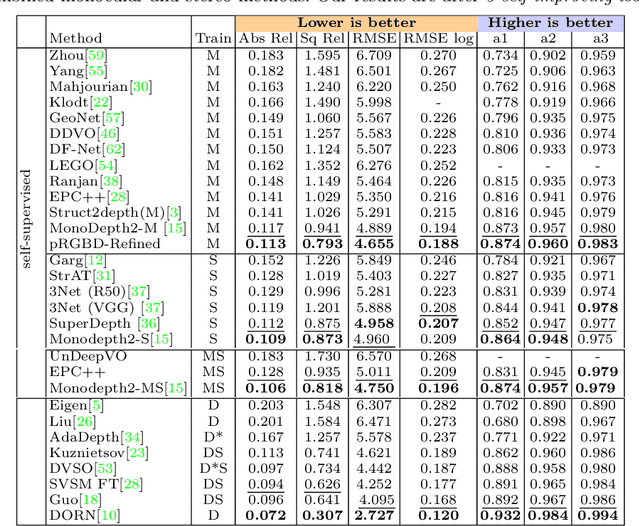
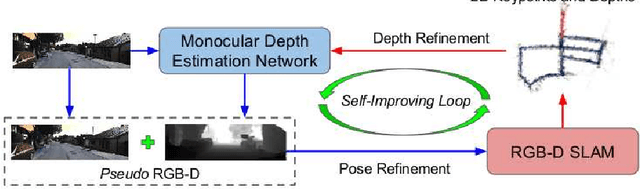
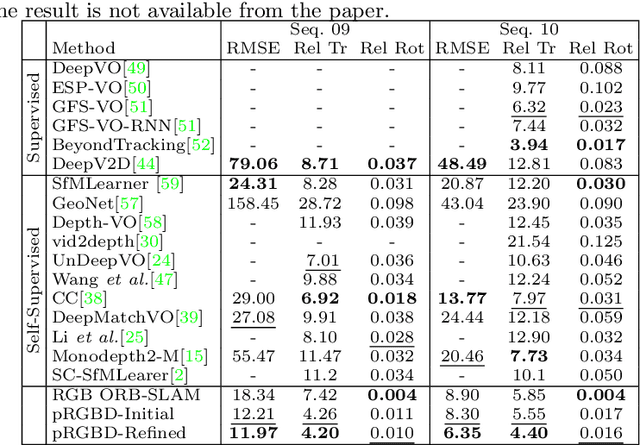
Classical monocular Simultaneous Localization And Mapping (SLAM) and the recently emerging convolutional neural networks (CNNs) for monocular depth prediction represent two largely disjoint approaches towards building a 3D map of the surrounding environment. In this paper, we demonstrate that the coupling of these two by leveraging the strengths of each mitigates the other's shortcomings. Specifically, we propose a joint narrow and wide baseline based self-improving framework, where on the one hand the CNN-predicted depth is leveraged to perform pseudo RGB-D feature-based SLAM, leading to better accuracy and robustness than the monocular RGB SLAM baseline. On the other hand, the bundle-adjusted 3D scene structures and camera poses from the more principled geometric SLAM are injected back into the depth network through novel wide baseline losses proposed for improving the depth prediction network, which then continues to contribute towards better pose and 3D structure estimation in the next iteration. We emphasize that our framework only requires unlabeled monocular videos in both training and inference stages, and yet is able to outperform state-of-the-art self-supervised monocular and stereo depth prediction networks (e.g, Monodepth2) and feature-based monocular SLAM system (i.e, ORB-SLAM). Extensive experiments on KITTI and TUM RGB-D datasets verify the superiority of our self-improving geometry-CNN framework.