 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Dec 19, 2025


LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It leverages explicit 3D scene decomposition to represent driving videos as a scene graph, containing static background and dynamic objects. To enable fine-grained editing and realism, it incorporates an agentic pipeline in which an Orchestrator transforms user instructions into execution graphs that coordinate specialized agents and tools. Specifically, an Object Grounding Agent establishes correspondence between free-form text descriptions and target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and then refined using a video diffusion tool to address artifacts introduced by object insertion and significant view changes. LangDriveCTRL supports both object node editing (removal, insertion and replacement) and multi-object behavior editing from a single natural-language instruction. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior structural preservation, photorealism, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
AutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
LANGTRAJ: Diffusion Model and Dataset for Language-Conditioned Trajectory Simulation
Apr 15, 2025



Evaluating autonomous vehicles with controllability enables scalable testing in counterfactual or structured settings, enhancing both efficiency and safety. We introduce LangTraj, a language-conditioned scene-diffusion model that simulates the joint behavior of all agents in traffic scenarios. By conditioning on natural language inputs, LangTraj provides flexible and intuitive control over interactive behaviors, generating nuanced and realistic scenarios. Unlike prior approaches that depend on domain-specific guidance functions, LangTraj incorporates language conditioning during training, facilitating more intuitive traffic simulation control. We propose a novel closed-loop training strategy for diffusion models, explicitly tailored to enhance stability and realism during closed-loop simulation. To support language-conditioned simulation, we develop Inter-Drive, a large-scale dataset with diverse and interactive labels for training language-conditioned diffusion models. Our dataset is built upon a scalable pipeline for annotating agent-agent interactions and single-agent behaviors, ensuring rich and varied supervision. Validated on the Waymo Motion Dataset, LangTraj demonstrates strong performance in realism, language controllability, and language-conditioned safety-critical simulation, establishing a new paradigm for flexible and scalable autonomous vehicle testing.
Locally Orderless Images for Optimization in Differentiable Rendering
Mar 27, 2025Problems in differentiable rendering often involve optimizing scene parameters that cause motion in image space. The gradients for such parameters tend to be sparse, leading to poor convergence. While existing methods address this sparsity through proxy gradients such as topological derivatives or lagrangian derivatives, they make simplifying assumptions about rendering. Multi-resolution image pyramids offer an alternative approach but prove unreliable in practice. We introduce a method that uses locally orderless images, where each pixel maps to a histogram of intensities that preserves local variations in appearance. Using an inverse rendering objective that minimizes histogram distance, our method extends support for sparsely defined image gradients and recovers optimal parameters. We validate our method on various inverse problems using both synthetic and real data.
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Mar 26, 2025



Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Mar 25, 2025
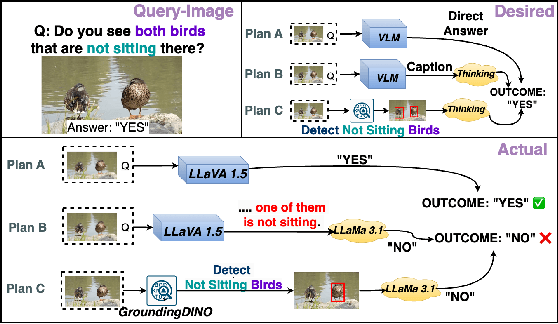
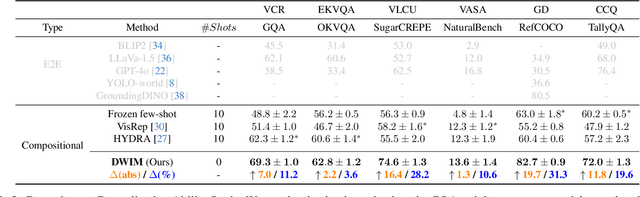
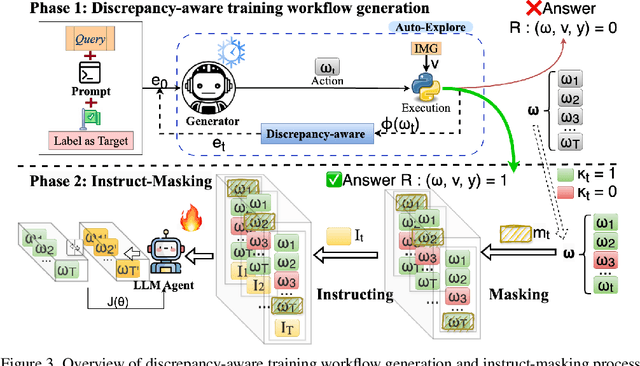
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
Materialist: Physically Based Editing Using Single-Image Inverse Rendering
Jan 07, 2025



To perform image editing based on single-view, inverse physically based rendering, we present a method combining a learning-based approach with progressive differentiable rendering. Given an image, our method leverages neural networks to predict initial material properties. Progressive differentiable rendering is then used to optimize the environment map and refine the material properties with the goal of closely matching the rendered result to the input image. We require only a single image while other inverse rendering methods based on the rendering equation require multiple views. In comparison to single-view methods that rely on neural renderers, our approach achieves more realistic light material interactions, accurate shadows, and global illumination. Furthermore, with optimized material properties and illumination, our method enables a variety of tasks, including physically based material editing, object insertion, and relighting. We also propose a method for material transparency editing that operates effectively without requiring full scene geometry. Compared with methods based on Stable Diffusion, our approach offers stronger interpretability and more realistic light refraction based on empirical results.
Drive-1-to-3: Enriching Diffusion Priors for Novel View Synthesis of Real Vehicles
Dec 19, 2024The recent advent of large-scale 3D data, e.g. Objaverse, has led to impressive progress in training pose-conditioned diffusion models for novel view synthesis. However, due to the synthetic nature of such 3D data, their performance drops significantly when applied to real-world images. This paper consolidates a set of good practices to finetune large pretrained models for a real-world task -- harvesting vehicle assets for autonomous driving applications. To this end, we delve into the discrepancies between the synthetic data and real driving data, then develop several strategies to account for them properly. Specifically, we start with a virtual camera rotation of real images to ensure geometric alignment with synthetic data and consistency with the pose manifold defined by pretrained models. We also identify important design choices in object-centric data curation to account for varying object distances in real driving scenes -- learn across varying object scales with fixed camera focal length. Further, we perform occlusion-aware training in latent spaces to account for ubiquitous occlusions in real data, and handle large viewpoint changes by leveraging a symmetric prior. Our insights lead to effective finetuning that results in a $68.8\%$ reduction in FID for novel view synthesis over prior arts.
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
May 22, 2024We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
A Minimalist Prompt for Zero-Shot Policy Learning
May 09, 2024Transformer-based methods have exhibited significant generalization ability when prompted with target-domain demonstrations or example solutions during inference. Although demonstrations, as a way of task specification, can capture rich information that may be hard to specify by language, it remains unclear what information is extracted from the demonstrations to help generalization. Moreover, assuming access to demonstrations of an unseen task is impractical or unreasonable in many real-world scenarios, especially in robotics applications. These questions motivate us to explore what the minimally sufficient prompt could be to elicit the same level of generalization ability as the demonstrations. We study this problem in the contextural RL setting which allows for quantitative measurement of generalization and is commonly adopted by meta-RL and multi-task RL benchmarks. In this setting, the training and test Markov Decision Processes (MDPs) only differ in certain properties, which we refer to as task parameters. We show that conditioning a decision transformer on these task parameters alone can enable zero-shot generalization on par with or better than its demonstration-conditioned counterpart. This suggests that task parameters are essential for the generalization and DT models are trying to recover it from the demonstration prompt. To extract the remaining generalizable information from the supervision, we introduce an additional learnable prompt which is demonstrated to further boost zero-shot generalization across a range of robotic control, manipulation, and navigation benchmark tasks.