 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenoBERT: A Language Model for Accurate Genotype Imputation
Mar 31, 2026Genotype imputation enables dense variant coverage for genome-wide association and risk-prediction studies, yet conventional reference-panel methods remain limited by ancestry bias and reduced rare-variant accuracy. We present Genotype Bidirectional Encoder Representations from Transformers (GenoBERT), a transformer-based, reference-free framework that tokenizes phased genotypes and uses a self-attention mechanism to capture both short- and long-range linkage disequilibrium (LD) dependencies. Benchmarking on two independent datasets including the Louisiana Osteoporosis Study (LOS) and the 1000 Genomes Project (1KGP) across ancestry groups and multiple genotype missingness levels (5-50%) shows that GenoBERT achieves the highest overall accuracy compared to four baseline methods (Beagle5.4, SCDA, BiU-Net, and STICI). At practical sparsity levels (up to 25% missing), GenoBERT attains high overall imputation accuracy ($r^2 approx 0.98$) across datasets, and maintains robust performance ($r^2 > 0.90$) even at 50% missingness. Experimental results across different ancestries confirm consistent gains across datasets, with resilience to small sample sizes and weak LD. A 128-SNP (single-nucleotide polymorphism) context window (approximately 100 Kb) is validated through LD-decay analyses as sufficient to capture local correlation structures. By eliminating reference-panel dependence while preserving high accuracy, GenoBERT provides a scalable and robust solution for genotype imputation and a foundation for downstream genomic modeling.
SSR: Pushing the Limit of Spatial Intelligence with Structured Scene Reasoning
Feb 28, 2026While Multimodal Large Language Models (MLLMs) excel in semantic tasks, they frequently lack the "spatial sense" essential for sophisticated geometric reasoning. Current models typically suffer from exorbitant modality-alignment costs and deficiency in fine-grained structural modeling precision.We introduce SSR, a framework designed for Structured Scene Reasoning that seamlessly integrates 2D and 3D representations via a lightweight alignment mechanism. To minimize training overhead, our framework anchors 3D geometric features to the large language model's pre-aligned 2D visual semantics through cross-modal addition and token interleaving, effectively obviating the necessity for large-scale alignment pre-training. To underpin complex spatial reasoning, we propose a novel scene graph generation pipeline that represents global layouts as a chain of independent local triplets defined by relative coordinates. This is complemented by an incremental generation algorithm, enabling the model to construct "language-model-friendly" structural scaffolds for complex environments. Furthermore, we extend these capabilities to global-scale 3D global grounding task, achieving absolute metric precision across heterogeneous data sources. At a 7B parameter scale, SSR achieves state-of-the-art performance on multiple spatial intelligence benchmarks, notably scoring 73.9 on VSI-Bench. Our approach significantly outperforms much larger models, demonstrating that efficient feature alignment and structured scene reasoning are the cornerstones of authentic spatial intelligence.
Good Actions Succeed, Bad Actions Generalize: A Case Study on Why RL Generalizes Better
Mar 19, 2025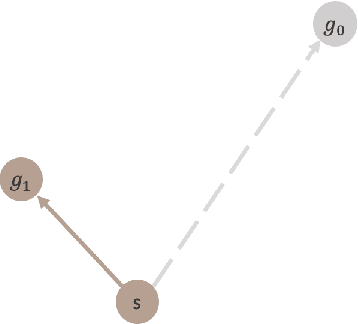
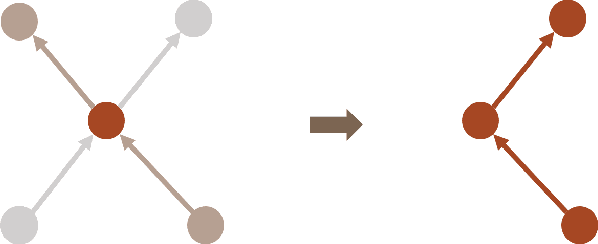
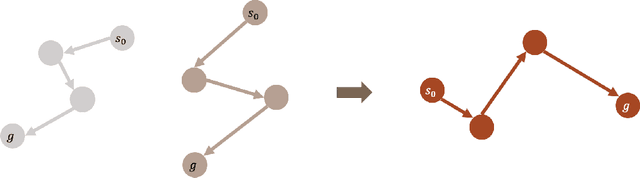
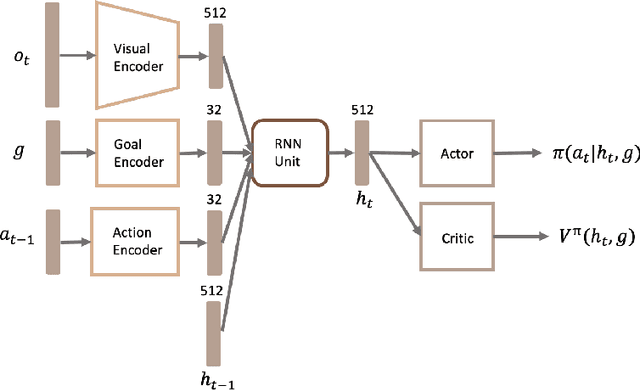
Supervised learning (SL) and reinforcement learning (RL) are both widely used to train general-purpose agents for complex tasks, yet their generalization capabilities and underlying mechanisms are not yet fully understood. In this paper, we provide a direct comparison between SL and RL in terms of zero-shot generalization. Using the Habitat visual navigation task as a testbed, we evaluate Proximal Policy Optimization (PPO) and Behavior Cloning (BC) agents across two levels of generalization: state-goal pair generalization within seen environments and generalization to unseen environments. Our experiments show that PPO consistently outperforms BC across both zero-shot settings and performance metrics-success rate and SPL. Interestingly, even though additional optimal training data enables BC to match PPO's zero-shot performance in SPL, it still falls significantly behind in success rate. We attribute this to a fundamental difference in how models trained by these algorithms generalize: BC-trained models generalize by imitating successful trajectories, whereas TD-based RL-trained models generalize through combinatorial experience stitching-leveraging fragments of past trajectories (mostly failed ones) to construct solutions for new tasks. This allows RL to efficiently find solutions in vast state space and discover novel strategies beyond the scope of human knowledge. Besides providing empirical evidence and understanding, we also propose practical guidelines for improving the generalization capabilities of RL and SL through algorithm design.
CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting
Sep 13, 2024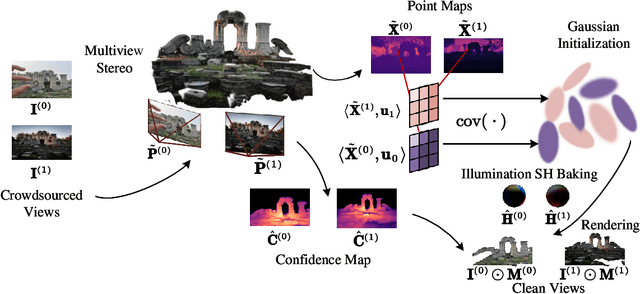

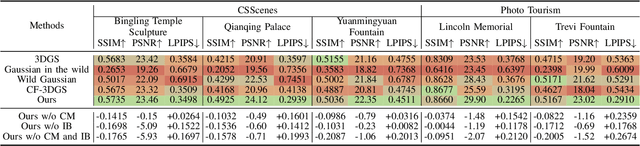
We introduce Crowd-Sourced Splatting (CSS), a novel 3D Gaussian Splatting (3DGS) pipeline designed to overcome the challenges of pose-free scene reconstruction using crowd-sourced imagery. The dream of reconstructing historically significant but inaccessible scenes from collections of photographs has long captivated researchers. However, traditional 3D techniques struggle with missing camera poses, limited viewpoints, and inconsistent lighting. CSS addresses these challenges through robust geometric priors and advanced illumination modeling, enabling high-quality novel view synthesis under complex, real-world conditions. Our method demonstrates clear improvements over existing approaches, paving the way for more accurate and flexible applications in AR, VR, and large-scale 3D reconstruction.
A Minimalist Prompt for Zero-Shot Policy Learning
May 09, 2024Transformer-based methods have exhibited significant generalization ability when prompted with target-domain demonstrations or example solutions during inference. Although demonstrations, as a way of task specification, can capture rich information that may be hard to specify by language, it remains unclear what information is extracted from the demonstrations to help generalization. Moreover, assuming access to demonstrations of an unseen task is impractical or unreasonable in many real-world scenarios, especially in robotics applications. These questions motivate us to explore what the minimally sufficient prompt could be to elicit the same level of generalization ability as the demonstrations. We study this problem in the contextural RL setting which allows for quantitative measurement of generalization and is commonly adopted by meta-RL and multi-task RL benchmarks. In this setting, the training and test Markov Decision Processes (MDPs) only differ in certain properties, which we refer to as task parameters. We show that conditioning a decision transformer on these task parameters alone can enable zero-shot generalization on par with or better than its demonstration-conditioned counterpart. This suggests that task parameters are essential for the generalization and DT models are trying to recover it from the demonstration prompt. To extract the remaining generalizable information from the supervision, we introduce an additional learnable prompt which is demonstrated to further boost zero-shot generalization across a range of robotic control, manipulation, and navigation benchmark tasks.
Probabilistic World Modeling with Asymmetric Distance Measure
Mar 16, 2024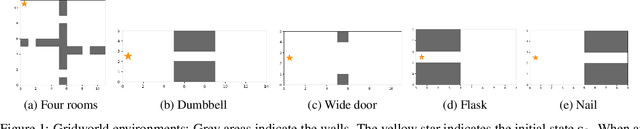
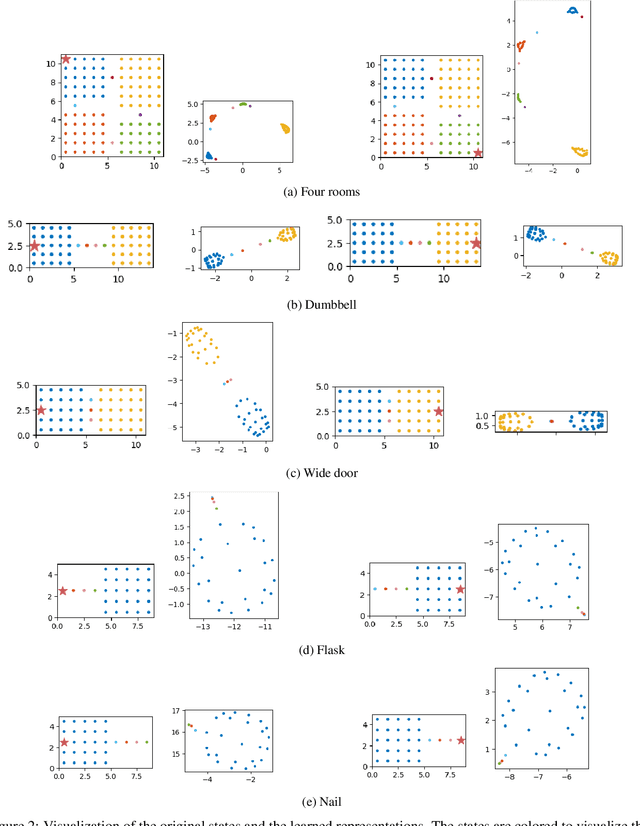
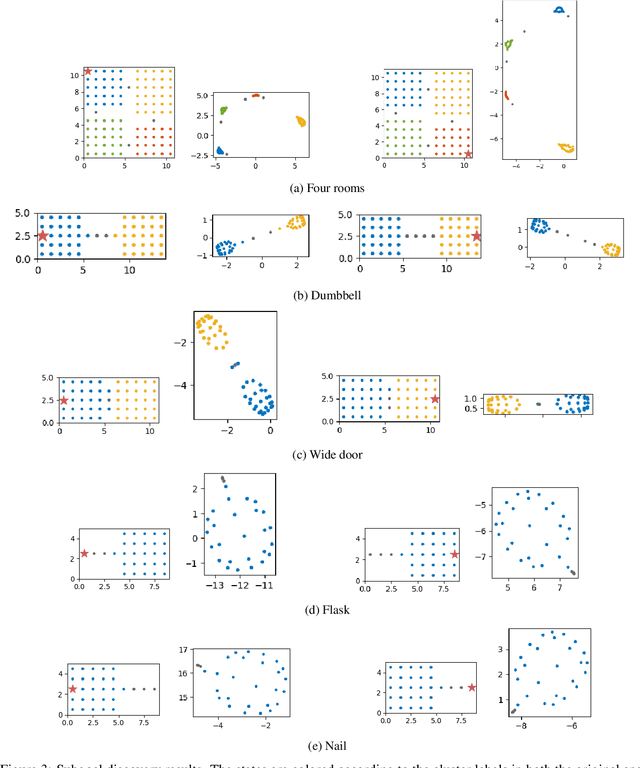
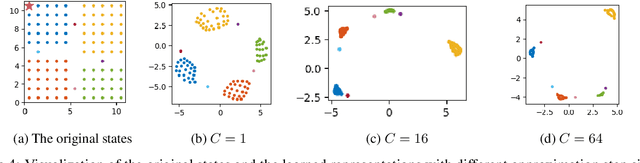
Representation learning is a fundamental task in machine learning, aiming at uncovering structures from data to facilitate subsequent tasks. However, what is a good representation for planning and reasoning in a stochastic world remains an open problem. In this work, we posit that learning a distance function is essential to allow planning and reasoning in the representation space. We show that a geometric abstraction of the probabilistic world dynamics can be embedded into the representation space through asymmetric contrastive learning. Unlike previous approaches that focus on learning mutual similarity or compatibility measures, we instead learn an asymmetric similarity function that reflects the state reachability and allows multi-way probabilistic inference. Moreover, by conditioning on a common reference state (e.g. the observer's current state), the learned representation space allows us to discover the geometrically salient states that only a handful of paths can lead through. These states can naturally serve as subgoals to break down long-horizon planning tasks. We evaluate our method in gridworld environments with various layouts and demonstrate its effectiveness in discovering the subgoals.
Learning to Rearrange with Physics-Inspired Risk Awareness
Jun 26, 2022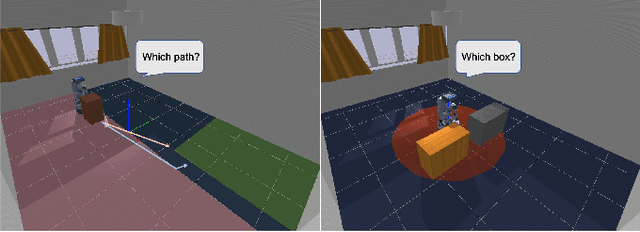
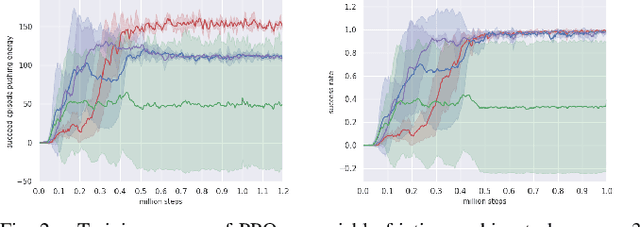
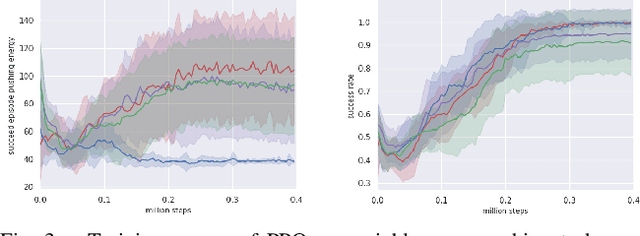
Real-world applications require a robot operating in the physical world with awareness of potential risks besides accomplishing the task. A large part of risky behaviors arises from interacting with objects in ignorance of affordance. To prevent the agent from making unsafe decisions, we propose to train a robotic agent by reinforcement learning to execute tasks with an awareness of physical properties such as mass and friction in an indoor environment. We achieve this through a novel physics-inspired reward function that encourages the agent to learn a policy discerning different masses and friction coefficients. We introduce two novel and challenging indoor rearrangement tasks -- the variable friction pushing task and the variable mass pushing task -- that allow evaluation of the learned policies in trading off performance and physics-inspired risk. Our results demonstrate that by equipping with the proposed reward, the agent is able to learn policies choosing the pushing targets or goal-reaching trajectories with minimum physical cost, which can be further utilized as a precaution to constrain the agent's behavior in a safety-critic environment.
RLPrompt: Optimizing Discrete Text Prompts With Reinforcement Learning
May 25, 2022



Prompting has shown impressive success in enabling large pretrained language models (LMs) to perform diverse NLP tasks, especially when only few downstream data are available. Automatically finding the optimal prompt for each task, however, is challenging. Most existing work resorts to tuning soft prompt (e.g., embeddings) which falls short of interpretability, reusability across LMs, and applicability when gradients are not accessible. Discrete prompt, on the other hand, is difficult to optimize, and is often created by "enumeration (e.g., paraphrasing)-then-selection" heuristics that do not explore the prompt space systematically. This paper proposes RLPrompt, an efficient discrete prompt optimization approach with reinforcement learning (RL). RLPrompt formulates a parameter-efficient policy network that generates the desired discrete prompt after training with reward. To overcome the complexity and stochasticity of reward signals by the large LM environment, we incorporate effective reward stabilization that substantially enhances the training efficiency. RLPrompt is flexibly applicable to different types of LMs, such as masked (e.g., BERT) and left-to-right models (e.g., GPTs), for both classification and generation tasks. Experiments on few-shot classification and unsupervised text style transfer show superior performance over a wide range of existing finetuning or prompting methods. Interestingly, the resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferrable between different LMs to retain significant performance, indicating LM prompting may not follow human language patterns.
S4G: Amodal Single-view Single-Shot SE Grasp Detection in Cluttered Scenes
Oct 31, 2019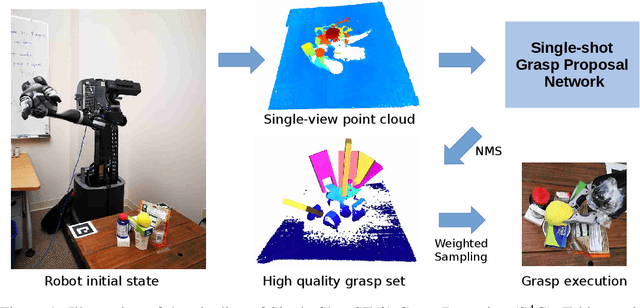
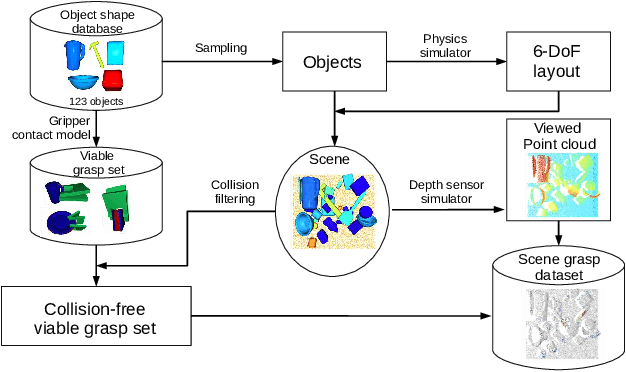
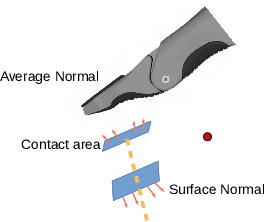
Grasping is among the most fundamental and long-lasting problems in robotics study. This paper studies the problem of 6-DoF(degree of freedom) grasping by a parallel gripper in a cluttered scene captured using a commodity depth sensor from a single viewpoint. We address the problem in a learning-based framework. At the high level, we rely on a single-shot grasp proposal network, trained with synthetic data and tested in real-world scenarios. Our single-shot neural network architecture can predict amodal grasp proposal efficiently and effectively. Our training data synthesis pipeline can generate scenes of complex object configuration and leverage an innovative gripper contact model to create dense and high-quality grasp annotations. Experiments in synthetic and real environments have demonstrated that the proposed approach can outperform state-of-the-arts by a large margin.