 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepEra: A Deep Evidence Reranking Agent for Scientific Retrieval-Augmented Generated Question Answering
Jan 23, 2026With the rapid growth of scientific literature, scientific question answering (SciQA) has become increasingly critical for exploring and utilizing scientific knowledge. Retrieval-Augmented Generation (RAG) enhances LLMs by incorporating knowledge from external sources, thereby providing credible evidence for scientific question answering. But existing retrieval and reranking methods remain vulnerable to passages that are semantically similar but logically irrelevant, often reducing factual reliability and amplifying hallucinations.To address this challenge, we propose a Deep Evidence Reranking Agent (DeepEra) that integrates step-by-step reasoning, enabling more precise evaluation of candidate passages beyond surface-level semantics. To support systematic evaluation, we construct SciRAG-SSLI (Scientific RAG - Semantically Similar but Logically Irrelevant), a large-scale dataset comprising about 300K SciQA instances across 10 subjects, constructed from 10M scientific corpus. The dataset combines naturally retrieved contexts with systematically generated distractors to test logical robustness and factual grounding. Comprehensive evaluations confirm that our approach achieves superior retrieval performance compared to leading rerankers. To our knowledge, this work is the first to comprehensively study and empirically validate innegligible SSLI issues in two-stage RAG frameworks.
ScienceDB AI: An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
Jan 03, 2026The rapid growth of AI for Science (AI4S) has underscored the significance of scientific datasets, leading to the establishment of numerous national scientific data centers and sharing platforms. Despite this progress, efficiently promoting dataset sharing and utilization for scientific research remains challenging. Scientific datasets contain intricate domain-specific knowledge and contexts, rendering traditional collaborative filtering-based recommenders inadequate. Recent advances in Large Language Models (LLMs) offer unprecedented opportunities to build conversational agents capable of deep semantic understanding and personalized recommendations. In response, we present ScienceDB AI, a novel LLM-driven agentic recommender system developed on Science Data Bank (ScienceDB), one of the largest global scientific data-sharing platforms. ScienceDB AI leverages natural language conversations and deep reasoning to accurately recommend datasets aligned with researchers' scientific intents and evolving requirements. The system introduces several innovations: a Scientific Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using over 10 million real-world datasets, ScienceDB AI has demonstrated significant effectiveness. To our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services. The platform is publicly accessible at: https://ai.scidb.cn/en.
Quantifying the advantage of vector over scalar magnetic sensor networks for undersea surveillance
Dec 30, 2025Magnetic monitoring of maritime environments is an important problem for monitoring and optimising shipping, as well as national security. New developments in compact, fibre-coupled quantum magnetometers have led to the opportunity to critically evaluate how best to create such a sensor network. Here we explore various magnetic sensor network architectures for target identification. Our modelling compares networks of scalar vs vector magnetometers. We implement an unscented Kalman filter approach to perform target tracking, and we find that vector networks provide a significant improvement in target tracking, specifically tracking accuracy and resilience compared with scalar networks.
SciRerankBench: Benchmarking Rerankers Towards Scientific Retrieval-Augmented Generated LLMs
Aug 12, 2025Scientific literature question answering is a pivotal step towards new scientific discoveries. Recently, \textit{two-stage} retrieval-augmented generated large language models (RAG-LLMs) have shown impressive advancements in this domain. Such a two-stage framework, especially the second stage (reranker), is particularly essential in the scientific domain, where subtle differences in terminology may have a greatly negative impact on the final factual-oriented or knowledge-intensive answers. Despite this significant progress, the potential and limitations of these works remain unexplored. In this work, we present a Scientific Rerank-oriented RAG Benchmark (SciRerankBench), for evaluating rerankers within RAG-LLMs systems, spanning five scientific subjects. To rigorously assess the reranker performance in terms of noise resilience, relevance disambiguation, and factual consistency, we develop three types of question-context-answer (Q-C-A) pairs, i.e., Noisy Contexts (NC), Semantically Similar but Logically Irrelevant Contexts (SSLI), and Counterfactual Contexts (CC). Through systematic evaluation of 13 widely used rerankers on five families of LLMs, we provide detailed insights into their relative strengths and limitations. To the best of our knowledge, SciRerankBench is the first benchmark specifically developed to evaluate rerankers within RAG-LLMs, which provides valuable observations and guidance for their future development.
Comprehensive Metapath-based Heterogeneous Graph Transformer for Gene-Disease Association Prediction
Jan 14, 2025



Discovering gene-disease associations is crucial for understanding disease mechanisms, yet identifying these associations remains challenging due to the time and cost of biological experiments. Computational methods are increasingly vital for efficient and scalable gene-disease association prediction. Graph-based learning models, which leverage node features and network relationships, are commonly employed for biomolecular predictions. However, existing methods often struggle to effectively integrate node features, heterogeneous structures, and semantic information. To address these challenges, we propose COmprehensive MEtapath-based heterogeneous graph Transformer(COMET) for predicting gene-disease associations. COMET integrates diverse datasets to construct comprehensive heterogeneous networks, initializing node features with BioGPT. We define seven Metapaths and utilize a transformer framework to aggregate Metapath instances, capturing global contexts and long-distance dependencies. Through intra- and inter-metapath aggregation using attention mechanisms, COMET fuses latent vectors from multiple Metapaths to enhance GDA prediction accuracy. Our method demonstrates superior robustness compared to state-of-the-art approaches. Ablation studies and visualizations validate COMET's effectiveness, providing valuable insights for advancing human health research.
GeneSUM: Large Language Model-based Gene Summary Extraction
Dec 24, 2024Emerging topics in biomedical research are continuously expanding, providing a wealth of information about genes and their function. This rapid proliferation of knowledge presents unprecedented opportunities for scientific discovery and formidable challenges for researchers striving to keep abreast of the latest advancements. One significant challenge is navigating the vast corpus of literature to extract vital gene-related information, a time-consuming and cumbersome task. To enhance the efficiency of this process, it is crucial to address several key challenges: (1) the overwhelming volume of literature, (2) the complexity of gene functions, and (3) the automated integration and generation. In response, we propose GeneSUM, a two-stage automated gene summary extractor utilizing a large language model (LLM). Our approach retrieves and eliminates redundancy of target gene literature and then fine-tunes the LLM to refine and streamline the summarization process. We conducted extensive experiments to validate the efficacy of our proposed framework. The results demonstrate that LLM significantly enhances the integration of gene-specific information, allowing more efficient decision-making in ongoing research.
BioRAG: A RAG-LLM Framework for Biological Question Reasoning
Aug 02, 2024



The question-answering system for Life science research, which is characterized by the rapid pace of discovery, evolving insights, and complex interactions among knowledge entities, presents unique challenges in maintaining a comprehensive knowledge warehouse and accurate information retrieval. To address these issues, we introduce BioRAG, a novel Retrieval-Augmented Generation (RAG) with the Large Language Models (LLMs) framework. Our approach starts with parsing, indexing, and segmenting an extensive collection of 22 million scientific papers as the basic knowledge, followed by training a specialized embedding model tailored to this domain. Additionally, we enhance the vector retrieval process by incorporating a domain-specific knowledge hierarchy, which aids in modeling the intricate interrelationships among each query and context. For queries requiring the most current information, BioRAG deconstructs the question and employs an iterative retrieval process incorporated with the search engine for step-by-step reasoning. Rigorous experiments have demonstrated that our model outperforms fine-tuned LLM, LLM with search engines, and other scientific RAG frameworks across multiple life science question-answering tasks.
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Jun 26, 2024
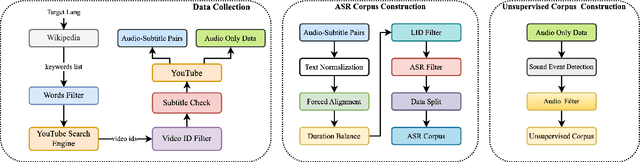


Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
A Minimalist Prompt for Zero-Shot Policy Learning
May 09, 2024Transformer-based methods have exhibited significant generalization ability when prompted with target-domain demonstrations or example solutions during inference. Although demonstrations, as a way of task specification, can capture rich information that may be hard to specify by language, it remains unclear what information is extracted from the demonstrations to help generalization. Moreover, assuming access to demonstrations of an unseen task is impractical or unreasonable in many real-world scenarios, especially in robotics applications. These questions motivate us to explore what the minimally sufficient prompt could be to elicit the same level of generalization ability as the demonstrations. We study this problem in the contextural RL setting which allows for quantitative measurement of generalization and is commonly adopted by meta-RL and multi-task RL benchmarks. In this setting, the training and test Markov Decision Processes (MDPs) only differ in certain properties, which we refer to as task parameters. We show that conditioning a decision transformer on these task parameters alone can enable zero-shot generalization on par with or better than its demonstration-conditioned counterpart. This suggests that task parameters are essential for the generalization and DT models are trying to recover it from the demonstration prompt. To extract the remaining generalizable information from the supervision, we introduce an additional learnable prompt which is demonstrated to further boost zero-shot generalization across a range of robotic control, manipulation, and navigation benchmark tasks.
COMAE: COMprehensive Attribute Exploration for Zero-shot Hashing
Feb 26, 2024



Zero-shot hashing (ZSH) has shown excellent success owing to its efficiency and generalization in large-scale retrieval scenarios. While considerable success has been achieved, there still exist urgent limitations. Existing works ignore the locality relationships of representations and attributes, which have effective transferability between seeable classes and unseeable classes. Also, the continuous-value attributes are not fully harnessed. In response, we conduct a COMprehensive Attribute Exploration for ZSH, named COMAE, which depicts the relationships from seen classes to unseen ones through three meticulously designed explorations, i.e., point-wise, pair-wise and class-wise consistency constraints. By regressing attributes from the proposed attribute prototype network, COMAE learns the local features that are relevant to the visual attributes. Then COMAE utilizes contrastive learning to comprehensively depict the context of attributes, rather than instance-independent optimization. Finally, the class-wise constraint is designed to cohesively learn the hash code, image representation, and visual attributes more effectively. Experimental results on the popular ZSH datasets demonstrate that COMAE outperforms state-of-the-art hashing techniques, especially in scenarios with a larger number of unseen label classes.