 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Iterative Temporal Reasoning with Time Puzzles
Jan 13, 2026We introduce Time Puzzles, a constraint-based date inference task for evaluating iterative temporal reasoning. Each puzzle combines factual temporal anchors with (cross-cultural) calendar relations, admits one or multiple valid solution dates, and is algorithmically generated for controlled, dynamic, and continual evaluation. Across 13 diverse LLMs, Time Puzzles well distinguishes their iterative temporal reasoning capabilities and remains challenging without tools: GPT-5 reaches only 49.3% accuracy and all other models stay below 31%, despite the dataset's simplicity. Web search consistently yields substantial gains and using code interpreter shows mixed effects, but all models perform much better when constraints are rewritten with explicit dates, revealing a gap in reliable tool use. Overall, Time Puzzles presents a simple, cost-effective diagnostic for tool-augmented iterative temporal reasoning.
FROST-Drive: Scalable and Efficient End-to-End Driving with a Frozen Vision Encoder
Jan 06, 2026End-to-end (E2E) models in autonomous driving aim to directly map sensor inputs to control commands, but their ability to generalize to novel and complex scenarios remains a key challenge. The common practice of fully fine-tuning the vision encoder on driving datasets potentially limits its generalization by causing the model to specialize too heavily in the training data. This work challenges the necessity of this training paradigm. We propose FROST-Drive, a novel E2E architecture designed to preserve and leverage the powerful generalization capabilities of a pretrained vision encoder from a Vision-Language Model (VLM). By keeping the encoder's weights frozen, our approach directly transfers the rich, generalized world knowledge from the VLM to the driving task. Our model architecture combines this frozen encoder with a transformer-based adapter for multimodal fusion and a GRU-based decoder for smooth waypoint generation. Furthermore, we introduce a custom loss function designed to directly optimize for Rater Feedback Score (RFS), a metric that prioritizes robust trajectory planning. We conduct extensive experiments on Waymo Open E2E Dataset, a large-scale datasets deliberately curated to capture the long-tail scenarios, demonstrating that our frozen-encoder approach significantly outperforms models that employ full fine-tuning. Our results provide substantial evidence that preserving the broad knowledge of a capable VLM is a more effective strategy for achieving robust, generalizable driving performance than intensive domain-specific adaptation. This offers a new pathway for developing vision-based models that can better handle the complexities of real-world application domains.
SepPrune: Structured Pruning for Efficient Deep Speech Separation
May 17, 2025Although deep learning has substantially advanced speech separation in recent years, most existing studies continue to prioritize separation quality while overlooking computational efficiency, an essential factor for low-latency speech processing in real-time applications. In this paper, we propose SepPrune, the first structured pruning framework specifically designed to compress deep speech separation models and reduce their computational cost. SepPrune begins by analyzing the computational structure of a given model to identify layers with the highest computational burden. It then introduces a differentiable masking strategy to enable gradient-driven channel selection. Based on the learned masks, SepPrune prunes redundant channels and fine-tunes the remaining parameters to recover performance. Extensive experiments demonstrate that this learnable pruning paradigm yields substantial advantages for channel pruning in speech separation models, outperforming existing methods. Notably, a model pruned with SepPrune can recover 85% of the performance of a pre-trained model (trained over hundreds of epochs) with only one epoch of fine-tuning, and achieves convergence 36$\times$ faster than training from scratch. Code is available at https://github.com/itsnotacie/SepPrune.
Learning to Help in Multi-Class Settings
Jan 23, 2025



Deploying complex machine learning models on resource-constrained devices is challenging due to limited computational power, memory, and model retrainability. To address these limitations, a hybrid system can be established by augmenting the local model with a server-side model, where samples are selectively deferred by a rejector and then sent to the server for processing. The hybrid system enables efficient use of computational resources while minimizing the overhead associated with server usage. The recently proposed Learning to Help (L2H) model trains a server model given a fixed local (client) model, differing from the Learning to Defer (L2D) framework, which trains the client for a fixed (expert) server. In both L2D and L2H, the training includes learning a rejector at the client to determine when to query the server. In this work, we extend the L2H model from binary to multi-class classification problems and demonstrate its applicability in a number of different scenarios of practical interest in which access to the server may be limited by cost, availability, or policy. We derive a stage-switching surrogate loss function that is differentiable, convex, and consistent with the Bayes rule corresponding to the 0-1 loss for the L2H model. Experiments show that our proposed methods offer an efficient and practical solution for multi-class classification in resource-constrained environments.
Generalizing End-To-End Autonomous Driving In Real-World Environments Using Zero-Shot LLMs
Nov 21, 2024



Traditional autonomous driving methods adopt a modular design, decomposing tasks into sub-tasks. In contrast, end-to-end autonomous driving directly outputs actions from raw sensor data, avoiding error accumulation. However, training an end-to-end model requires a comprehensive dataset; otherwise, the model exhibits poor generalization capabilities. Recently, large language models (LLMs) have been applied to enhance the generalization capabilities of end-to-end driving models. Most studies explore LLMs in an open-loop manner, where the output actions are compared to those of experts without direct feedback from the real world, while others examine closed-loop results only in simulations. This paper proposes an efficient architecture that integrates multimodal LLMs into end-to-end driving models operating in closed-loop settings in real-world environments. In our architecture, the LLM periodically processes raw sensor data to generate high-level driving instructions, effectively guiding the end-to-end model, even at a slower rate than the raw sensor data. This architecture relaxes the trade-off between the latency and inference quality of the LLM. It also allows us to choose from a wide variety of LLMs to improve high-level driving instructions and minimize fine-tuning costs. Consequently, our architecture reduces data collection requirements because the LLMs do not directly output actions; we only need to train a simple imitation learning model to output actions. In our experiments, the training data for the end-to-end model in a real-world environment consists of only simple obstacle configurations with one traffic cone, while the test environment is more complex and contains multiple obstacles placed in various positions. Experiments show that the proposed architecture enhances the generalization capabilities of the end-to-end model even without fine-tuning the LLM.
EAPCR: A Universal Feature Extractor for Scientific Data without Explicit Feature Relation Patterns
Nov 12, 2024



Conventional methods, including Decision Tree (DT)-based methods, have been effective in scientific tasks, such as non-image medical diagnostics, system anomaly detection, and inorganic catalysis efficiency prediction. However, most deep-learning techniques have struggled to surpass or even match this level of success as traditional machine-learning methods. The primary reason is that these applications involve multi-source, heterogeneous data where features lack explicit relationships. This contrasts with image data, where pixels exhibit spatial relationships; textual data, where words have sequential dependencies; and graph data, where nodes are connected through established associations. The absence of explicit Feature Relation Patterns (FRPs) presents a significant challenge for deep learning techniques in scientific applications that are not image, text, and graph-based. In this paper, we introduce EAPCR, a universal feature extractor designed for data without explicit FRPs. Tested across various scientific tasks, EAPCR consistently outperforms traditional methods and bridges the gap where deep learning models fall short. To further demonstrate its robustness, we synthesize a dataset without explicit FRPs. While Kolmogorov-Arnold Network (KAN) and feature extractors like Convolutional Neural Networks (CNNs), Graph Convolutional Networks (GCNs), and Transformers struggle, EAPCR excels, demonstrating its robustness and superior performance in scientific tasks without FRPs.
When to Trust Your Data: Enhancing Dyna-Style Model-Based Reinforcement Learning With Data Filter
Oct 16, 2024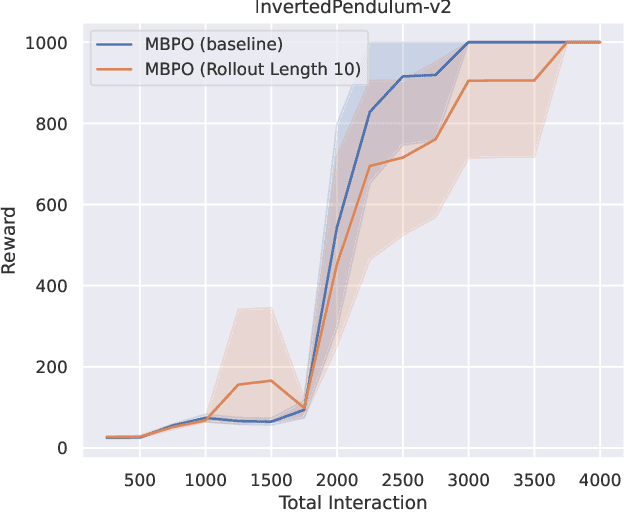

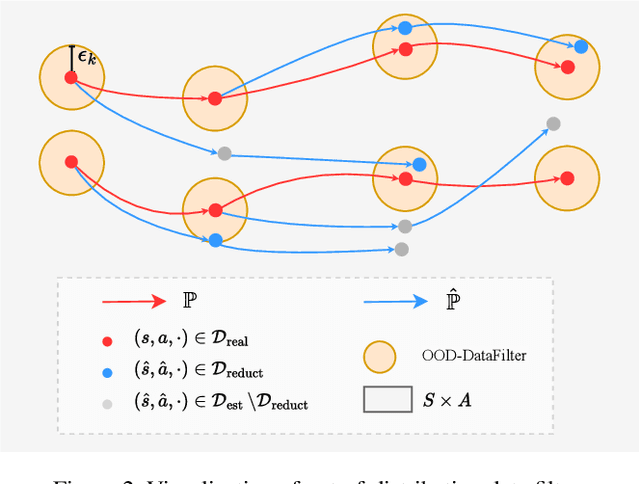
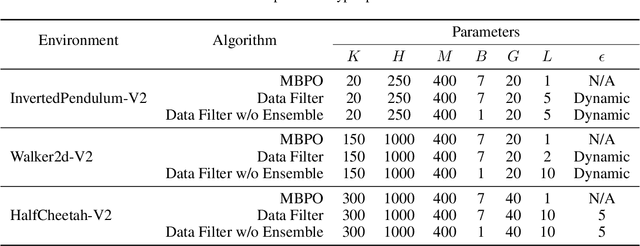
Reinforcement learning (RL) algorithms can be divided into two classes: model-free algorithms, which are sample-inefficient, and model-based algorithms, which suffer from model bias. Dyna-style algorithms combine these two approaches by using simulated data from an estimated environmental model to accelerate model-free training. However, their efficiency is compromised when the estimated model is inaccurate. Previous works address this issue by using model ensembles or pretraining the estimated model with data collected from the real environment, increasing computational and sample complexity. To tackle this issue, we introduce an out-of-distribution (OOD) data filter that removes simulated data from the estimated model that significantly diverges from data collected in the real environment. We show theoretically that this technique enhances the quality of simulated data. With the help of the OOD data filter, the data simulated from the estimated model better mimics the data collected by interacting with the real model. This improvement is evident in the critic updates compared to using the simulated data without the OOD data filter. Our experiment integrates the data filter into the model-based policy optimization (MBPO) algorithm. The results demonstrate that our method requires fewer interactions with the real environment to achieve a higher level of optimality than MBPO, even without a model ensemble.
SGLP: A Similarity Guided Fast Layer Partition Pruning for Compressing Large Deep Models
Oct 14, 2024



The deployment of Deep Neural Network (DNN)-based networks on resource-constrained devices remains a significant challenge due to their high computational and parameter requirements. To solve this problem, layer pruning has emerged as a potent approach to reduce network size and improve computational efficiency. However, existing layer pruning methods mostly overlook the intrinsic connections and inter-dependencies between different layers within complicated deep neural networks. This oversight can result in pruned models that do not preserve the essential characteristics of the pre-trained network as effectively as desired. To address this limitations, we propose a Similarity Guided fast Layer Partition pruning for compressing large deep models (SGLP), which focuses on pruning layers from network segments partitioned via representation similarity. Specifically, our presented method first leverages Centered Kernel Alignment (CKA) to indicate the internal representations among the layers of the pre-trained network, which provides us with a potent basis for layer pruning. Based on similarity matrix derived from CKA, we employ Fisher Optimal Segmentation to partition the network into multiple segments, which provides a basis for removing the layers in a segment-wise manner. In addition, our method innovatively adopts GradNorm for segment-wise layer importance evaluation, eliminating the need for extensive fine-tuning, and finally prunes the unimportant layers to obtain a compact network. Experimental results in image classification and for large language models (LLMs) demonstrate that our proposed SGLP outperforms the state-of-the-art methods in both accuracy and computational efficiency, presenting a more effective solution for deploying DNNs on resource-limited platforms. Our codes are available at https://github.com/itsnotacie/information-fusion-SGLP.
Prototype-Driven Multi-Feature Generation for Visible-Infrared Person Re-identification
Sep 09, 2024



The primary challenges in visible-infrared person re-identification arise from the differences between visible (vis) and infrared (ir) images, including inter-modal and intra-modal variations. These challenges are further complicated by varying viewpoints and irregular movements. Existing methods often rely on horizontal partitioning to align part-level features, which can introduce inaccuracies and have limited effectiveness in reducing modality discrepancies. In this paper, we propose a novel Prototype-Driven Multi-feature generation framework (PDM) aimed at mitigating cross-modal discrepancies by constructing diversified features and mining latent semantically similar features for modal alignment. PDM comprises two key components: Multi-Feature Generation Module (MFGM) and Prototype Learning Module (PLM). The MFGM generates diversity features closely distributed from modality-shared features to represent pedestrians. Additionally, the PLM utilizes learnable prototypes to excavate latent semantic similarities among local features between visible and infrared modalities, thereby facilitating cross-modal instance-level alignment. We introduce the cosine heterogeneity loss to enhance prototype diversity for extracting rich local features. Extensive experiments conducted on the SYSU-MM01 and LLCM datasets demonstrate that our approach achieves state-of-the-art performance. Our codes are available at https://github.com/mmunhappy/ICASSP2025-PDM.
KnobTree: Intelligent Database Parameter Configuration via Explainable Reinforcement Learning
Jun 21, 2024Databases are fundamental to contemporary information systems, yet traditional rule-based configuration methods struggle to manage the complexity of real-world applications with hundreds of tunable parameters. Deep reinforcement learning (DRL), which combines perception and decision-making, presents a potential solution for intelligent database configuration tuning. However, due to black-box property of RL-based method, the generated database tuning strategies still face the urgent problem of lack explainability. Besides, the redundant parameters in large scale database always make the strategy learning become unstable. This paper proposes KnobTree, an interpertable framework designed for the optimization of database parameter configuration. In this framework, an interpertable database tuning algorithm based on RL-based differentatial tree is proposed, which building a transparent tree-based model to generate explainable database tuning strategies. To address the problem of large-scale parameters, We also introduce a explainable method for parameter importance assessment, by utilizing Shapley Values to identify parameters that have significant impacts on database performance. Experiments conducted on MySQL and Gbase8s databases have verified exceptional transparency and interpretability of the KnobTree model. The good property makes generated strategies can offer practical guidance to algorithm designers and database administrators. Moreover, our approach also slightly outperforms the existing RL-based tuning algorithms in aspects such as throughput, latency, and processing time.