 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaitProtector: Impersonation-Driven Gait De-Identification via Training-Free Diffusion Latent Optimization
May 12, 2026Conventional gait de-identification methods often encounter an inherent trade-off: they either provide insufficient identity suppression or introduce spatiotemporal distortions that impede structure-sensitive downstream applications. We propose GaitProtector, an impersonation-driven gait de-identification framework that formulates privacy protection as a unified objective with two tightly coupled components: (i) obfuscation, which repels the protected gait from the source identity, and (ii) impersonation, which attracts it toward a selected target identity. The target identity serves as a semantic anchor that biases optimization toward structurally plausible gait patterns under the pretrained diffusion prior, helping preserve dominant body shape and motion dynamics. We instantiate this idea through a training-free diffusion latent optimization pipeline. Instead of retraining a generator for each dataset, we invert each input silhouette sequence into the latent trajectory of a pretrained 3D video diffusion model and iteratively optimize latent codes with a differentiable adversarial objective to synthesize protected gaits. Experiments on the CASIA-B dataset show that GaitProtector achieves a 56.7% impersonation success rate under black-box gait recognition and reduces Rank-1 identification accuracy from 89.6% to 15.0%, while maintaining favorable visual and temporal quality. We further evaluate downstream utility on the Scoliosis1K dataset, where diagnostic accuracy decreases only from 91.4% to 74.2%. To the best of our knowledge, this work is the first to leverage pretrained 3D diffusion priors in a training-free manner for silhouette-based gait de-identification.
RoboAlign-R1: Distilled Multimodal Reward Alignment for Robot Video World Models
May 05, 2026Existing robot video world models are typically trained with low-level objectives such as reconstruction and perceptual similarity, which are poorly aligned with the capabilities that matter most for robot decision making, including instruction following, manipulation success, and physical plausibility. They also suffer from error accumulation in long-horizon autoregressive prediction. We present RoboAlign-R1, a framework that combines reward-aligned post-training with stabilized long-horizon inference for robot video world models. We construct RobotWorldBench, a benchmark of 10,000 annotated video-instruction pairs collected from four robot data sources, and train a multimodal teacher judge, RoboAlign-Judge, to provide fine-grained six-dimensional evaluation of generated videos. We then distill the teacher into a lightweight student reward model for efficient reinforcement-learning-based post-training. To reduce long-horizon rollout drift, we further introduce Sliding Window Re-encoding (SWR), a training-free inference strategy that periodically refreshes the generation context. Under our in-domain evaluation protocol, RoboAlign-R1 improves the aggregate six-dimension score by 10.1% over the strongest baseline, including gains of 7.5% on Manipulation Accuracy and 4.6% on Instruction Following; these ranking improvements are further supported by an external VLM-based cross-check and a blinded human study. Meanwhile, SWR improves long-horizon prediction quality with only about 1% additional latency, yielding a 2.8% gain in SSIM and a 9.8% reduction in LPIPS. Together, these results show that reward-aligned post-training and stabilized long-horizon decoding improve task consistency, physical realism, and long-horizon prediction quality in robot video world models.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
Distilling Time Series Foundation Models for Efficient Forecasting
Jan 19, 2026Time Series foundation models (TSFMs) deliver strong forecasting performance through large-scale pretraining, but their large parameter sizes make deployment costly. While knowledge distillation offers a natural and effective approach for model compression, techniques developed for general machine learning tasks are not directly applicable to time series forecasting due to the unique characteristics. To address this, we present DistilTS, the first distillation framework specifically designed for TSFMs. DistilTS addresses two key challenges: (1) task difficulty discrepancy, specific to forecasting, where uniform weighting makes optimization dominated by easier short-term horizons, while long-term horizons receive weaker supervision; and (2) architecture discrepancy, a general challenge in distillation, for which we design an alignment mechanism in the time series forecasting. To overcome these issues, DistilTS introduces horizon-weighted objectives to balance learning across horizons, and a temporal alignment strategy that reduces architectural mismatch, enabling compact models. Experiments on multiple benchmarks demonstrate that DistilTS achieves forecasting performance comparable to full-sized TSFMs, while reducing parameters by up to 1/150 and accelerating inference by up to 6000x. Code is available at: https://github.com/itsnotacie/DistilTS-ICASSP2026.
SepPrune: Structured Pruning for Efficient Deep Speech Separation
May 17, 2025Although deep learning has substantially advanced speech separation in recent years, most existing studies continue to prioritize separation quality while overlooking computational efficiency, an essential factor for low-latency speech processing in real-time applications. In this paper, we propose SepPrune, the first structured pruning framework specifically designed to compress deep speech separation models and reduce their computational cost. SepPrune begins by analyzing the computational structure of a given model to identify layers with the highest computational burden. It then introduces a differentiable masking strategy to enable gradient-driven channel selection. Based on the learned masks, SepPrune prunes redundant channels and fine-tunes the remaining parameters to recover performance. Extensive experiments demonstrate that this learnable pruning paradigm yields substantial advantages for channel pruning in speech separation models, outperforming existing methods. Notably, a model pruned with SepPrune can recover 85% of the performance of a pre-trained model (trained over hundreds of epochs) with only one epoch of fine-tuning, and achieves convergence 36$\times$ faster than training from scratch. Code is available at https://github.com/itsnotacie/SepPrune.
Enhancing Facial Privacy Protection via Weakening Diffusion Purification
Mar 13, 2025The rapid growth of social media has led to the widespread sharing of individual portrait images, which pose serious privacy risks due to the capabilities of automatic face recognition (AFR) systems for mass surveillance. Hence, protecting facial privacy against unauthorized AFR systems is essential. Inspired by the generation capability of the emerging diffusion models, recent methods employ diffusion models to generate adversarial face images for privacy protection. However, they suffer from the diffusion purification effect, leading to a low protection success rate (PSR). In this paper, we first propose learning unconditional embeddings to increase the learning capacity for adversarial modifications and then use them to guide the modification of the adversarial latent code to weaken the diffusion purification effect. Moreover, we integrate an identity-preserving structure to maintain structural consistency between the original and generated images, allowing human observers to recognize the generated image as having the same identity as the original. Extensive experiments conducted on two public datasets, i.e., CelebA-HQ and LADN, demonstrate the superiority of our approach. The protected faces generated by our method outperform those produced by existing facial privacy protection approaches in terms of transferability and natural appearance.
ADM-Loc: Actionness Distribution Modeling for Point-supervised Temporal Action Localization
Nov 27, 2023



This paper addresses the challenge of point-supervised temporal action detection, in which only one frame per action instance is annotated in the training set. Self-training aims to provide supplementary supervision for the training process by generating pseudo-labels (action proposals) from a base model. However, most current methods generate action proposals by applying manually designed thresholds to action classification probabilities and treating adjacent snippets as independent entities. As a result, these methods struggle to generate complete action proposals, exhibit sensitivity to fluctuations in action classification scores, and generate redundant and overlapping action proposals. This paper proposes a novel framework termed ADM-Loc, which stands for Actionness Distribution Modeling for point-supervised action Localization. ADM-Loc generates action proposals by fitting a composite distribution, comprising both Gaussian and uniform distributions, to the action classification signals. This fitting process is tailored to each action class present in the video and is applied separately for each action instance, ensuring the distinctiveness of their distributions. ADM-Loc significantly enhances the alignment between the generated action proposals and ground-truth action instances and offers high-quality pseudo-labels for self-training. Moreover, to model action boundary snippets, it enforces consistency in action classification scores during training by employing Gaussian kernels, supervised with the proposed loss functions. ADM-Loc outperforms the state-of-the-art point-supervised methods on THUMOS14 and ActivityNet-v1.2 datasets.
POTLoc: Pseudo-Label Oriented Transformer for Point-Supervised Temporal Action Localization
Oct 20, 2023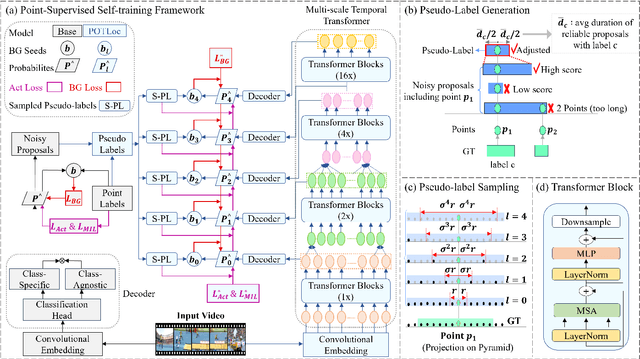
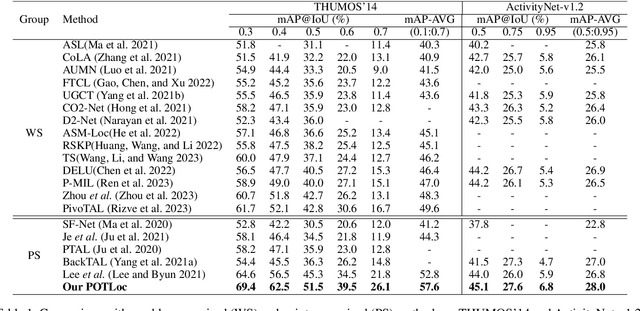
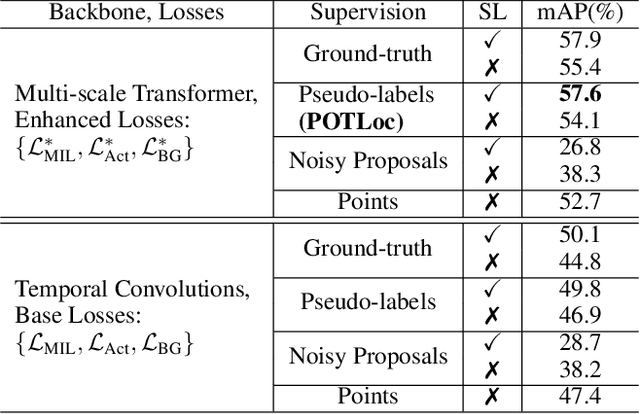
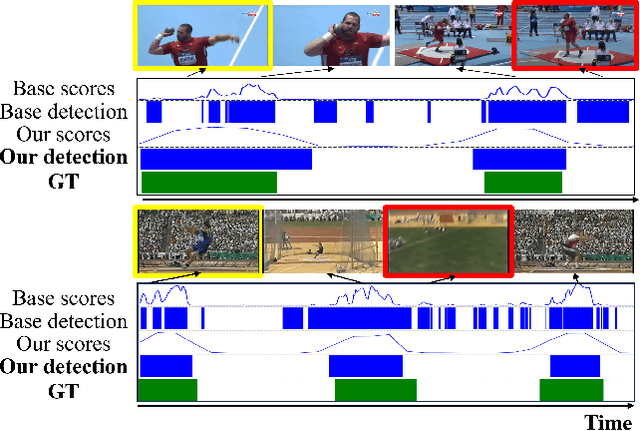
This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a Pseudo-label Oriented Transformer for weakly-supervised Action Localization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of `pseudo-labels' to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS'14 and ActivityNet-v1.2 datasets, showing a significant improvement of 5% average mAP on the former.
ASL-Homework-RGBD Dataset: An annotated dataset of 45 fluent and non-fluent signers performing American Sign Language homeworks
Jul 08, 2022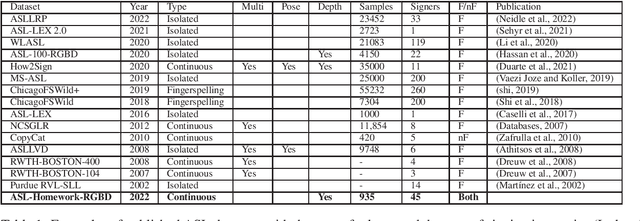
We are releasing a dataset containing videos of both fluent and non-fluent signers using American Sign Language (ASL), which were collected using a Kinect v2 sensor. This dataset was collected as a part of a project to develop and evaluate computer vision algorithms to support new technologies for automatic detection of ASL fluency attributes. A total of 45 fluent and non-fluent participants were asked to perform signing homework assignments that are similar to the assignments used in introductory or intermediate level ASL courses. The data is annotated to identify several aspects of signing including grammatical features and non-manual markers. Sign language recognition is currently very data-driven and this dataset can support the design of recognition technologies, especially technologies that can benefit ASL learners. This dataset might also be interesting to ASL education researchers who want to contrast fluent and non-fluent signing.
Sequential Point Clouds: A Survey
Apr 21, 2022
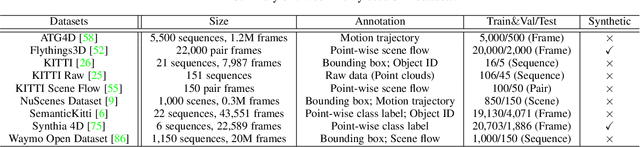
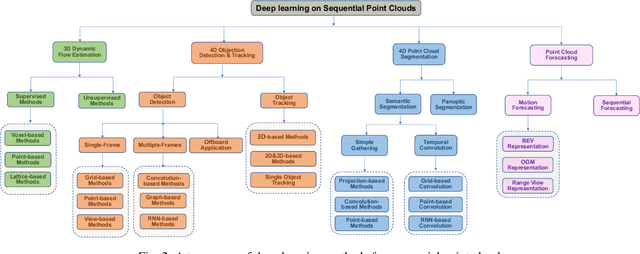
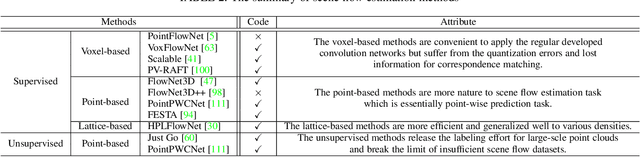
Point cloud has drawn more and more research attention as well as real-world applications. However, many of these applications (e.g. autonomous driving and robotic manipulation) are actually based on sequential point clouds (i.e. four dimensions) because the information of the static point cloud data could provide is still limited. Recently, researchers put more and more effort into sequential point clouds. This paper presents an extensive review of the deep learning-based methods for sequential point cloud research including dynamic flow estimation, object detection \& tracking, point cloud segmentation, and point cloud forecasting. This paper further summarizes and compares the quantitative results of the reviewed methods over the public benchmark datasets. Finally, this paper is concluded by discussing the challenges in the current sequential point cloud research and pointing out insightful potential future research directions.